
主管单位:中国科学技术协会
主办单位:中国兵工学会
ISSN 1000-1093 CN 11-2176/TJ
主办单位:中国兵工学会
ISSN 1000-1093 CN 11-2176/TJ
兵工学报 ›› 2025, Vol. 46 ›› Issue (3): 240357-.doi: 10.12382/bgxb.2024.0357
张旺, 邵学辉, 唐慧龙, 魏建林, 王伟*( )
)
收稿日期:2024-05-10
上线日期:2025-03-26
通讯作者:
基金资助:
ZHANG Wang, SHAO Xuehui, TANG Huilong, WEI Jianlin, WANG Wei*()
Received:2024-05-10
Online:2025-03-26
摘要:
针对当前基于强化学习的雷达干扰决策方法依据单一因素、固定规律设置探索率参数导致算法收敛需要的对抗回合次数增多的问题,提出一种探索率自适应设置的强化学习雷达干扰决策方法。基于模拟退火法的Metropolis参数调节准则,结合对抗过程中干扰机已识别的雷达工作状态数量、干扰成功次数、算法收敛曲线变化率及干扰机对雷达的认知程度,推导一种探索率自适应设置准则。依据干扰动作的有效性,设计一种干扰动作空间裁剪策略,减小干扰动作空间维度,进一步提高算法收敛速度。在仿真实验中,设计两个不同的雷达工作状态图,并结合Q学习算法予以对比验证。仿真结果表明,在雷达工作状态转换关系发生变化的情况下,新方法均可完成探索率的自适应设置,与基于模拟退火法以及单一因素、固定规律的探索率设置方案相比,新方法在两个状态图下收敛需要的对抗回合次数分别减少了18%、26%、45%和42%、44%、48%,同时还可获得更大的收益和更高的干扰成功率,为基于强化学习的多功能雷达干扰决策提供了一种新的探索率设置思路。
张旺, 邵学辉, 唐慧龙, 魏建林, 王伟. 一种探索率自适应设置的强化学习雷达干扰决策方法[J]. 兵工学报, 2025, 46(3): 240357-.
ZHANG Wang, SHAO Xuehui, TANG Huilong, WEI Jianlin, WANG Wei. A Reinforcement Learning-based Radar Jamming Decision-making Method with Adaptive Setting of Exploration Rate[J]. Acta Armamentarii, 2025, 46(3): 240357-.

图1 基于强化学习的雷达干扰决策
Fig.1 Radar jamming decision-making based on reinforcement learning
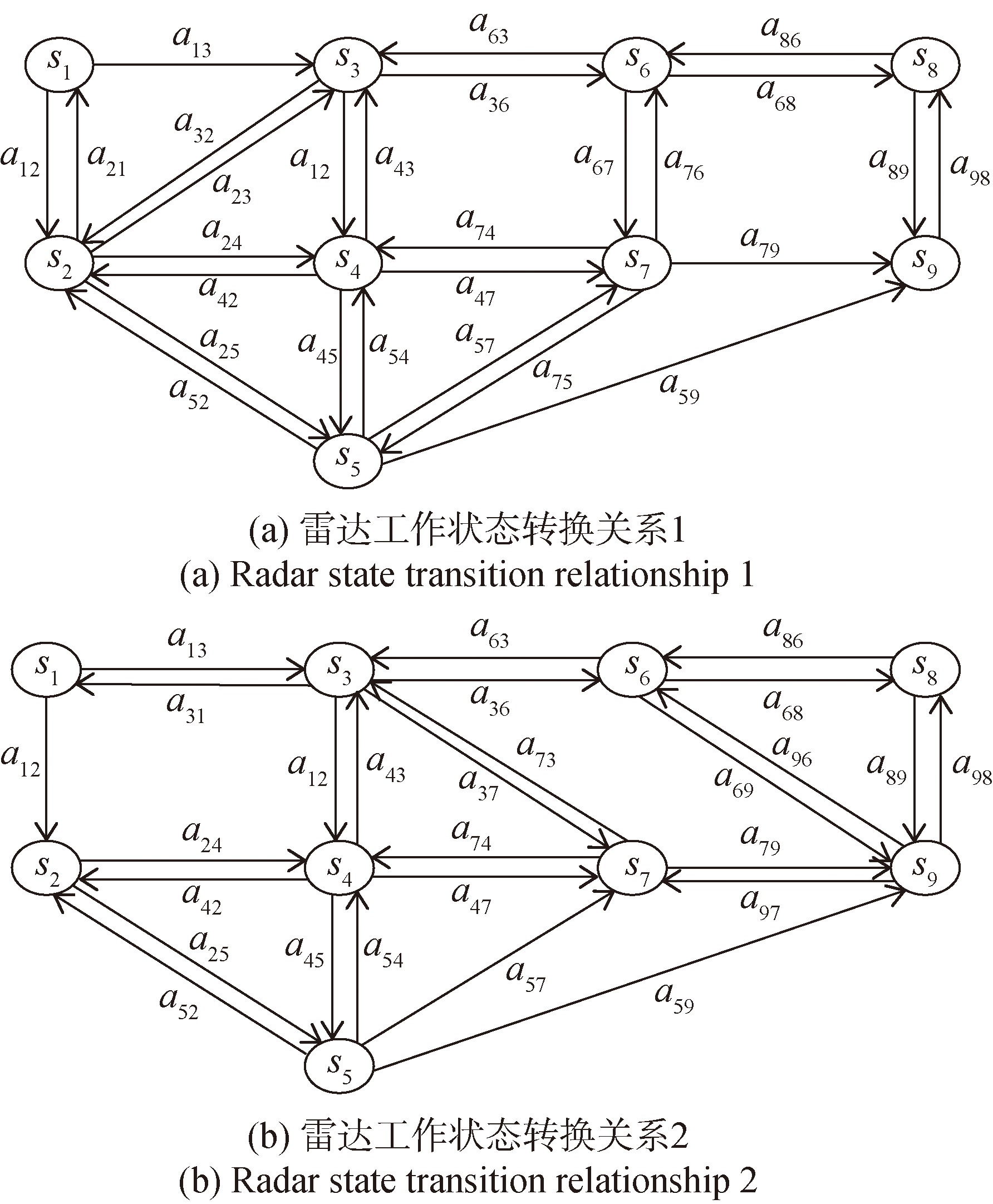
图2 雷达工作状态转换关系
Fig.2 Radar state transition relationship
| S | S' | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
| 1 | 0.65 | 0.07 | 0.28 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0.13 | 0.35 | 0.11 | 0.34 | 0.07 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0.54 | 0.20 | 0.11 | 0 | 0.15 | 0 | 0 | 0 |
| 4 | 0 | 0.22 | 0.17 | 0.12 | 0.29 | 0 | 0.20 | 0 | 0 |
| 5 | 0 | 0.17 | 0 | 0.28 | 0.09 | 0 | 0.23 | 0 | 0.23 |
| 6 | 0 | 0 | 0.35 | 0 | 0 | 0.53 | 0.07 | 0.05 | 0 |
| 7 | 0 | 0 | 0 | 0.18 | 0.27 | 0.32 | 0.04 | 0 | 0.19 |
| 8 | 0 | 0 | 0 | 0 | 0 | 0.57 | 0 | 0.02 | 0.41 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.17 | 0.83 |
表1 状态转移矩阵
Table 1 State transition matrix
| S | S' | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
| 1 | 0.65 | 0.07 | 0.28 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0.13 | 0.35 | 0.11 | 0.34 | 0.07 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0.54 | 0.20 | 0.11 | 0 | 0.15 | 0 | 0 | 0 |
| 4 | 0 | 0.22 | 0.17 | 0.12 | 0.29 | 0 | 0.20 | 0 | 0 |
| 5 | 0 | 0.17 | 0 | 0.28 | 0.09 | 0 | 0.23 | 0 | 0.23 |
| 6 | 0 | 0 | 0.35 | 0 | 0 | 0.53 | 0.07 | 0.05 | 0 |
| 7 | 0 | 0 | 0 | 0.18 | 0.27 | 0.32 | 0.04 | 0 | 0.19 |
| 8 | 0 | 0 | 0 | 0 | 0 | 0.57 | 0 | 0.02 | 0.41 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.17 | 0.83 |
| S | S' | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
| 1 | 0.32 | 0.35 | 0.32 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0.32 | 0 | 0.16 | 0.52 | 0 | 0 | 0 | 0 |
| 3 | 0.02 | 0 | 0.18 | 0.27 | 0 | 0..21 | 0.32 | 0 | 0 |
| 4 | 0 | 0.18 | 0.31 | 0.09 | 0.11 | 0 | 0.31 | 0 | 0 |
| 5 | 0 | 0.16 | 0 | 0.30 | 0.35 | 0 | 0.2 | 0 | 0 |
| 6 | 0 | 0 | 0.26 | 0 | 0 | 0.38 | 0 | 0.15 | 0.21 |
| 7 | 0 | 0 | 0.35 | 0.14 | 0 | 0 | 0.16 | 0 | 0.35 |
| 8 | 0 | 0 | 0 | 0 | 0 | 0.21 | 0 | 0.59 | 0.2 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0.41 | 0.05 | 0.04 | 0.50 |
表2 状态转移矩阵2
Table 2 State transition matrix 2
| S | S' | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
| 1 | 0.32 | 0.35 | 0.32 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0.32 | 0 | 0.16 | 0.52 | 0 | 0 | 0 | 0 |
| 3 | 0.02 | 0 | 0.18 | 0.27 | 0 | 0..21 | 0.32 | 0 | 0 |
| 4 | 0 | 0.18 | 0.31 | 0.09 | 0.11 | 0 | 0.31 | 0 | 0 |
| 5 | 0 | 0.16 | 0 | 0.30 | 0.35 | 0 | 0.2 | 0 | 0 |
| 6 | 0 | 0 | 0.26 | 0 | 0 | 0.38 | 0 | 0.15 | 0.21 |
| 7 | 0 | 0 | 0.35 | 0.14 | 0 | 0 | 0.16 | 0 | 0.35 |
| 8 | 0 | 0 | 0 | 0 | 0 | 0.21 | 0 | 0.59 | 0.2 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0.41 | 0.05 | 0.04 | 0.50 |
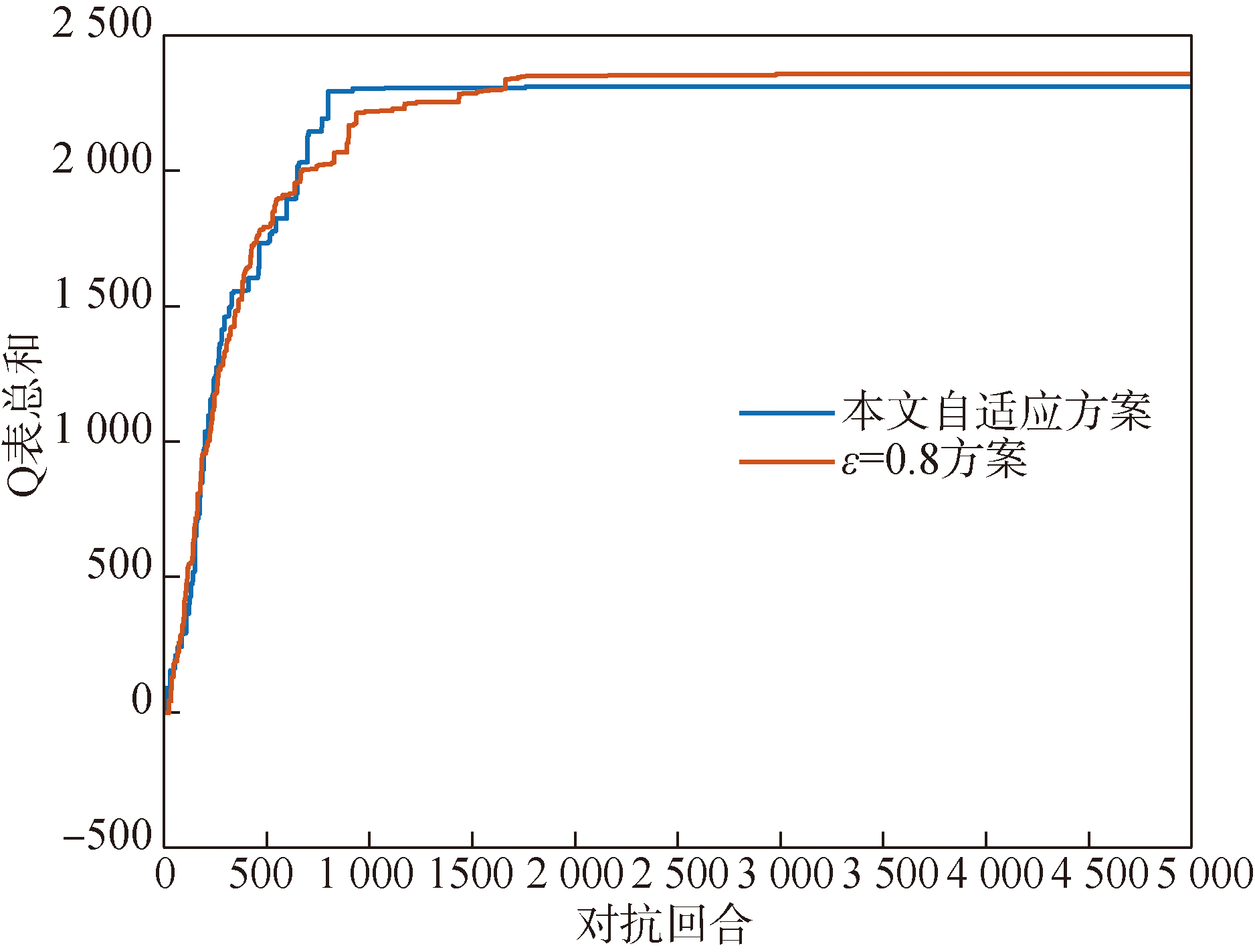
图3 探索率自适应设置策略仿真
Fig.3 Simulation of exploration rate adaptive setting strategy
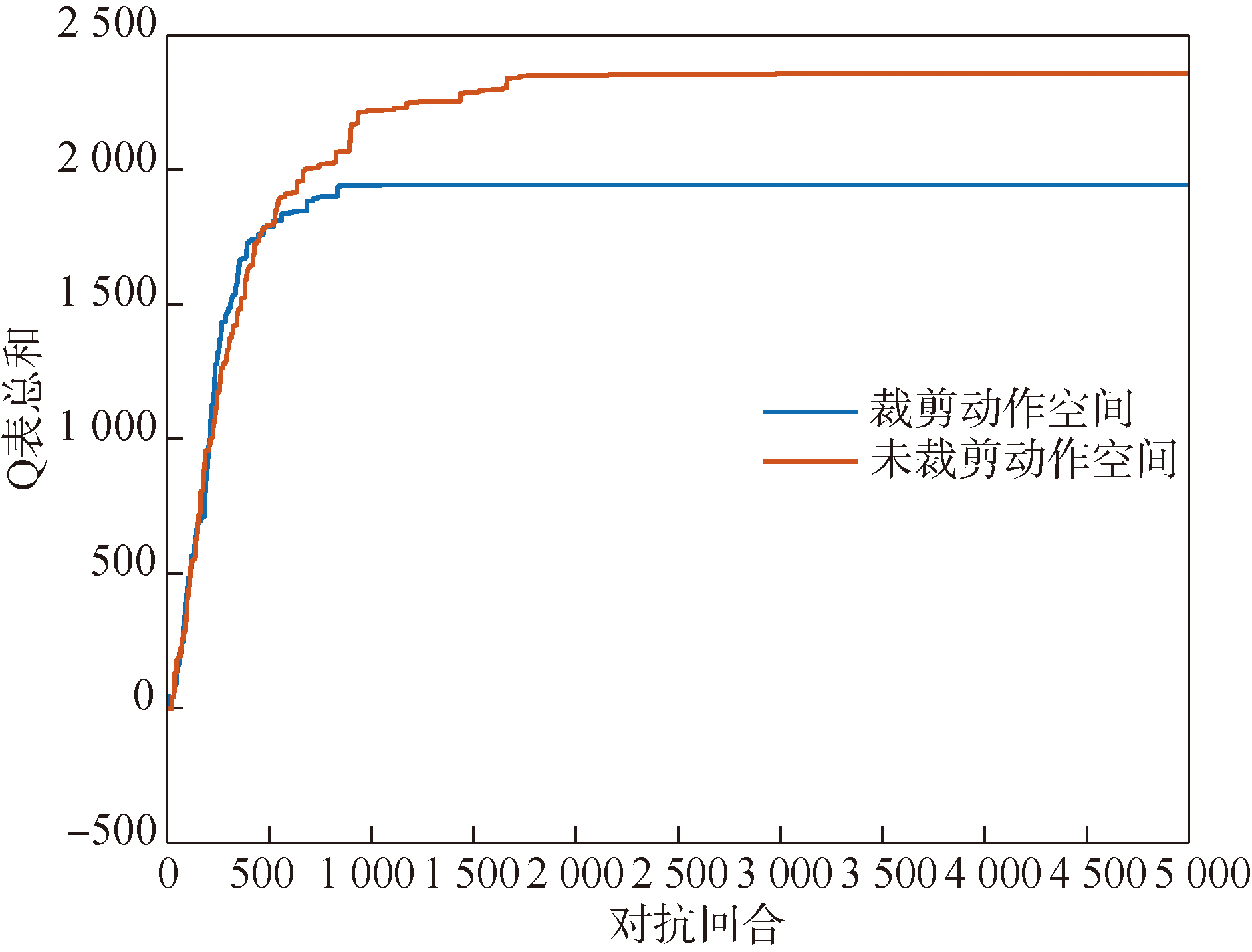
图4 干扰动作空间裁剪策略仿真
Fig.4 Simulation of jamming action space cropping strategy
| S | a | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
| 1 | 37.0 | 50.1 | 53.6 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 44.4 | 56.5 | 53.6 | 65.8 | 81.0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 50.6 | 41.6 | 61.9 | 0 | 65.8 | 0 | 0 | 0 |
| 4 | 0 | 56.1 | -0.6 | 59.2 | 78.6 | 0 | 81.0 | 0 | 0 |
| 5 | 0 | 54.0 | 0 | 63.7 | 67.4 | 0 | 81.0 | 0 | 100 |
| 6 | 0 | 0 | 49.8 | 0 | 0 | 60.1 | -0.5 | 81 | 0 |
| 7 | 0 | 0 | 0 | 62.4 | 78.9 | 59.8 | 35.5 | 0 | 100 |
| 8 | 0 | 0 | 0 | 0 | 0 | 59.3 | 0 | 0 | 100 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
表3 自适应探索率收敛矩阵
Table 3 Adaptive exploration rate convergence matrix
| S | a | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
| 1 | 37.0 | 50.1 | 53.6 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 44.4 | 56.5 | 53.6 | 65.8 | 81.0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 50.6 | 41.6 | 61.9 | 0 | 65.8 | 0 | 0 | 0 |
| 4 | 0 | 56.1 | -0.6 | 59.2 | 78.6 | 0 | 81.0 | 0 | 0 |
| 5 | 0 | 54.0 | 0 | 63.7 | 67.4 | 0 | 81.0 | 0 | 100 |
| 6 | 0 | 0 | 49.8 | 0 | 0 | 60.1 | -0.5 | 81 | 0 |
| 7 | 0 | 0 | 0 | 62.4 | 78.9 | 59.8 | 35.5 | 0 | 100 |
| 8 | 0 | 0 | 0 | 0 | 0 | 59.3 | 0 | 0 | 100 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
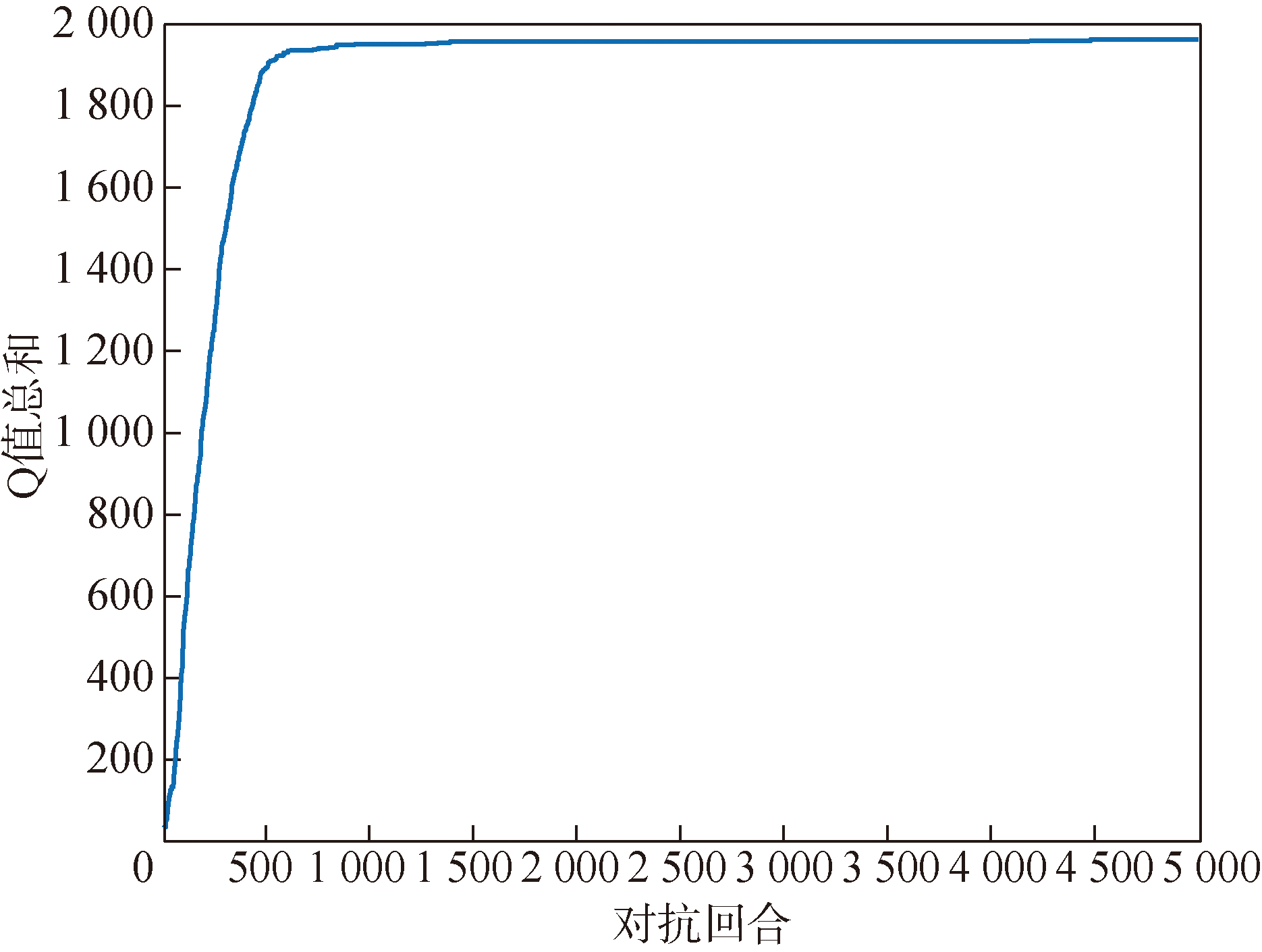
图5 Q表总和收敛曲线
Fig.5 Q-table total convergence curve

图6 各变量变化情况
Fig.6 Changes in various variables

图7 自适应探索率
Fig.7 Adaptive exploration rate
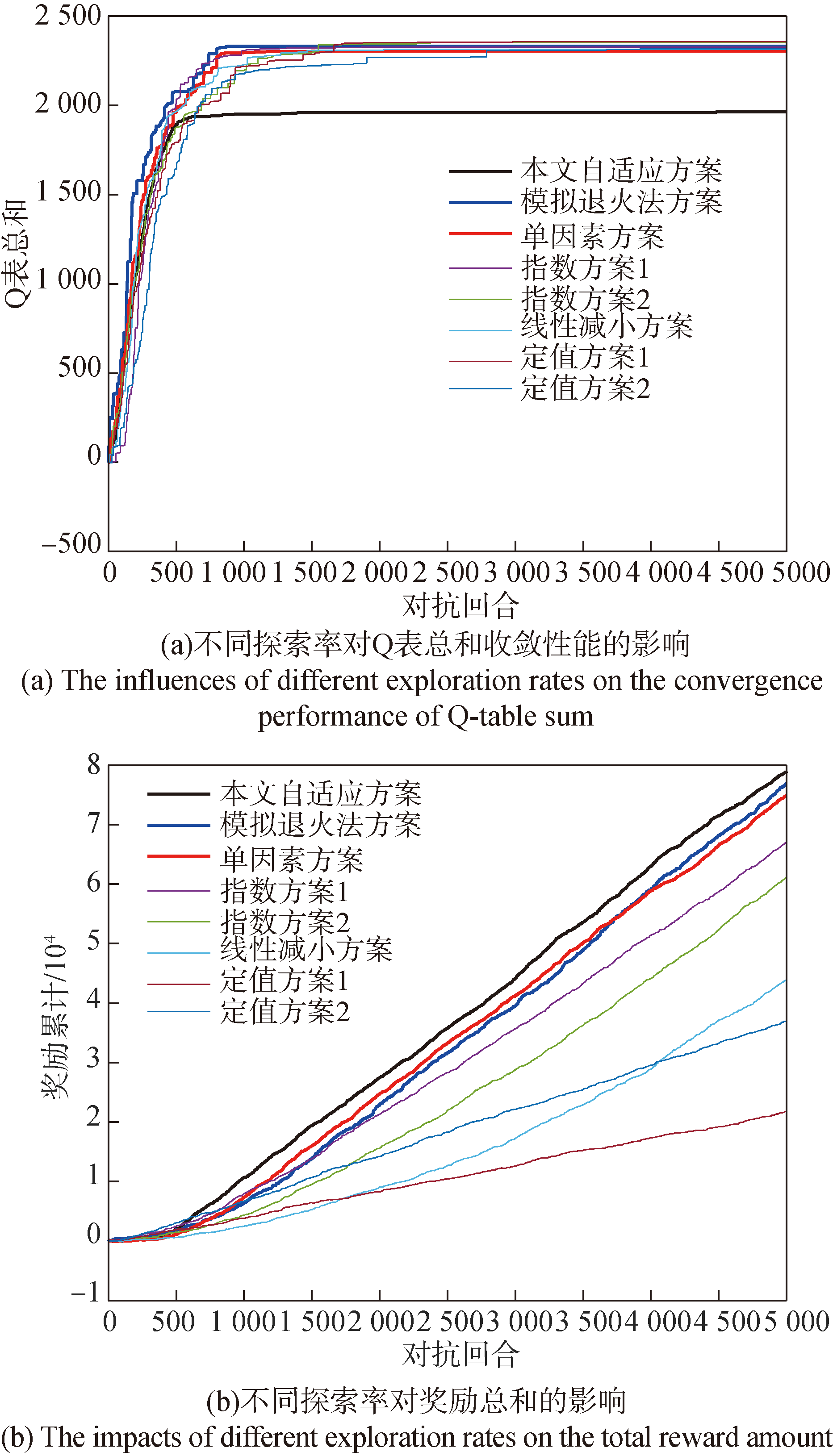
图8 不同探索率对算法收敛性能的影响
Fig.8 The influences of different exploration rates on the convergence performance of algorithm
| S | a | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
| 1 | 50.1 | 63.8 | 52.2 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 49.5 | 63.8 | 52.1 | 65.8 | 81.0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 63.8 | 51.0 | 63.2 | 0 | 65.0 | 0 | 0 | 0 |
| 4 | 0 | 63.8 | 50.2 | 63.5 | 79.0 | 0 | 81.0 | 0 | 0 |
| 5 | 0 | 63.8 | 0 | 63.8 | 78.9 | 0 | 81.0 | 0 | 100 |
| 6 | 0 | 0 | 50.9 | 0 | 0 | 62.9 | 79 | 79.5 | 0 |
| 7 | 0 | 0 | 0 | 63.5 | 79.0 | 62.2 | 74.3 | 0 | 100 |
| 8 | 0 | 0 | 0 | 0 | 0 | 62.2 | 0 | 24.1 | 100 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
表4 模拟退火法的探索率收敛矩阵
Table 4 Exploration rate convergence matrix of simulated annealing method
| S | a | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
| 1 | 50.1 | 63.8 | 52.2 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 49.5 | 63.8 | 52.1 | 65.8 | 81.0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 63.8 | 51.0 | 63.2 | 0 | 65.0 | 0 | 0 | 0 |
| 4 | 0 | 63.8 | 50.2 | 63.5 | 79.0 | 0 | 81.0 | 0 | 0 |
| 5 | 0 | 63.8 | 0 | 63.8 | 78.9 | 0 | 81.0 | 0 | 100 |
| 6 | 0 | 0 | 50.9 | 0 | 0 | 62.9 | 79 | 79.5 | 0 |
| 7 | 0 | 0 | 0 | 63.5 | 79.0 | 62.2 | 74.3 | 0 | 100 |
| 8 | 0 | 0 | 0 | 0 | 0 | 62.2 | 0 | 24.1 | 100 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
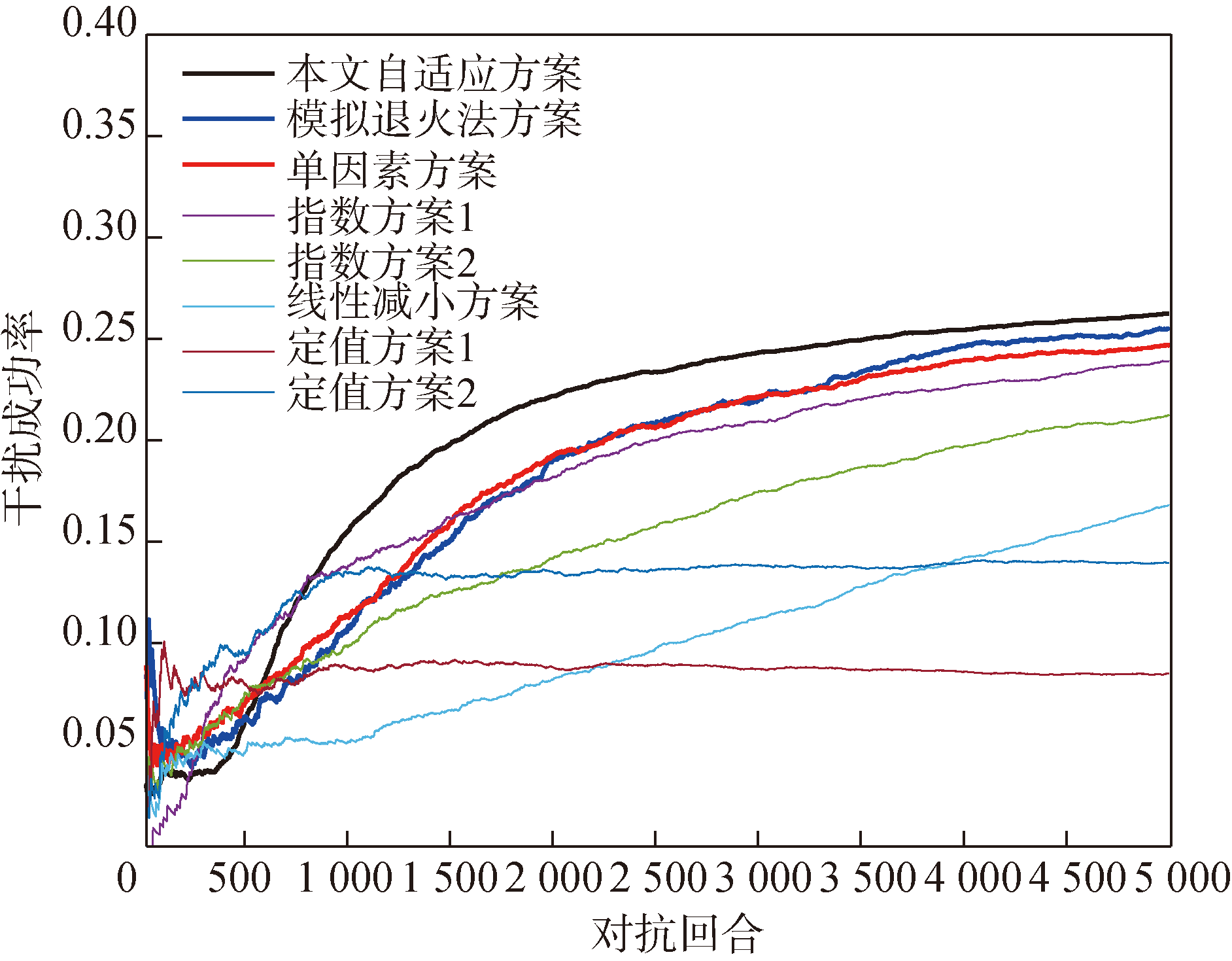
图9 不同探索率下的干扰成功率
Fig.9 Jamming success rates under different exploration rates
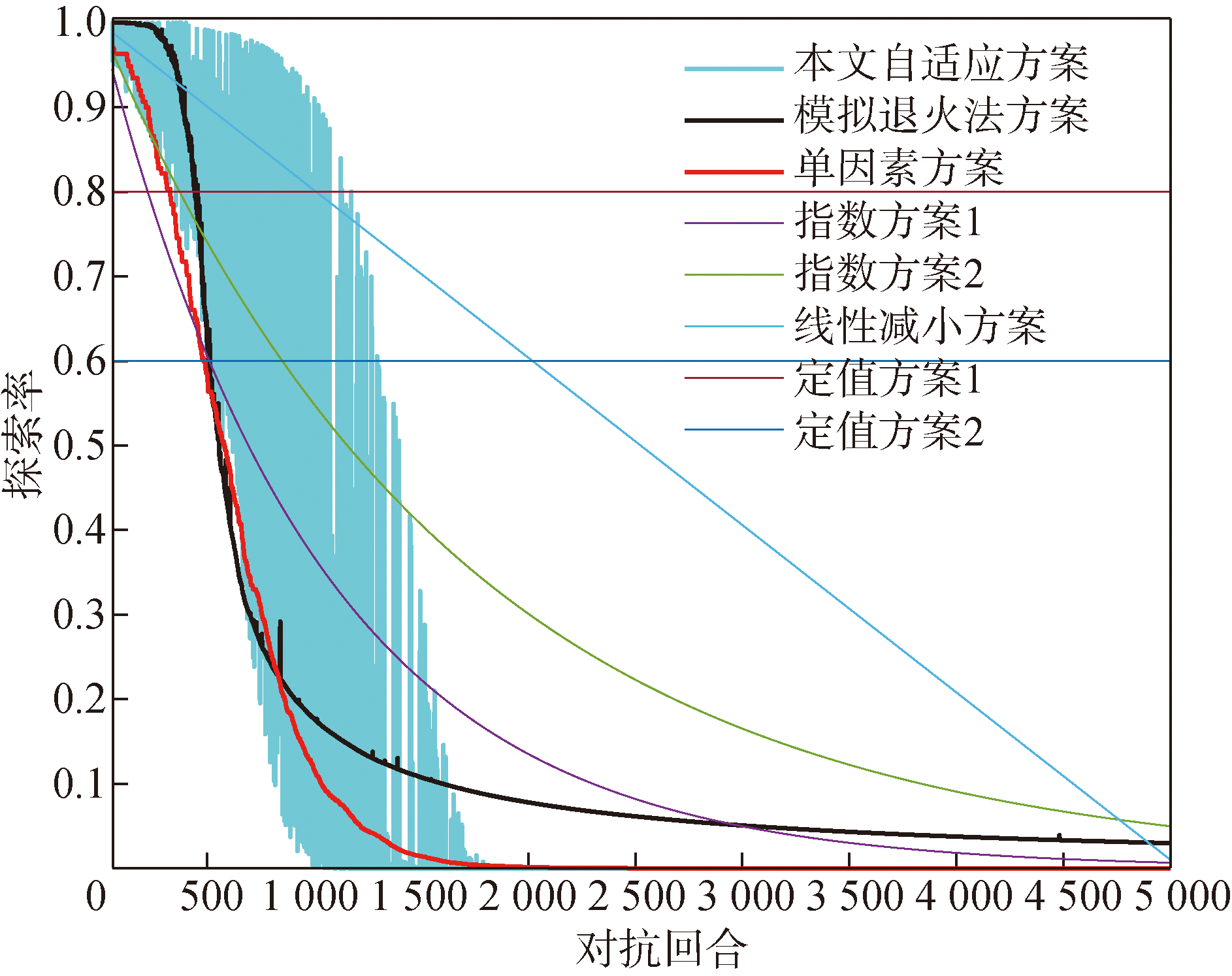
图10 不同探索率曲线
Fig.10 Different exploration rate curves
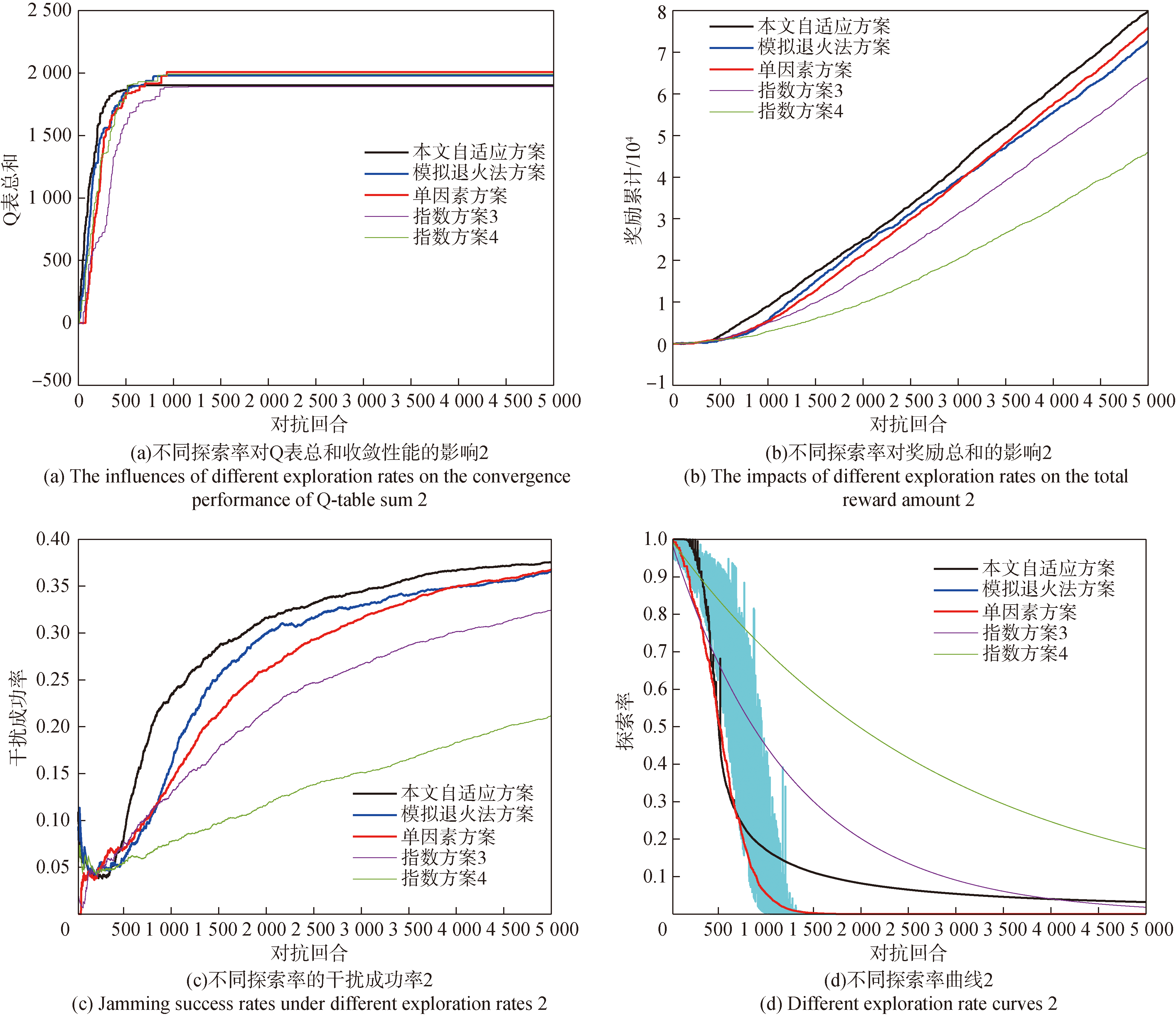
图11 性能对比
Fig.11 Performance comparison
| [1] |
张柏开, 朱卫纲. MFR认知干扰决策体系构建及关键技术[J]. 系统工程与电子技术, 2020, 42(9):1969-1975.
doi: 10.3969/j.issn.1001-506X.2020.09.12 |
|
|
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
黄知涛, 王翔, 赵雨睿. 认知电子战综述[J]. 国防科技大学学报, 2023, 45(5):1-11.
|
|
|
|
| [6] |
|
| [7] |
冯路为, 刘松涛, 徐华志. 基于POMDP模型的智能雷达干扰决策方法[J]. 系统工程与电子技术, 2023, 45(9):2755-2760.
doi: 10.12305/j.issn.1001-506X.2023.09.13 |
|
|
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
李云杰, 朱云鹏, 高梅国. 基于Q-学习算法的认知雷达对抗过程设计[J]. 北京理工大学学报, 2015, 35(11):1194-1199.
|
|
|
|
| [13] |
邢强, 贾鑫, 朱卫纲. 基于Q-学习的智能雷达对抗[J]. 系统工程与电子技术, 2018, 40(5):1031-1035.
|
|
|
|
| [14] |
张柏开, 朱卫纲. 基于Q-Learning的多功能雷达认知干扰决策方法[J]. 电讯技术, 2020, 60(2):129-136.
|
|
|
|
| [15] |
张柏开, 朱卫纲. 对多功能雷达的DQN认知干扰决策方法[J]. 系统工程与电子技术, 2020, 42(4):819-825.
doi: 10.3969/j.issn.1001-506X.2020.04.12 |
|
|
|
| [16] |
朱霸坤, 朱卫纲, 李伟, 等. 基于先验知识的多功能雷达智能干扰决策方法[J]. 系统工程与电子技术, 2022, 44(12):3685-3695.
doi: 10.12305/j.issn.1001-506X.2022.12.12 |
|
|
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
廖艳苹, 谢榕浩. 基于双层强化学习的多功能雷达认知干扰决策方法[J]. 应用科技, 2023, 50(6):56-62.
|
|
|
|
| [21] |
|
| [22] |
侯志杰. 雷达个体识别及干扰决策[D]. 西安: 西安电子科技大学, 2021.
|
|
|
|
| [23] |
尹依伊, 王晓芳, 周健. 基于Q学习的多无人机协同航迹规划方法[J]. 兵工学报, 2023, 44(2):484-495.
doi: 10.12382/bgxb.2021.0606 |
|
|
|
| [24] |
毛少卿. 基于强化学习的智能干扰决策方法研究[D]. 哈尔滨: 哈尔滨工业大学, 2021.
|
|
|
| [1] | 李传浩, 明振军, 王国新, 阎艳, 丁伟, 万斯来, 丁涛. 基于多智能体深度强化学习的无人平台箔条干扰末端防御动态决策方法[J]. 兵工学报, 2025, 46(3): 240251-. |
| [2] | 肖柳骏, 李雅轩, 刘新福. 基于强化学习的高超声速滑翔飞行器自适应末制导[J]. 兵工学报, 2025, 46(2): 240222-. |
| [3] | 胡砚洋, 何凡, 白成超. 高超声速飞行器末制导段协同避障决策方法[J]. 兵工学报, 2024, 45(9): 3147-3160. |
| [4] | 孙浩, 黎海青, 梁彦, 马超雄, 吴翰. 基于知识辅助深度强化学习的巡飞弹组动态突防决策[J]. 兵工学报, 2024, 45(9): 3161-3176. |
| [5] | 陈文杰, 崔小红, 王斌锐. 安全最优跟踪控制算法与机械手仿真[J]. 兵工学报, 2024, 45(8): 2688-2697. |
| [6] | 王霄龙, 陈洋, 胡棉, 李旭东. 基于改进深度Q网络的机器人持续监测路径规划[J]. 兵工学报, 2024, 45(6): 1813-1823. |
| [7] | 娄抒瀚, 王冲冲, 龚炜, 邓立原, 李莉. 基于MLAT-DRL算法的协同区域信息采集策略[J]. 兵工学报, 2024, 45(12): 4423-4434. |
| [8] | 董明泽, 温庄磊, 陈锡爱, 杨炅坤, 曾涛. 安全凸空间与深度强化学习结合的机器人导航方法[J]. 兵工学报, 2024, 45(12): 4372-4382. |
| [9] | 李加申, 王晓芳, 林海. 引入虚拟目标的高超声速巡航导弹智能机动突防策略[J]. 兵工学报, 2024, 45(11): 3856-3867. |
| [10] | 傅妍芳, 雷凯麟, 魏佳宁, 曹子建, 杨博, 王炜, 孙泽龙, 李秦洁. 基于演员-评论家框架的层次化多智能体协同决策方法[J]. 兵工学报, 2024, 45(10): 3385-3396. |
| [11] | 李松, 麻壮壮, 张蕴霖, 邵晋梁. 基于安全强化学习的多智能体覆盖路径规划[J]. 兵工学报, 2023, 44(S2): 101-113. |
| [12] | 曹子建, 孙泽龙, 闫国闯, 傅妍芳, 杨博, 李秦洁, 雷凯麟, 高领航. 基于强化学习的无人机集群对抗策略推演仿真[J]. 兵工学报, 2023, 44(S2): 126-134. |
| [13] | 杨加秀, 李新凯, 张宏立, 王昊. 基于积分强化学习的四旋翼无人机鲁棒跟踪[J]. 兵工学报, 2023, 44(9): 2802-2813. |
| [14] | 张建东, 王鼎涵, 杨啟明, 史国庆, 陆屹, 张耀中. 基于分层强化学习的无人机空战多维决策[J]. 兵工学报, 2023, 44(6): 1547-1563. |
| [15] | 李超, 王瑞星, 黄建忠, 江飞龙, 魏雪梅, 孙延鑫. 稀疏奖励下基于强化学习的无人集群自主决策与智能协同[J]. 兵工学报, 2023, 44(6): 1537-1546. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
 京公网安备11010802024360号 京ICP备05059581号-4
京公网安备11010802024360号 京ICP备05059581号-4