
主管单位:中国科学技术协会
主办单位:中国兵工学会
ISSN 1000-1093 CN 11-2176/TJ
主办单位:中国兵工学会
ISSN 1000-1093 CN 11-2176/TJ
兵工学报 ›› 2023, Vol. 44 ›› Issue (S2): 101-113.doi: 10.12382/bgxb.2023.0881
所属专题: 群体协同与自主技术
李松1, 麻壮壮1, 张蕴霖1, 邵晋梁1,2,3,*( )
)
收稿日期:2023-09-06
上线日期:2024-01-10
通讯作者:
基金资助:
LI Song1, MA Zhuangzhuang1, ZHANG Yunlin1, SHAO Jinliang1,2,3,*()
Received:2023-09-06
Online:2024-01-10
摘要:
覆盖路径规划的目的是为智能体找到一条安全的轨迹,其不仅可以有效覆盖任务区域,而且可以避开障碍物与邻近智能体。在执行覆盖任务时,复杂的大面积任务区域总是不可避免的。如何在保证智能体安全的前提下加强智能体之间的协同合作,以改善集群任务效率低、能力不足的缺点是值得探索的问题。为此,利用栅格地图建立离散的覆盖路径规划数学模型,提出一种基于值分解网络的安全多智能体强化学习算法,并通过理论证明论证其合理性。该算法通过分解群体价值函数以避免智能体的虚假奖励,有助于加强智能体之间协同覆盖策略的学习,以提高算法的收敛速度。通过在训练过程中引入屏蔽器以修正智能体的出界和碰撞等行为,保证智能体在整个任务过程中的安全。仿真和半实物实验结果表明,新算法不仅可以保证智能体的覆盖效率,同时还能有效维护智能体的安全。
中图分类号:
李松, 麻壮壮, 张蕴霖, 邵晋梁. 基于安全强化学习的多智能体覆盖路径规划[J]. 兵工学报, 2023, 44(S2): 101-113.
LI Song, MA Zhuangzhuang, ZHANG Yunlin, SHAO Jinliang. Multi-agent Coverage Path Planning Based on Security Reinforcement Learning[J]. Acta Armamentarii, 2023, 44(S2): 101-113.
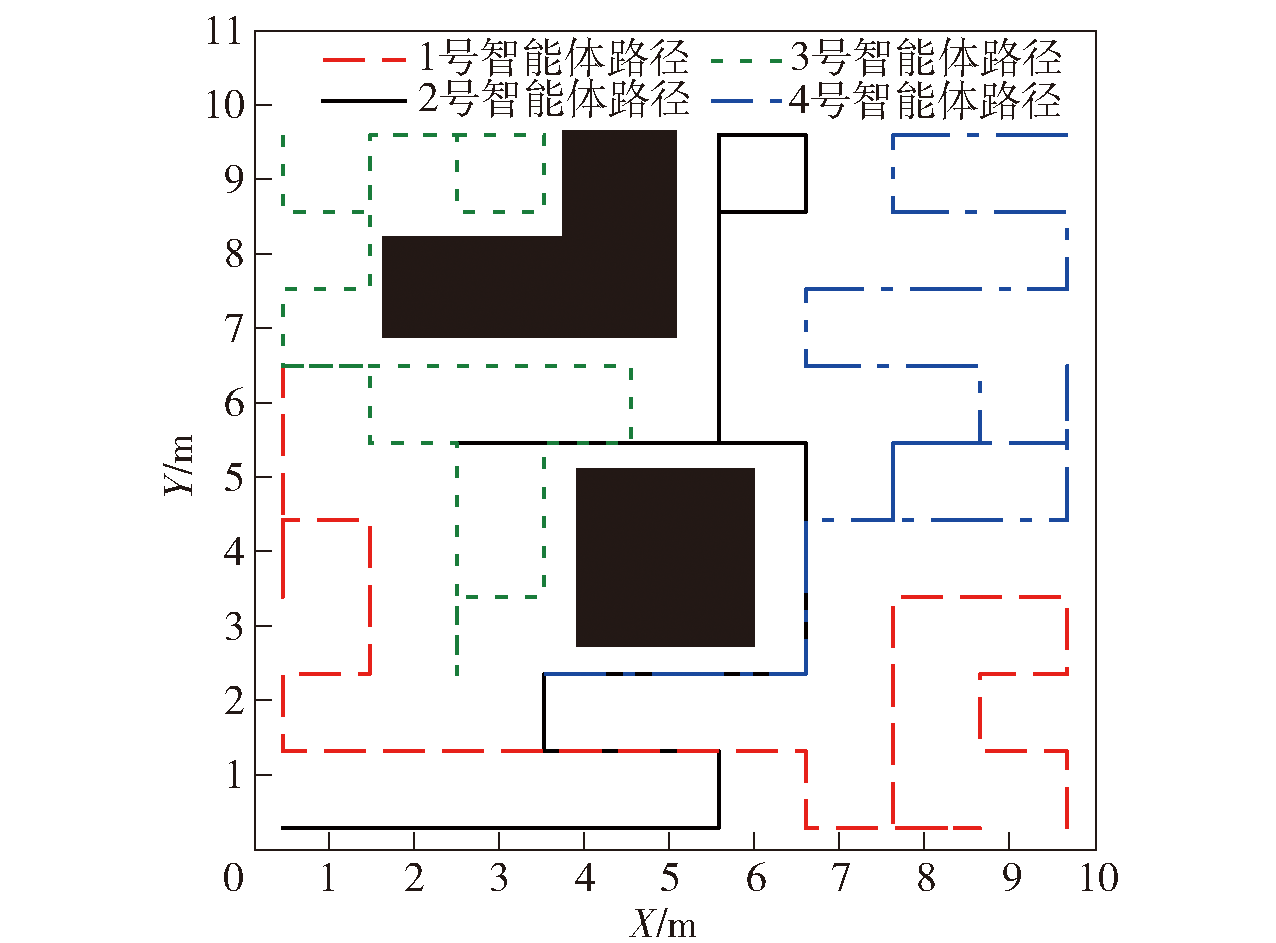
图1 多智能体覆盖路径示意图
Fig.1 Schematic diagram of multi-agent coverage path

图2 栅格化示意图
Fig.2 Schematic diagram of rasterization

图3 VDN算法框架
Fig.3 Framework of VDN algorithm
| 算法1 安全约束模块 |
| 1:收集t时刻智能体i的状态 和预执行动作 2:预测t+1时刻智能体状态 3:if 出界or碰撞do 4: =stop, =-c,c∈R+ 5:else 6: = 7: 执行动作 ,观测奖励 和 8:end if |
| 算法1 安全约束模块 |
| 1:收集t时刻智能体i的状态 和预执行动作 2:预测t+1时刻智能体状态 3:if 出界or碰撞do 4: =stop, =-c,c∈R+ 5:else 6: = 7: 执行动作 ,观测奖励 和 8:end if |

图4 循环神经网络结构
Fig.4 Recurrent neural network structure
| 算法2 ε-贪婪法方法 |
| 1:获取当前轮数episode,随机数rand 2:ε= ×episode+εmin 3:if rand≥ε do 4: =random(A) 5:else 6: =arg ( (st), ) 7:end if |
| 算法2 ε-贪婪法方法 |
| 1:获取当前轮数episode,随机数rand 2:ε= ×episode+εmin 3:if rand≥ε do 4: =random(A) 5:else 6: =arg ( (st), ) 7:end if |
| 算法3 策略网络训练 |
| 1:随机初始化网络 … 参数θ1…θn 2:for episode=1,2,…,episodemax do 3: reset环境, ←0 4: for step=1,2,…,stepmax do 5: for i=1,2,…,N do 6: 根据算法2获取预执行动作 7: 收集 ,根据算法1获取有效样本 8: 更新网络 参数θi 9: end for 10: end for 11: if mean( )≥goalth do 12: break 13: end if 14:end for |
| 算法3 策略网络训练 |
| 1:随机初始化网络 … 参数θ1…θn 2:for episode=1,2,…,episodemax do 3: reset环境, ←0 4: for step=1,2,…,stepmax do 5: for i=1,2,…,N do 6: 根据算法2获取预执行动作 7: 收集 ,根据算法1获取有效样本 8: 更新网络 参数θi 9: end for 10: end for 11: if mean( )≥goalth do 12: break 13: end if 14:end for |
| 超参数 | 值 |
|---|---|
| 网络学习率 | 0.001 |
| 单隐藏层神经元数 | 64 |
| 折扣因子 | 0.99 |
| 网络更新间隔/轮 | 20 |
| 最小贪婪系数 | 0.05 |
| 最大贪婪系数 | 0.95 |
| 到达最大贪婪系数轮数 | 2000 |
| 最大运行轮数 | 2000 |
| 奖励阈值 | 4500 |
| 地图尺寸 | 10 |
| 平均分栈容量 | 100 |
| 最大运行步数 | 30/120 |
| 智能体数量 | 4/1 |
表1 实验中用到的超参数
Table 1 Hyperparameters used in experiments
| 超参数 | 值 |
|---|---|
| 网络学习率 | 0.001 |
| 单隐藏层神经元数 | 64 |
| 折扣因子 | 0.99 |
| 网络更新间隔/轮 | 20 |
| 最小贪婪系数 | 0.05 |
| 最大贪婪系数 | 0.95 |
| 到达最大贪婪系数轮数 | 2000 |
| 最大运行轮数 | 2000 |
| 奖励阈值 | 4500 |
| 地图尺寸 | 10 |
| 平均分栈容量 | 100 |
| 最大运行步数 | 30/120 |
| 智能体数量 | 4/1 |

图5 奖励曲线对比图
Fig.5 Comparison chart of reward curves
| 算法 | 覆盖率/% | 重复率/% |
|---|---|---|
| VDN_safe | 100.0 | 28.1 |
| center_safe | 93.8 | 35.4 |
| singal_safe | 99.0 | 24.0 |
| VDN_unsafe | 99.0 | 30.2 |
| center_unsafe | 89.5 | 39.5 |
| singal_unsafe | 95.8 | 29.1 |
表2 算法覆盖性能对比
Table 2 Comparison of algorithm overlay performances
| 算法 | 覆盖率/% | 重复率/% |
|---|---|---|
| VDN_safe | 100.0 | 28.1 |
| center_safe | 93.8 | 35.4 |
| singal_safe | 99.0 | 24.0 |
| VDN_unsafe | 99.0 | 30.2 |
| center_unsafe | 89.5 | 39.5 |
| singal_unsafe | 95.8 | 29.1 |

图6 各个算法的覆盖路径曲线
Fig.6 Coverage path curves for each algorithm
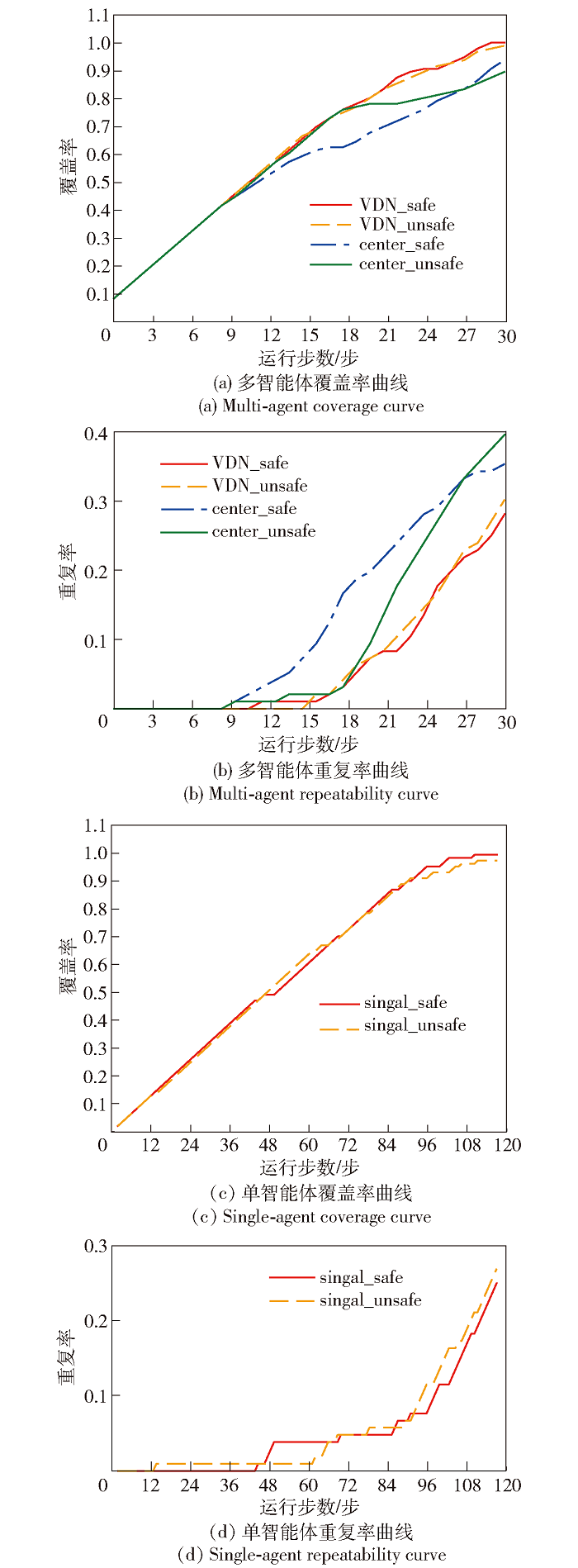
图7 覆盖效率对比图
Fig.7 Coverage efficiency comparison chart

图8 有无安全约束的奖励曲线对比图
Fig.8 Comparison chart of reward curves with and without security constraints

图9 狭小空间地图中有无安全约束的覆盖路径对比图
Fig.9 Comparison of coverage paths with and without safety constraints in a map with tight spaces

图10 改变障碍物的数量和位置后的覆盖路径曲线
Fig.10 Coverage path curve after changing the number and position of obstacles

图11 扩大区域面积后的覆盖路径曲线
Fig.11 Coverage path curve after expanding the area

图12 扩大区域面积并增加障碍物的覆盖路径曲线
Fig.12 Coverage path curve after expanding the area and increasing the obstacle
| 实验 | 覆盖率/% | 重复率/% |
|---|---|---|
| 10×10单障碍物 | 100.0 | 28.1 |
| 10×10多障碍物 | 100.0 | 32.6 |
| 20×20单障碍物 | 99.5 | 22.0 |
| 20×20多障碍物 | 98.9 | 22.9 |
表3 对比实验结果
Table 3 Results of the comparative experiments
| 实验 | 覆盖率/% | 重复率/% |
|---|---|---|
| 10×10单障碍物 | 100.0 | 28.1 |
| 10×10多障碍物 | 100.0 | 32.6 |
| 20×20单障碍物 | 99.5 | 22.0 |
| 20×20多障碍物 | 98.9 | 22.9 |
| 智能体个数 | 覆盖率/% | 重复率/% |
|---|---|---|
| 3 | 97.9 | 26.5 |
| 4 | 98.9 | 22.9 |
| 5 | 98.9 | 24.2 |
| 6 | 99.2 | 25.5 |
表4 不同智能体个数的覆盖性能
Table 4 Coverage performances of different number of agents
| 智能体个数 | 覆盖率/% | 重复率/% |
|---|---|---|
| 3 | 97.9 | 26.5 |
| 4 | 98.9 | 22.9 |
| 5 | 98.9 | 24.2 |
| 6 | 99.2 | 25.5 |

图13 半实物平台框架示意图
Fig.13 Schematic diagram of semi-physical platform frame

图14 控制器结构
Fig.14 Controller structure

图15 半实物仿真示意图
Fig.15 Schematic diagram of semi-physical simulation

图16 规划轨迹与无人车实际运动轨迹对比图
Fig.16 Comparison chart of planning path and actual path of unmanned ground vehicle
| [1] |
doi: 10.1109/ACCESS.2021.3108177 URL |
| [2] |
李波, 杨志鹏, 贾卓然, 等. 一种无监督学习型神经网络的无人机全区域侦察路径规划[J]. 西北工业大学学报, 2021, 39(1):77-84.
|
|
doi: 10.1051/jnwpu/20213910077 URL |
|
| [3] |
吴文超, 黄长强, 宋磊, 等. 不确定环境下的多无人机协同搜索航路规划[J]. 兵工学报, 2011, 32(11): 1337-1342.
|
|
|
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
李御驰, 闫军涛, 宋志华, 等. 基于遗传算法的无人机监视覆盖航路规划算法研究[J]. 计算机科学与应用, 2019, 9(6): 1208-1215.
|
|
doi: 10.12677/CSA.2019.96135 URL |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
张伟, 王乃新, 魏世琳, 等. 水下无人潜航器集群发展现状及关键技术综述[J]. 哈尔滨工程大学学报, 2020, 41(2): 289-297.
|
|
|
|
| [17] |
罗志远, 刘小峰, 陈俊风, 等. 一种基于分步遗传算法的多无人清洁车区域覆盖路径规划方法[J]. 电子测量与仪器学报, 2020, 34(8):43-50.
|
|
|
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
王雪松, 王荣荣, 程玉虎. 安全强化学习综述[J]. 自动化学报, 2023, 49(9): 1813-1835.
|
|
|
|
| [22] |
doi: 10.1017/S0269888912000057 URL |
| [23] |
|
| [24] |
|
| [1] | 张继雄, 李宗刚, 宁小刚, 陈引娟. 动态事件触发下一般线性多智能体系统完全分布式一致性控制[J]. 兵工学报, 2023, 44(S2): 223-234. |
| [2] | 于镝, 王亚洁, 赵博, 刘琼. 动态事件触发机制下多智能体系统固定时间跟踪[J]. 兵工学报, 2023, 44(5): 1403-1413. |
| [3] | 孔国杰, 冯时, 于会龙, 巨志扬, 龚建伟. 无人集群系统协同运动规划技术综述[J]. 兵工学报, 2023, 44(1): 11-26. |
| [4] | 周绍磊, 赵学远, 祁亚辉, 王帅磊. 有向切换拓扑条件下考虑暂态响应的多智能体H∞一致性控制[J]. 兵工学报, 2020, 41(2): 356-365. |
| [5] | 曹昊哲, 吴炎烜, 周峰, 王正杰. 带有避碰机制的2阶非线性多智能体系统包围编队研究[J]. 兵工学报, 2016, 37(9): 1646-1654. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
 京公网安备11010802024360号 京ICP备05059581号-4
京公网安备11010802024360号 京ICP备05059581号-4