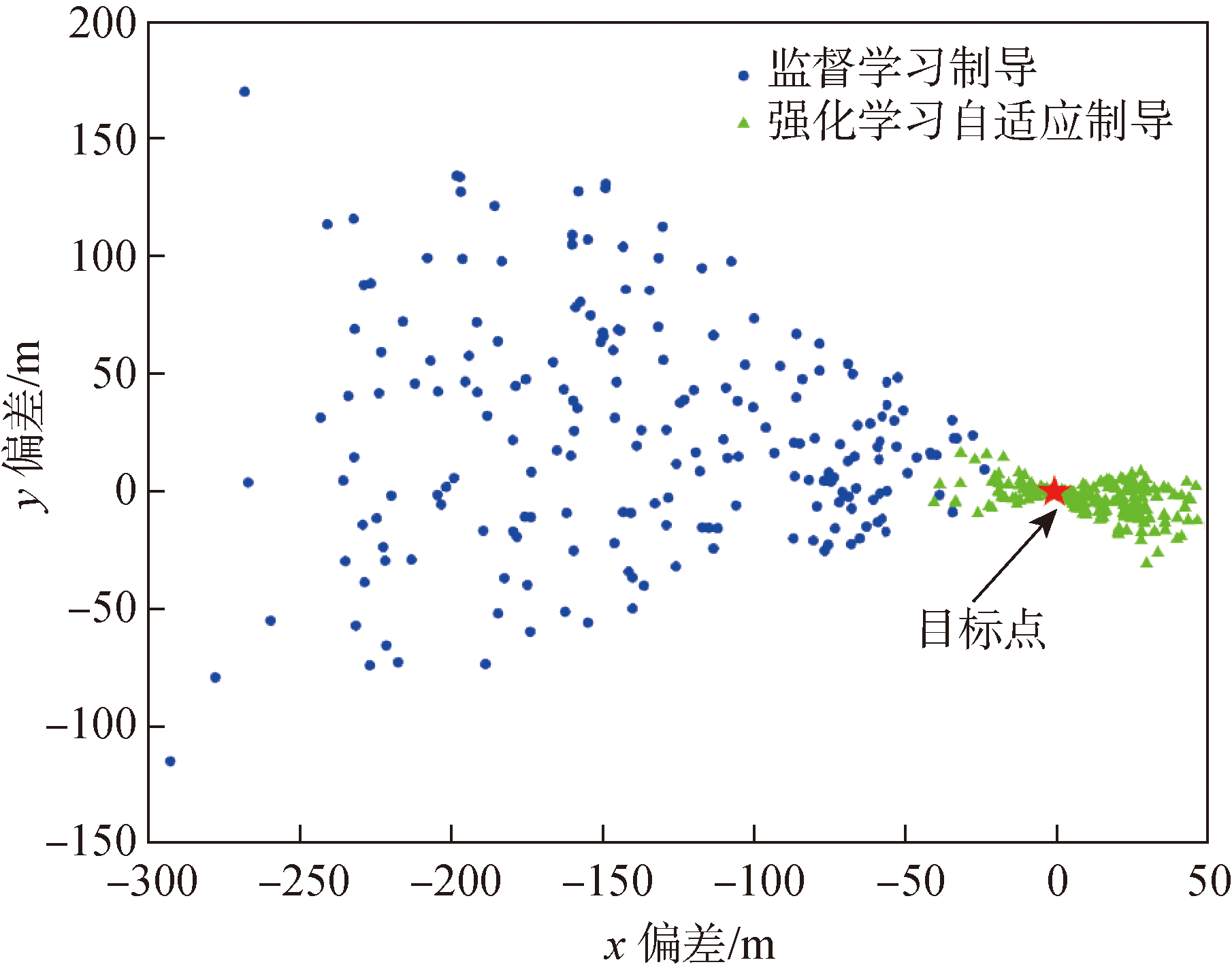
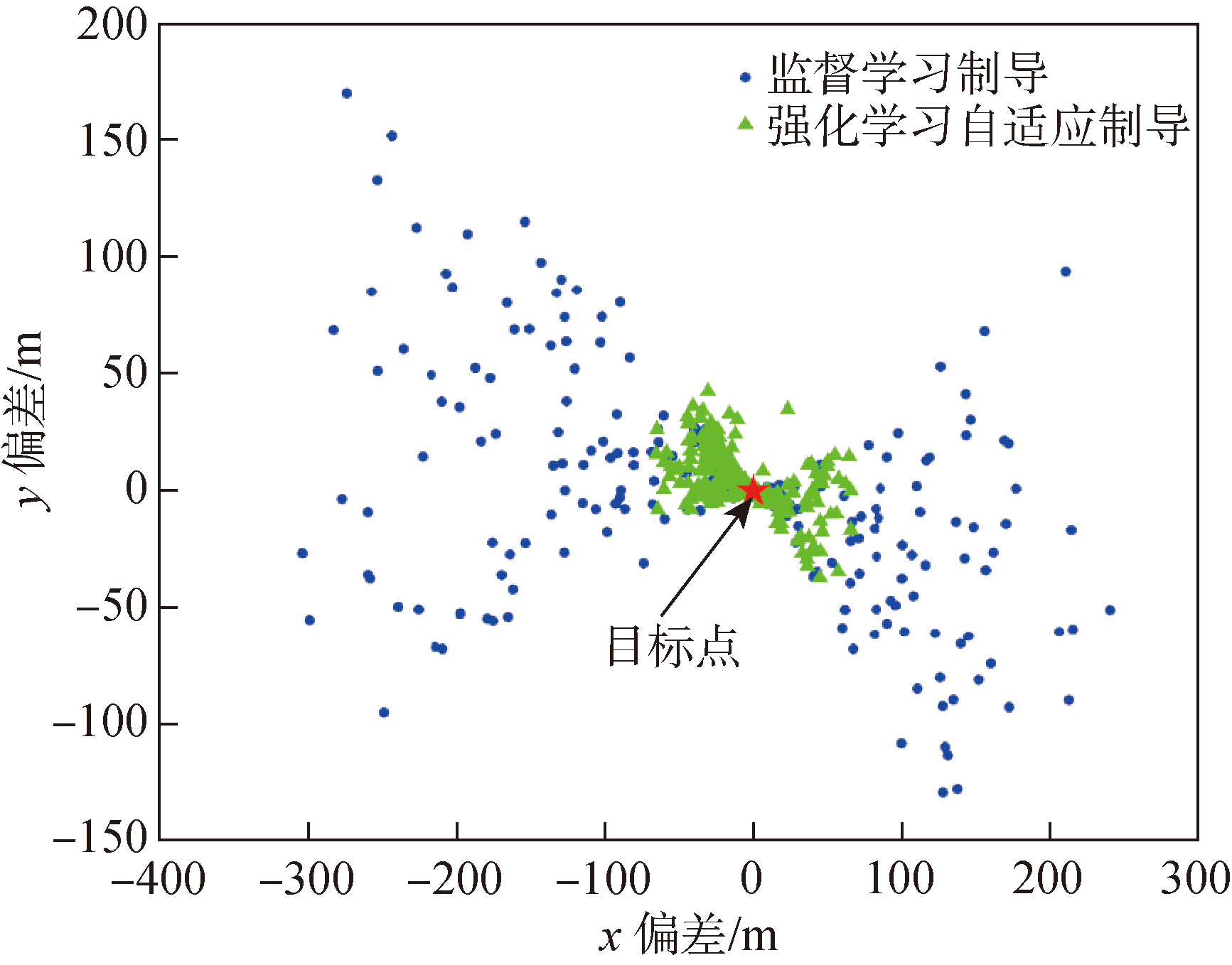
| [1] |
董金鲁, 马悦萌, 周荻, 等. 临近空间高超声速飞行器的直接力与襟翼复合滑模控制[J]. 兵工学报, 2023, 44(2):496-506.
doi: 10.12382/bgxb.2021.0690
|
|
DONG J L, MA Y M, ZHOU D, et al. A composite sliding mode control scheme based on reaction jets and flaps for near-space hypersonic vehicles[J]. Acta Armamentarii, 2023, 44(2):496-506. (in Chinese)
doi: 10.12382/bgxb.2021.0690
|
| [2] |
MURTAUGH S A, CRIEL H E. Fundamentals of proportional navigation[J]. IEEE Spectrum, 1966, 3(12):75-85.
|
| [3] |
刘畅, 王江, 范世鹏, 等. 基于BP神经网络的自适应偏置比例导引[J]. 兵工学报, 2022, 43(11):2798-2809.
|
|
LIU C, WANG J, FAN S P, et al. BP neural network-based adaptive biased proportional navigation guidance law[J]. Acta Armamentarii, 2022, 43(11):2798-2809. (in Chinese)
doi: 10.12382/bgxb.2021.0594
|
| [4] |
ULYBYSHEV Y. Terminal guidance law based on proportional navigation[J]. Journal of Guidance,Control,and Dynamics, 2005, 28(4):821-824.
|
| [5] |
LU P, DOMAN D B, SCHIERMAN J D. Adaptive terminal guidance for hypervelocity impact in specified direction[J]. Journal of Guidance,Control,and Dynamics, 2006, 29(2):269-278.
|
| [6] |
GUO R Y, DING Y B, YUE X K. Active adaptive continuous nonsingular terminal sliding mode controller for hypersonic vehicle[J]. Aerospace Science and Technology, 2023, 137:108279.
|
| [7] |
WU P, YANG M. Integrated guidance and control design for missile with terminal impact angle constraint based on sliding mode control[J]. Journal of Systems Engineering and Electronics, 2010, 21(4):623-628.
|
| [8] |
SI Y J, SONG S M. Adaptive reaching law based three-dimensional finite-time guidance law against maneuvering targets with input saturation[J]. Aerospace Science and Technology, 2017, 70:198-210.
|
| [9] |
LIU L H, ZHU J W, TANG G J, et al. Diving guidance via feedback linearization and sliding mode control[J]. Aerospace Science and Technology, 2015, 41:16-23.
|
| [10] |
ZUO Z Y. Non-singular fixed-time terminal sliding mode control of non-linear systems[J]. IET Control Theory and Applications, 2015, 9(4):545-552.
|
| [11] |
PAN B F, MA Y Y, YAN R. Newton-type methods in computational guidance[J]. Journal of Guidance,Control,and Dynamics, 2019, 42(2):377-383.
|
| [12] |
LU P. Introducing computational guidance and control[J]. Journal of Guidance,Control,and Dynamics, 2017, 40(2):193.
|
| [13] |
KIM B, LEE C H. Optimal midcourse guidance for dual-pulse rocket using pseudospectral sequential convex programming[J]. Journal of Guidance,Control,and Dynamics, 2023, 46(7):1425-1436.
|
| [14] |
LIU X F, SHEN Z J, LU P. Closed-loop optimization of guidance gain for constrained impact[J]. Journal of Guidance,Control,and Dynamics, 2016, 40(2):453-460.
|
| [15] |
COTTRELL R G, VINCENT T L, SADATI S H. Minimizing interceptor size using neural networks for terminal guidance law synthesis[J]. Journal of Guidance,Control,and Dynamics, 1996, 19(3):557-562.
|
| [16] |
SHI Y, WANG Z B. Onboard generation of optimal trajectories for hypersonic vehicles using deep learning[J]. Journal of Spacecraft and Rockets, 2021, 58(2):400-414.
|
| [17] |
SU L, WANG J, CHEN H. A real-time and optimal hypersonic entry guidance method using inverse reinforcement learning[J]. Aerospace, 2023, 10(11):948.
|
| [18] |
HE S M, SHIN H S, TSOURDOS A. Computational missile guidance:A deep reinforcement learning approach[J]. Journal of Aerospace Information Systems, 2021, 18(8):571-582.
|
| [19] |
李庆波, 李芳, 董瑞星, 等. 利用强化学习开展比例导引律的导航比设计[J]. 兵工学报, 2022, 43(12):3040-3047.
|
|
LI Q B, LI F, DONG R X, et al. Navigation ratio design of proportional navigation law using reinforcement learning[J]. Acta Armamentarii, 2022, 43(12):3040-3047. (in Chinese)
doi: 10.12382/bgxb.2021.0631
|
| [20] |
GAUDET B, FURFARO R, LINARES R. Reinforcement learning for angle-only intercept guidance of maneuvering targets[J]. Aerospace Science and Technology, 2020, 99:105746.
|
| [21] |
LIANG C, WANG W H, LIU Z H, et al. Learning to guide:Guidance law based on deep meta-learning and model predictive path integral control[J]. IEEE Access, 2019, 7:47353-47365.
|
| [22] |
GAUDET B, FURFARO R. Terminal adaptive guidance for autonomous hypersonic strike weapons via reinforcement metalearning[J]. Journal of Spacecraft and Rockets, 2023, 60(1):286-298.
|
| [23] |
LIU X F, LU P, PAN B F. Survey of convex optimization for aerospace applications[J]. Astrodynamics, 2017, 1:23-40.
|
| [24] |
GAUDET B, FURFARO R. Adaptive pinpoint and fuel efficient Mars landing using reinforcement learning[J]. Journal of Automatic Sinica, 2014, 1(4):397-411.
|
| [25] |
LI Y X, LIU X F, HE X H, et al. Cooperative optimal guidance of hypersonic glide vehicles by real-time optimization and deep learning[J]. Proceedings of the Institution of Mechanical Engineers,Part G:Journal of Aerospace Engineering, 2023, 237(10):2266-2283.
|

 )
)
 京公网安备11010802024360号 京ICP备05059581号-4
京公网安备11010802024360号 京ICP备05059581号-4