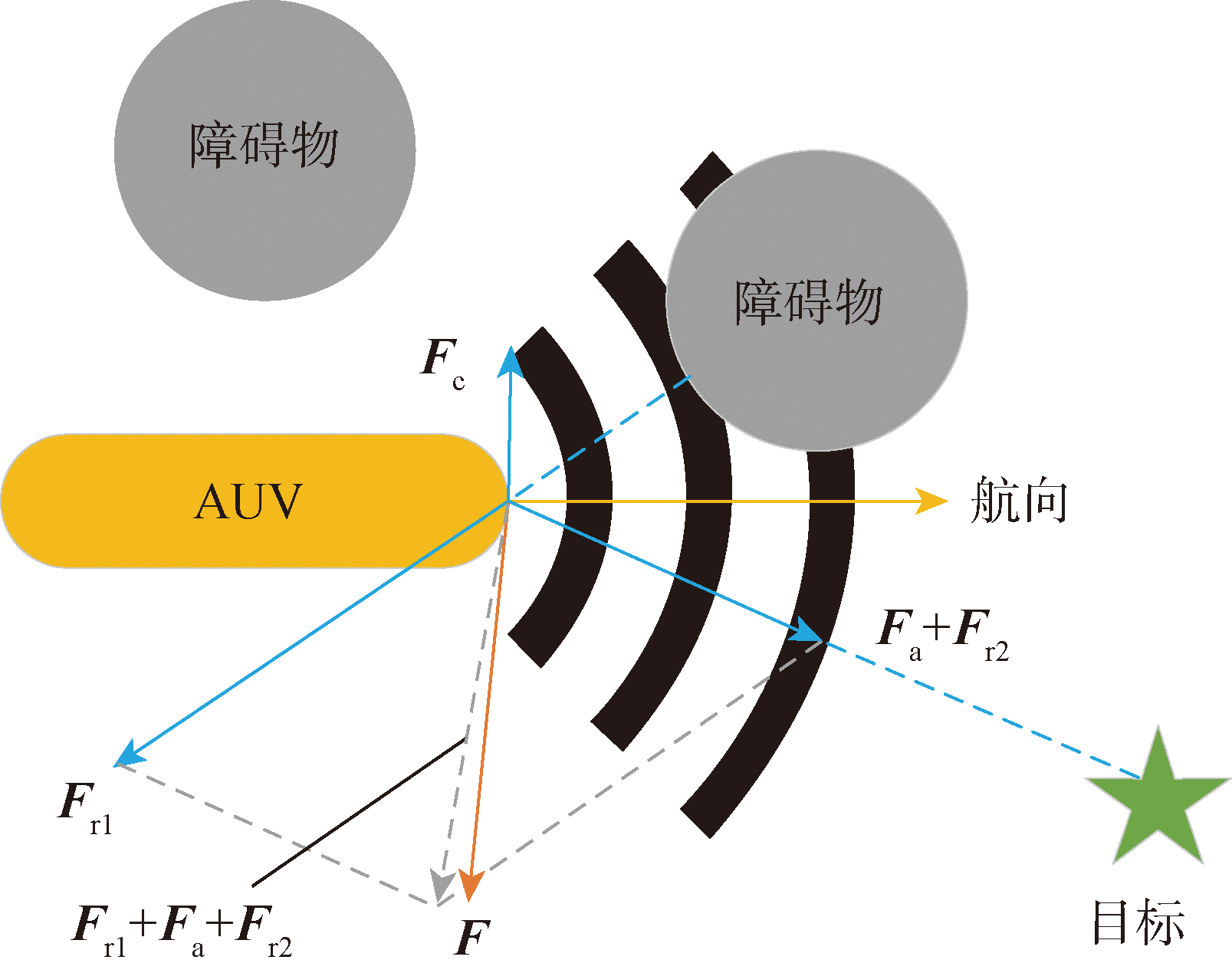
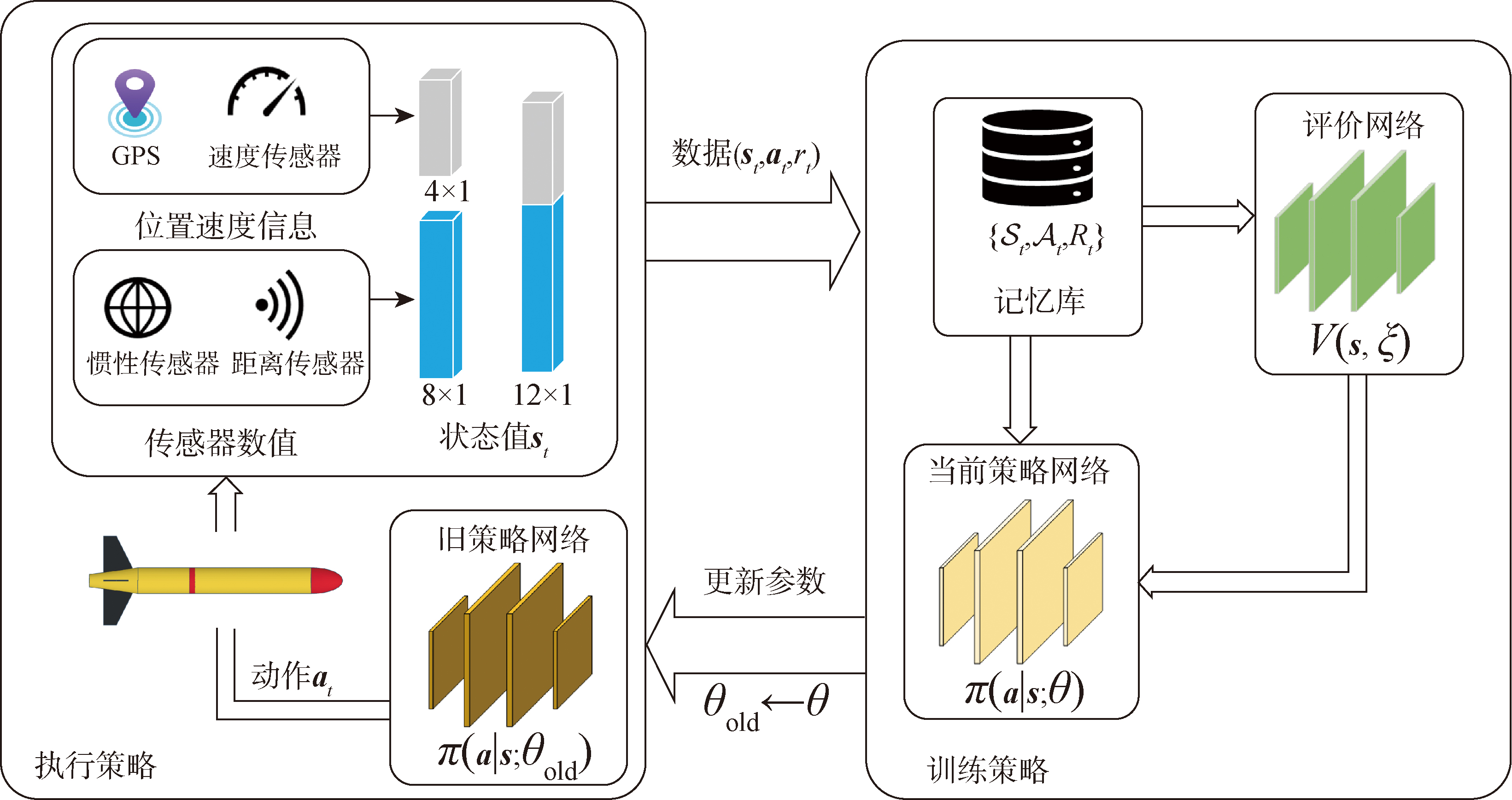
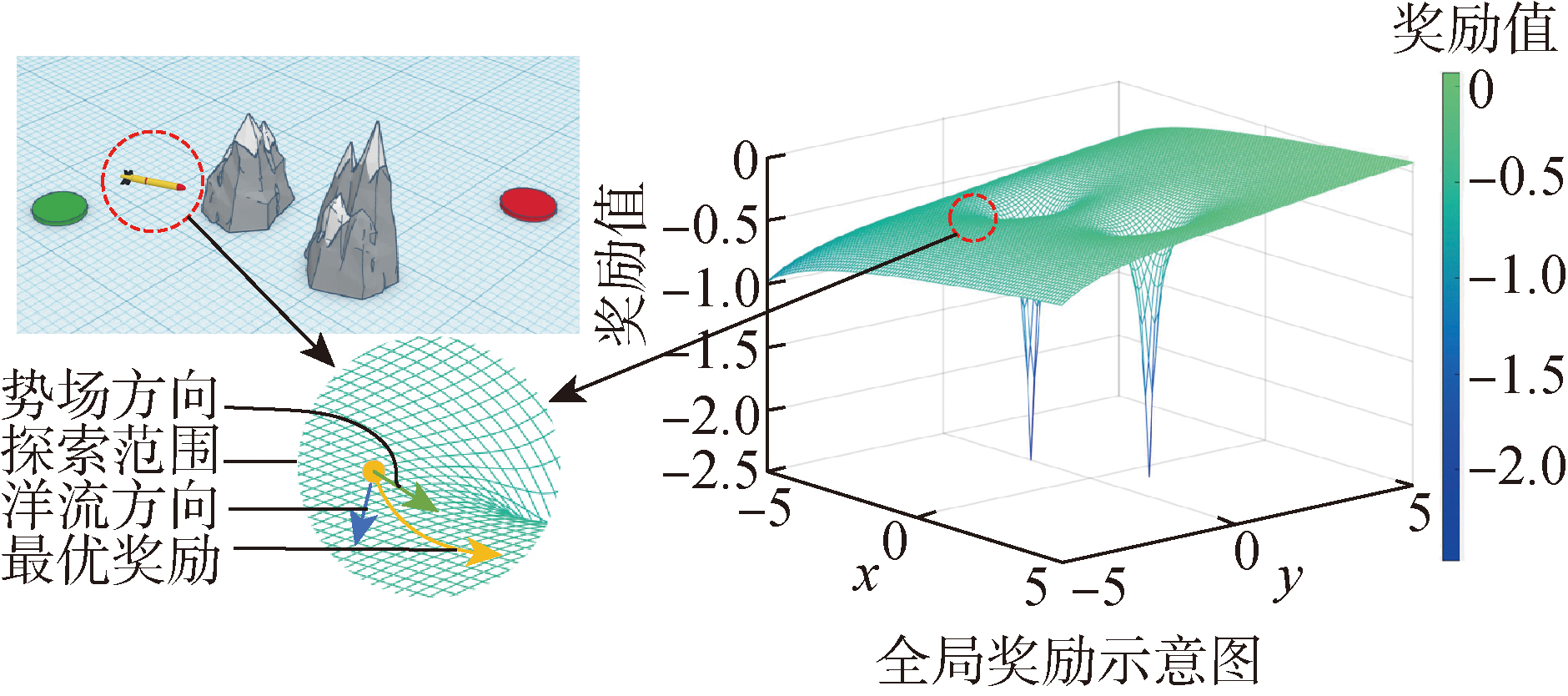
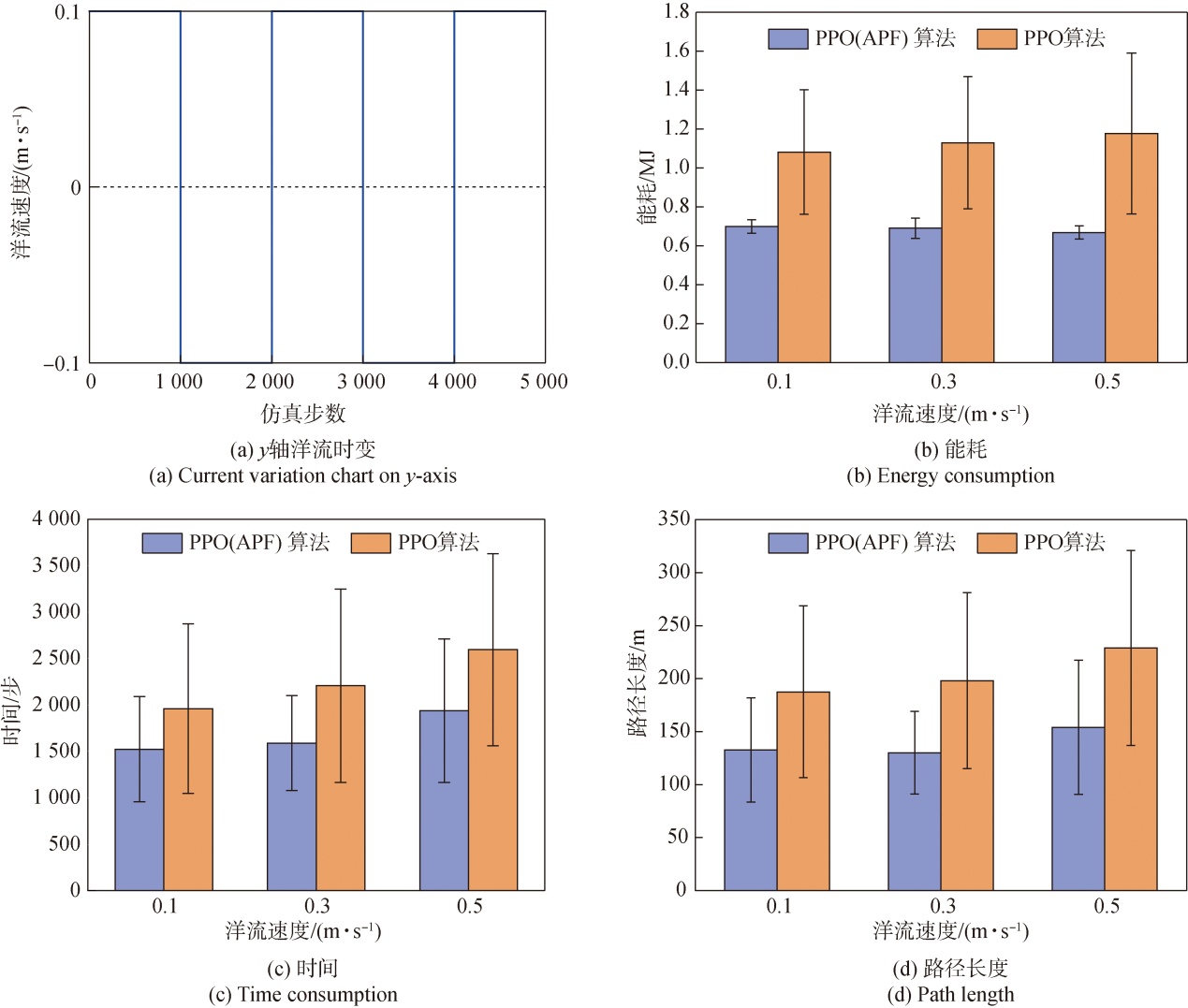
| [1] |
王圣洁, 康凤举, 韩翃. 潜艇与智能无人水下航行器协同系统控制体系及决策研究[J]. 兵工学报, 2017, 38(2):335-344.
doi: 10.3969/j.issn.1000-1093.2017.02.018
|
|
WANG S J, KANG F J, HAN H. Research on control and decision-making of submarine and intelligent UUV cooperative system[J]. Acta Armamentarii, 2017, 38(2):335-344. (in Chinese)
|
| [2] |
丁文俊, 张国宗, 刘海旻, 等. 面向海流扰动和通信时延的欠驱动AUV编队跟踪控制[J]. 兵工学报, 2024, 45(1):184-196.
doi: 10.12382/bgxb.2023.0417
|
|
DING W J, ZHANG G Z, LIU H M, et al. Tracking control of underactuated autonomous underwater vehicle formation under current disturbance and communication delay[J]. Acta Armamentarii, 2024, 45(1):184-196. (in Chinese)
doi: 10.12382/bgxb.2023.0417
|
| [3] |
WANG C, CHENG C S, YANG D Y, et al. Path planning in localization uncertaining environment based on Dijkstra method[J]. Frontiers in Neurorobotics, 2022,16:821991.
|
| [4] |
LIU Y, HUANG P F, ZHANG F, et al. Distributed formation control using artificial potentials and neural network for constrained multiagent systems[J]. IEEE Transactions on Control Systems Technology, 2020, 28(2):697-704.
|
| [5] |
WANG W, ZUO L, XU X. A learning-based multi-RRT approach for robot path planning in narrow passages[J]. Journal of Intelligent and Robotic Systems:Theory and Applications, 2018, 90(1/2):81-100.
|
| [6] |
TAO C L, ZHANG Y R, LI S Q, et al. Mechanism of interior ballistic peak phenomenon of guns and its effects[J]. Journal of Applied Mechanics, 2010, 77(5):51405.
|
| [7] |
ROBERGE V, TARBOUCHI M, LABONTE G. Comparison of parallel genetic algorithm and particle swarm optimization for real-time UAV path planning[J]. IEEE Transactions on Industrial Informatics, 2012, 9(1):132-141.
|
| [8] |
CHEN M Z, ZHU D Q. Optimal time-consuming path planning for autonomous underwater vehicles based on a dynamic neural network model in ocean current environments[J]. IEEE Transactions on Vehicular Technology, 2020, 69(12):14401-14412.
|
| [9] |
杨静, 吴金平, 刘剑, 等. 一种半监督学习潜艇规避防御智能决策方法[J]. 兵工学报, 2024, 45(10):3474-3487.
doi: 10.12382/bgxb.2023.0684
|
|
YANG J, WU J P, LIU J, et al. A semi-supervised learning method for intelligent decision making of submarine maneuver defense[J]. Acta Armamentarii, 2024, 45(10):3474-3487. (in Chinese)
doi: 10.12382/bgxb.2023.0684
|
| [10] |
HE Z C, DONG L, SUN C Y, et al. Asynchronous multithreading reinforcement-learning-based path planning and tracking for unmanned underwater vehicle[J]. IEEE Transactions on Systems,Man,and Cybernetics:Systems, 2022, 52(5):2757-2769.
|
| [11] |
SUN Y S, RAN X R, ZHANG G C, et al. AUV path following controlled by modified deep deterministic policy gradient[J]. Ocean Engineering, 2020,210:107360.
|
| [12] |
闫皎洁, 张锲石, 胡希平. 基于强化学习的路径规划技术综述[J]. 计算机工程, 2021, 47(10):16-25.
doi: 10.19678/j.issn.1000-3428.0060683
|
|
YAN J J, ZHANG Q S, HU X P. Review of path planning techniques based on reinforcement learning[J]. Computer Engineering, 2021, 47(10):16-25. (in Chinese)
doi: 10.19678/j.issn.1000-3428.0060683
|
| [13] |
ROUSSEAS P, BECHLIOULIS C, KYRIAKOPOULOS K J. Harmonic-based optimal motion planning in constrained workspaces using reinforcement learning[J]. IEEE Robotics and Automation Letters, 2021, 6(2):2005-2011.
|
| [14] |
王思鹏, 杜昌平, 郑耀. 基于强化学习的扑翼飞行器路径规划算法[J]. 控制与决策, 2022, 37(4):851-860.
|
|
WANG S P, DU C P, ZHENG Y. Local planner for flapping wing micro aerial vehicle based on deep reinforcement learning[J]. Control and Decision, 2022, 37(4):851-860. (in Chinese)
|
| [15] |
WANG C L, YANG X, LI H. Improved Q-learning applied to dynamic obstacle avoidance and path planning[J]. IEEE Access, 2022,10:92879-92888.
|
| [16] |
LV L H, ZHANG S J, DING D R, et al. Path planning via an improved DQN-based learning policy[J]. IEEE Access, 2019,7:67319-67330.
|
| [17] |
武建国, 石凯, 刘健, 等. 6000m AUV“潜龙一号”浮力调节系统开发及试验研究[J]. 海洋技术学报, 2014, 33(5):1-7.
|
|
WU J G, SHI K, LIU J, et al. Development and experimental research on the variable buoyancy system for the 6000m rated class “Qianlong I” AUV[J]. Ocean Technology, 2014, 33(5):1-7. (in Chinese)
|
| [18] |
WU Z T, DAI J Y, JIANG B P, et al. Robot path planning based on artificial potential field with deterministic annealing[J]. ISA Transactions, 2023,138:74-87.
|
| [19] |
SHIN Y J, KIM E. Hybrid path planning using positioning risk and artificial potential fields[J]. Aerospace Science and Technology, 2021,112:106640.
|
| [20] |
朱伟达. 基于改进型人工势场法的车辆避障路径规划研究[D]. 镇江: 江苏大学, 2017.
|
|
ZHU W D. Research on path planning and obstacle avoidance method for vehicle based on improved artificial potential field[D]. Zhenjiang: Jiangsu University, 2017. (in Chinese)
|
| [21] |
翟丽, 张雪莹, 张闲, 等. 基于势场法的无人车局部动态避障路径规划算法[J]. 北京理工大学学报, 2022, 42(7):696-705.
|
|
ZHAI L, ZHANG X Y, ZHANG X, et al. Local dynamic obstacle avoidance path planning algorithm for unmanned vehicles based on potential field method[J]. Transaction of Beijing Institute of Technology, 2022, 42(7):696-705. (in Chinese)
|

 ), 曾祥光1, 黄傲1, 张加衡1, 任文哲1, 彭倍2
), 曾祥光1, 黄傲1, 张加衡1, 任文哲1, 彭倍2
 京公网安备11010802024360号 京ICP备05059581号-4
京公网安备11010802024360号 京ICP备05059581号-4