
主管单位:中国科学技术协会
主办单位:中国兵工学会
ISSN 1000-1093 CN 11-2176/TJ
主办单位:中国兵工学会
ISSN 1000-1093 CN 11-2176/TJ
兵工学报 ›› 2024, Vol. 45 ›› Issue (12): 4372-4382.doi: 10.12382/bgxb.2023.0982
董明泽, 温庄磊, 陈锡爱*( ), 杨炅坤, 曾涛
), 杨炅坤, 曾涛
收稿日期:2023-09-27
上线日期:2024-02-27
通讯作者:
基金资助:
DONG Mingze, WEN Zhuanglei, CHEN Xiai*(), YANG Jiongkun, ZENG Tao
Received:2023-09-27
Online:2024-02-27
摘要:
针对机器人在全局地图未知且环境内存在动态和静态障碍物场景中的导航问题,提出一种基于深度强化学习(Deep Reinforcement Learning,DRL)的移动机器人导航方法。相较于其他应用于复杂动态环境的DRL机器人导航方法,该方法在动作空间设计、状态空间设计和奖励函数设计上进行了改进,并采用了控制环节与神经网络分离的设计,有助于将仿真研究便捷有效地实现在各类机器人的实际应用中。在动作空间设计上,为缩小可行轨迹的采样空间并同时满足短期动态避障和长期的全局导航需求,将通过激光点云数据计算得到的安全凸空间与机器人运动学极限的交集设定为机器人的动作空间,并从该动作空间中采样出参考位置点形成参考路径,而后机器人通过模型预测控制算法对参考路径进行跟踪。在状态空间和奖励函数的设计上,额外添加了安全凸空间、长短期参考位置点等元素。消融实验结果表明,该设计在各种静态和动态环境中都能达到更高的导航成功率、更短的耗时,并且具有较强的泛化能力。
中图分类号:
董明泽, 温庄磊, 陈锡爱, 杨炅坤, 曾涛. 安全凸空间与深度强化学习结合的机器人导航方法[J]. 兵工学报, 2024, 45(12): 4372-4382.
DONG Mingze, WEN Zhuanglei, CHEN Xiai, YANG Jiongkun, ZENG Tao. Research on Robot Navigation Method Integrating Safe Convex Space and Deep Reinforcement Learning[J]. Acta Armamentarii, 2024, 45(12): 4372-4382.

图1 迭代求解过程
Fig.1 Iterative solution procedure

图2 短期可达交集空间与长期可达交集空间
Fig.2 Short-term and long-term reachable intersection spaces

图3 短期参考位置计算
Fig.3 Short-term reference position calculation

图4 长短期参考位置计算
Fig.4 Long-term reference position calculation

图5 状态空间观测量示意图
Fig.5 Schematic diagram of state-space observations

图6 基于全局路径的势能塑形回报示意图
Fig.6 Schematic diagram of potential energy shaping reward based on global path

图7 状态价值网络设计
Fig.7 Design of state value network

图8 策略网络设计
Fig.8 Design of strategy network
| 阶段 | 环境 尺寸/m | 静态障碍 物个数 | 动态障碍 物个数 | 动态障碍 物半径/m | 动态障碍物 速度/(m·s-1) |
|---|---|---|---|---|---|
| 1 | 20×30 | 0 | 0 | ||
| 2 | 20×30 | 10 | 0 | ||
| 3 | 20×30 | 10 | 5 | 0.2~0.3 | 0.3 |
| 4 | 20×30 | 10 | 10 | 0.2~0.3 | 0.3 |
| 5 | 10×10 | 0 | 10 | 0.1~0.4 | 0.3~0.6 |
| 6 | 10×10 | 0 | 20 | 0.1~0.4 | 0.3~0.6 |
| 7 | 10×10 | 0 | 30 | 0.1~0.4 | 0.3~0.6 |
表1 分阶段训练环境设计表
Table 1 Staged training environment parameter settings
| 阶段 | 环境 尺寸/m | 静态障碍 物个数 | 动态障碍 物个数 | 动态障碍 物半径/m | 动态障碍物 速度/(m·s-1) |
|---|---|---|---|---|---|
| 1 | 20×30 | 0 | 0 | ||
| 2 | 20×30 | 10 | 0 | ||
| 3 | 20×30 | 10 | 5 | 0.2~0.3 | 0.3 |
| 4 | 20×30 | 10 | 10 | 0.2~0.3 | 0.3 |
| 5 | 10×10 | 0 | 10 | 0.1~0.4 | 0.3~0.6 |
| 6 | 10×10 | 0 | 20 | 0.1~0.4 | 0.3~0.6 |
| 7 | 10×10 | 0 | 30 | 0.1~0.4 | 0.3~0.6 |
| 方法 | 成功率/% | 导航时间/s | 导航路程/m | 速度/(m·s-1) | 加速度/(m·s-2) | 加加速度/(m·s-3) | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | ||||||||||||||
| 设计1 | 76.0 | 4.0 | 2.2 | 11.3 | 6.3 | 2.9 | 0.3 | 0 | 1.0 | -0.6 | 11.8 | ||||||||||||
| 设计2 | 76.0 | 4.0 | 2.2 | 11.3 | 6.3 | 2.8 | 0.2 | 0 | 1.5 | -0.1 | 22.5 | ||||||||||||
| 设计3 | 90.3 | 9.0 | 5.2 | 15.2 | 8.3 | 2.8 | 0.2 | 0.3 | 1.9 | -0.1 | 7.0 | ||||||||||||
| 设计4 | 83.0 | 5.0 | 2.6 | 11.7 | 6.3 | 2.2 | 0.4 | 0.5 | 1.3 | -0.2 | 4.8 | ||||||||||||
| 本文方法 | 89.2 | 5.0 | 2.6 | 12.2 | 6.6 | 2.2 | 0.4 | 0.3 | 1.4 | -0.5 | 4.0 | ||||||||||||
表2 阶段2场景导航性能指标统计表
Table 2 Stage 2 scenario navigation performance metrics statistics
| 方法 | 成功率/% | 导航时间/s | 导航路程/m | 速度/(m·s-1) | 加速度/(m·s-2) | 加加速度/(m·s-3) | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | ||||||||||||||
| 设计1 | 76.0 | 4.0 | 2.2 | 11.3 | 6.3 | 2.9 | 0.3 | 0 | 1.0 | -0.6 | 11.8 | ||||||||||||
| 设计2 | 76.0 | 4.0 | 2.2 | 11.3 | 6.3 | 2.8 | 0.2 | 0 | 1.5 | -0.1 | 22.5 | ||||||||||||
| 设计3 | 90.3 | 9.0 | 5.2 | 15.2 | 8.3 | 2.8 | 0.2 | 0.3 | 1.9 | -0.1 | 7.0 | ||||||||||||
| 设计4 | 83.0 | 5.0 | 2.6 | 11.7 | 6.3 | 2.2 | 0.4 | 0.5 | 1.3 | -0.2 | 4.8 | ||||||||||||
| 本文方法 | 89.2 | 5.0 | 2.6 | 12.2 | 6.6 | 2.2 | 0.4 | 0.3 | 1.4 | -0.5 | 4.0 | ||||||||||||

图9 阶段2场景下不同方法导航结果展示
Fig.9 Demonstration of the navigation results of different methods in Stage 2 scenario
| 方法 | 成功率/% | 导航时间/s | 导航路程/m | 速度/(m·s-1) | 加速度/(m·s-2) | 加加速度/(m·s-3) | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | ||
| 设计1 | 80 | 4.0 | 2.2 | 11.4 | 6.2 | 2.9 | 0.3 | -0.1 | 1.3 | -0.1 | 16.9 |
| 设计2 | 79 | 4.0 | 2.1 | 11.4 | 6.2 | 2.9 | 0.2 | -0.1 | 2.2 | 0.0 | 35.9 |
| 设计3 | 88 | 8.8 | 5.0 | 15.4 | 8.6 | 1.8 | 0.4 | 0.3 | 1.8 | -0.1 | 6.6 |
| 设计4 | 84 | 4.9 | 2.4 | 11.6 | 6.3 | 2.2 | 0.4 | 0.5 | 1.3 | -0.3 | 4.9 |
| 本文方法 | 89 | 5.9 | 3.3 | 13.0 | 7.3 | 2.2 | 0.4 | 0.3 | 1.4 | -0.5 | 4.2 |
表3 阶段3场景导航性能指标统计表
Table 3 Stage 3 scenario navigation performance metrics statistics
| 方法 | 成功率/% | 导航时间/s | 导航路程/m | 速度/(m·s-1) | 加速度/(m·s-2) | 加加速度/(m·s-3) | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | ||
| 设计1 | 80 | 4.0 | 2.2 | 11.4 | 6.2 | 2.9 | 0.3 | -0.1 | 1.3 | -0.1 | 16.9 |
| 设计2 | 79 | 4.0 | 2.1 | 11.4 | 6.2 | 2.9 | 0.2 | -0.1 | 2.2 | 0.0 | 35.9 |
| 设计3 | 88 | 8.8 | 5.0 | 15.4 | 8.6 | 1.8 | 0.4 | 0.3 | 1.8 | -0.1 | 6.6 |
| 设计4 | 84 | 4.9 | 2.4 | 11.6 | 6.3 | 2.2 | 0.4 | 0.5 | 1.3 | -0.3 | 4.9 |
| 本文方法 | 89 | 5.9 | 3.3 | 13.0 | 7.3 | 2.2 | 0.4 | 0.3 | 1.4 | -0.5 | 4.2 |

图10 阶段3场景下不同方法导航结果展示
Fig.10 Demonstration of the navigation results of different methods in Stage 3 scenario
| 方法 | 成功率/% | 导航时间/s | 导航路程/m | 速度/(m·s-1) | 加速度/(m·s-2) | 加加速度/(m·s-3) | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | ||
| 设计1 | 81 | 3.9 | 2.2 | 11.2 | 6.5 | 2.9 | 0.3 | -0.1 | 1.7 | -0.4 | 24.7 |
| 设计2 | 75 | 3.8 | 2.2 | 10.8 | 6.3 | 2.9 | 0.3 | -0.1 | 2.1 | 0.4 | 32.9 |
| 设计3 | 85 | 9.0 | 5.4 | 15.1 | 8.7 | 1.7 | 0.4 | 0.3 | 1.8 | -0.1 | 6.5 |
| 设计4 | 84 | 4.8 | 2.5 | 11.5 | 6.5 | 2.2 | 0.4 | 0.6 | 1.3 | -0.3 | 4.8 |
| 本文方法 | 86 | 5.8 | 3.3 | 12.5 | 7.1 | 2.1 | 0.4 | 0.3 | 1.4 | -0.5 | 4.3 |
表4 阶段4场景导航性能指标统计表
Table 4 Stage 4 scenario navigation performance metrics statistics
| 方法 | 成功率/% | 导航时间/s | 导航路程/m | 速度/(m·s-1) | 加速度/(m·s-2) | 加加速度/(m·s-3) | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | ||
| 设计1 | 81 | 3.9 | 2.2 | 11.2 | 6.5 | 2.9 | 0.3 | -0.1 | 1.7 | -0.4 | 24.7 |
| 设计2 | 75 | 3.8 | 2.2 | 10.8 | 6.3 | 2.9 | 0.3 | -0.1 | 2.1 | 0.4 | 32.9 |
| 设计3 | 85 | 9.0 | 5.4 | 15.1 | 8.7 | 1.7 | 0.4 | 0.3 | 1.8 | -0.1 | 6.5 |
| 设计4 | 84 | 4.8 | 2.5 | 11.5 | 6.5 | 2.2 | 0.4 | 0.6 | 1.3 | -0.3 | 4.8 |
| 本文方法 | 86 | 5.8 | 3.3 | 12.5 | 7.1 | 2.1 | 0.4 | 0.3 | 1.4 | -0.5 | 4.3 |
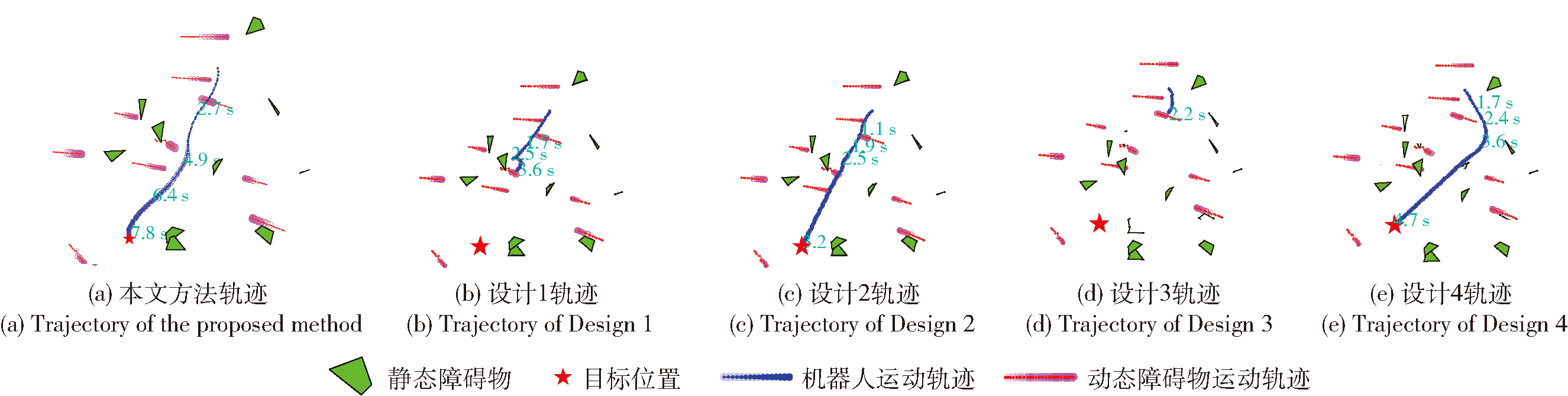
图11 阶段4场景下不同方法导航结果展示
Fig.11 Demonstration of the navigation results of different methods in Stage 4 scenario
| 奖励函数 | 阶段 | 成功率 | 导航时间/s | 导航路程/m | 速度/(m·s-1) | 加速度/(m·s-2) | 加加速度/(m·s-3) | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | |||
| 5 | 87 | 2.8 | 1.6 | 4.6 | 2.5 | 1.6 | 0.4 | 0.6 | 1.4 | -0.9 | 4.1 | |
| rt1 | 6 | 77 | 2.8 | 1.8 | 4.1 | 2.4 | 1.4 | 0.4 | 0.6 | 1.4 | 1.4 | 4.1 |
| 7 | 68 | 3.1 | 2.1 | 4.2 | 2.5 | 1.4 | 0.4 | 0.5 | 1.3 | -0.7 | 4.3 | |
| 5 | 87 | 2.9 | 1.7 | 4.6 | 2.5 | 1.6 | 0.4 | 0.6 | 1.4 | -0.9 | 4.0 | |
| rt2 | 6 | 75 | 3.0 | 1.8 | 4.3 | 2.4 | 1.5 | 0.4 | 0.6 | 1.4 | -0.8 | 4.2 |
| 7 | 65 | 2.9 | 2.0 | 3.9 | 2.2 | 1.4 | 0.4 | 0.6 | 1.3 | -0.8 | 4.2 | |
表5 rt1和rt2阶段5~阶段7场景下导航性能统计表
Table 5 Reward functions rt1 and rt2 navigation performance statistics in the scenarios at Stages 5 to 7
| 奖励函数 | 阶段 | 成功率 | 导航时间/s | 导航路程/m | 速度/(m·s-1) | 加速度/(m·s-2) | 加加速度/(m·s-3) | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | |||
| 5 | 87 | 2.8 | 1.6 | 4.6 | 2.5 | 1.6 | 0.4 | 0.6 | 1.4 | -0.9 | 4.1 | |
| rt1 | 6 | 77 | 2.8 | 1.8 | 4.1 | 2.4 | 1.4 | 0.4 | 0.6 | 1.4 | 1.4 | 4.1 |
| 7 | 68 | 3.1 | 2.1 | 4.2 | 2.5 | 1.4 | 0.4 | 0.5 | 1.3 | -0.7 | 4.3 | |
| 5 | 87 | 2.9 | 1.7 | 4.6 | 2.5 | 1.6 | 0.4 | 0.6 | 1.4 | -0.9 | 4.0 | |
| rt2 | 6 | 75 | 3.0 | 1.8 | 4.3 | 2.4 | 1.5 | 0.4 | 0.6 | 1.4 | -0.8 | 4.2 |
| 7 | 65 | 2.9 | 2.0 | 3.9 | 2.2 | 1.4 | 0.4 | 0.6 | 1.3 | -0.8 | 4.2 | |
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
王霄龙, 陈洋, 胡棉, 等. 基于改进深度Q网络的机器人持续监测路径规划[J]. 兵工学报, 2024, 45(6):1813-1823.
doi: 10.12382/bgxb.2023.0227 |
|
|
|
| [6] |
董豪, 杨静, 李少波, 等. 基于深度强化学习的机器人运动控制研究进展[J]. 控制与决策, 2022, 37(2):278-292.
|
|
|
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
黄昱洲, 王立松, 秦小麟. 一种基于深度强化学习的无人小车双层路径规划方法[J]. 计算机科学, 2023, 50(1):194-204.
doi: 10.11896/jsjkx.220500241 |
|
doi: 10.11896/jsjkx.220500241 |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [1] | 陈琦, 覃国样. 混合驱动水下机器人浮游与爬行双模式轨迹跟踪控制[J]. 兵工学报, 2024, 45(9): 3216-3229. |
| [2] | 孙浩, 黎海青, 梁彦, 马超雄, 吴翰. 基于知识辅助深度强化学习的巡飞弹组动态突防决策[J]. 兵工学报, 2024, 45(9): 3161-3176. |
| [3] | 任宏斌, 孙纪禹, 陈志铿, 赵玉壮, 杨林. 基于线性时变模型预测控制的实时抗噪高速车辆运动控制[J]. 兵工学报, 2024, 45(12): 4311-4322. |
| [4] | 王绪, 高晓宇, 黄英, 崔涛, 骆承良. 模型失配条件下混合动力两栖车功率协调预测控制[J]. 兵工学报, 2024, 45(12): 4578-4588. |
| [5] | 邢伯阳, 许威, 李宇峰, 赵浩宇, 王康, 闫曈. 基于分层解耦的四轮足机器人模型预测控制[J]. 兵工学报, 2024, 45(12): 4272-4282. |
| [6] | 王天翔, 崔涛, 张付军, 赵彦凯. 基于MPC的电动复合增压柴油机进气压力控制[J]. 兵工学报, 2024, 45(10): 3642-3653. |
| [7] | 傅妍芳, 雷凯麟, 魏佳宁, 曹子建, 杨博, 王炜, 孙泽龙, 李秦洁. 基于演员-评论家框架的层次化多智能体协同决策方法[J]. 兵工学报, 2024, 45(10): 3385-3396. |
| [8] | 刘江涛, 周乐来, 李贻斌. 复杂地形六轮独立驱动与转向机器人轨迹跟踪与避障控制[J]. 兵工学报, 2024, 45(1): 166-183. |
| [9] | 许鹏, 邢伯阳, 刘宇飞, 李泳耀, 曾怡, 郑冬冬. 基于扩张状态观测器和模型预测方法的四足机器人抗干扰复合控制[J]. 兵工学报, 2023, 44(S2): 12-21. |
| [10] | 李曹妍, 郭振川, 郑冬冬, 魏延岭. 基于分布式模型预测控制的多机器人协同编队[J]. 兵工学报, 2023, 44(S2): 178-190. |
| [11] | 张渊博, 项昌乐, 王伟达, 陈泳丹. 基于粒子群优化-蚁群融合算法的分布式电驱动车辆模型预测转矩协调控制策略[J]. 兵工学报, 2023, 44(11): 3253-3258. |
| [12] | 蒋岩, 丁语嫣, 张兴龙, 徐昕. 基于模型预测与策略学习的智能车辆人机协同控制算法[J]. 兵工学报, 2023, 44(11): 3465-3477. |
| [13] | 唐泽月, 刘海鸥, 薛明轩, 陈慧岩, 龚小杰, 陶俊峰. 基于MPC-MFAC的双侧独立电驱动无人履带车辆轨迹跟踪控制[J]. 兵工学报, 2023, 44(1): 129-139. |
| [14] | 宋佳睿, 陶刚, 李德润, 臧政, 吴绍斌, 龚建伟. 参数自优化的有人与无人车辆编队鲁棒模型预测控制[J]. 兵工学报, 2023, 44(1): 84-97. |
| [15] | 周球, 周悦, 孙洪鸣, 郭威, 吴凯, 兰彦军. 深海着陆车路径规划及跟踪控制方法[J]. 兵工学报, 2023, 44(1): 298-306. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
 京公网安备11010802024360号 京ICP备05059581号-4
京公网安备11010802024360号 京ICP备05059581号-4