
主管单位:中国科学技术协会
主办单位:中国兵工学会
ISSN 1000-1093 CN 11-2176/TJ
主办单位:中国兵工学会
ISSN 1000-1093 CN 11-2176/TJ
兵工学报 ›› 2024, Vol. 45 ›› Issue (11): 3856-3867.doi: 10.12382/bgxb.2023.1048
李加申, 王晓芳*( ), 林海
), 林海
收稿日期:2024-01-26
上线日期:2024-01-26
通讯作者:
基金资助:
LI Jiashen, WANG Xiaofang*(), LIN Hai
Received:2024-01-26
Online:2024-01-26
摘要:
针对高超声速巡航导弹机动突防时弹道偏离难以约束、突防策略对不同作战场景的泛化性能较差等问题,提出一种基于虚拟目标和上下文马尔可夫决策过程的智能机动突防决策算法。在以预定弹道为轴线的管状弹道包络面内选定多个静止的虚拟目标,采用深度强化学习算法对其相对预定弹道的位置参数进行决策;用比例导引律引导巡航弹依次攻击这些虚拟目标,在包络面内塑造出能满足突防要求的机动弹道。基于上下文马尔可夫决策过程,将针对单个作战场景的最优突防策略拓展到作战场景的概率分布上,提升突防策略对不同作战场景的适应性。仿真结果表明:该智能机动突防策略能在突防的同时约束弹道偏离,在拦截弹发射位置和机动能力发生变化时仍能保持良好性能。
中图分类号:
李加申, 王晓芳, 林海. 引入虚拟目标的高超声速巡航导弹智能机动突防策略[J]. 兵工学报, 2024, 45(11): 3856-3867.
LI Jiashen, WANG Xiaofang, LIN Hai. Intelligent Penetration Policy for Hypersonic Cruise Missiles Based on Virtual Targets[J]. Acta Armamentarii, 2024, 45(11): 3856-3867.

图1 拦截弹-巡航弹-虚拟目标相对运动关系图
Fig.1 Interceptor-cruise missile-virtual target relative motion diagram
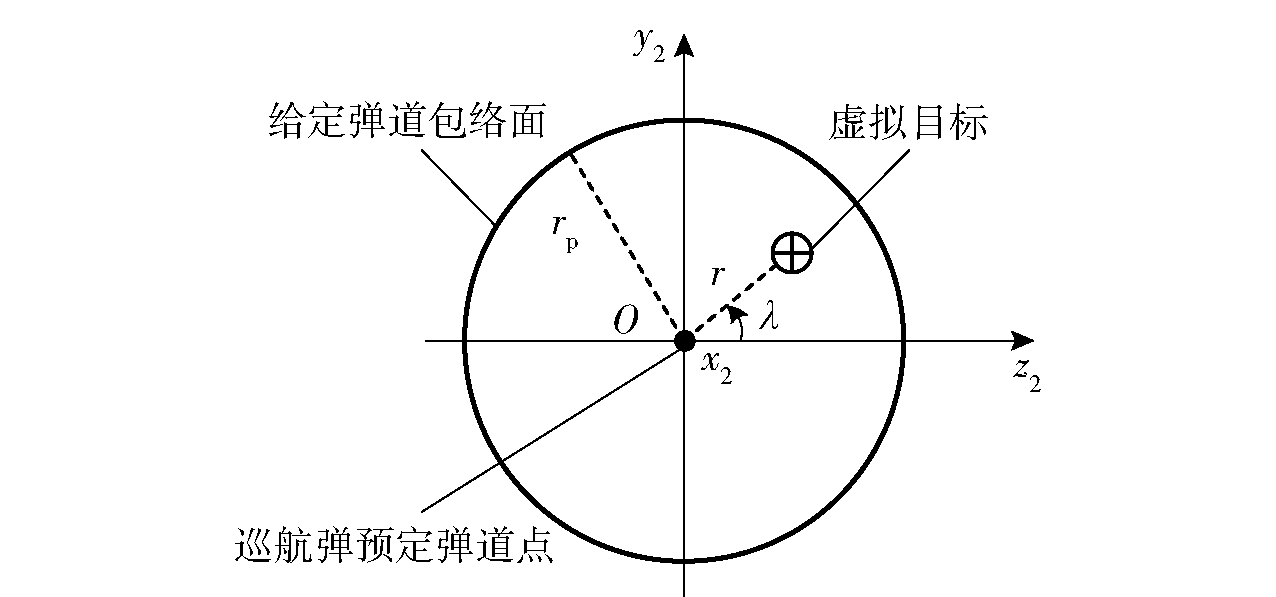
图2 虚拟目标位置示意图
Fig.2 Virtual target location diagram

图3 Actor网络结构
Fig.3 Architecture for Actor network
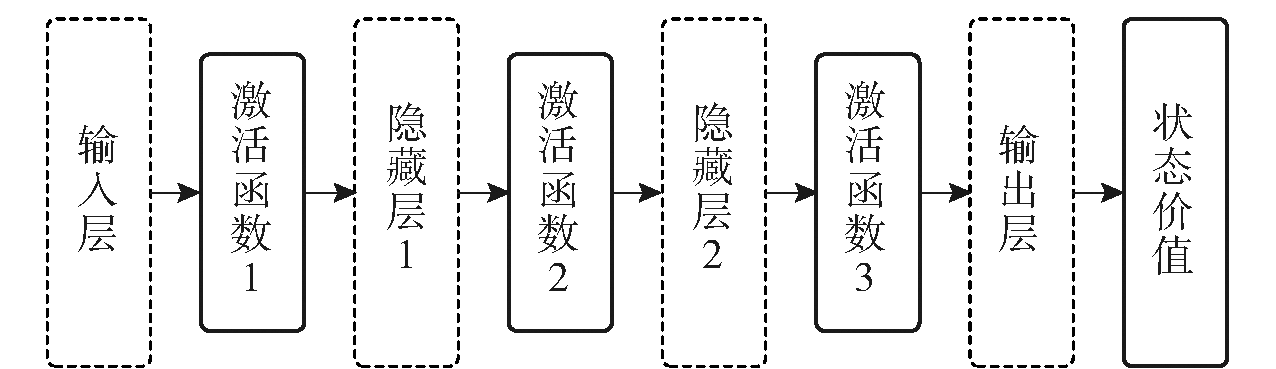
图4 Critic网络结构
Fig.4 Architecture for Critic network

图5 Actor和Critic网络训练方法
Fig.5 Training methods for Actor and Critic networks
| 参数 | Actor | Critic |
|---|---|---|
| 输入层 | 7、10 | 7、10 |
| 激活函数1 | ReLU | ReLU |
| 隐藏层1 | 512 | 512 |
| 激活函数2 | ReLU | ReLU |
| 隐藏层2 | 256 | 256 |
| 激活函数3 | ReLU | ReLU |
| α、β优化层 | 256 | |
| 激活函数4和5 | Softplus | |
| 输出层 | 2 | 1 |
表1 网络结构超参数设置
Table 1 Hyperparameters of network architecture
| 参数 | Actor | Critic |
|---|---|---|
| 输入层 | 7、10 | 7、10 |
| 激活函数1 | ReLU | ReLU |
| 隐藏层1 | 512 | 512 |
| 激活函数2 | ReLU | ReLU |
| 隐藏层2 | 256 | 256 |
| 激活函数3 | ReLU | ReLU |
| α、β优化层 | 256 | |
| 激活函数4和5 | Softplus | |
| 输出层 | 2 | 1 |
| 参数 | 数值 |
|---|---|
| BatchSize | 140 |
| MiniBatchSize | 70 |
| 训练回合数 | 2000 |
| 奖励折扣因子γ | 0.9 |
| GAE平滑因子λ | 0.9 |
| Epoch | 4 |
| 策略熵系数ke | 0.005 |
| 重要性采样权重裁剪因子ε | 0.2 |
| 初始学习率 | 0.015 |
| 学习率衰减节点 | 20、40、60、80 |
| 学习率衰减因子 | 0.6 |
表2 网络训练超参数设置
Table 2 Hyperparameters for network training
| 参数 | 数值 |
|---|---|
| BatchSize | 140 |
| MiniBatchSize | 70 |
| 训练回合数 | 2000 |
| 奖励折扣因子γ | 0.9 |
| GAE平滑因子λ | 0.9 |
| Epoch | 4 |
| 策略熵系数ke | 0.005 |
| 重要性采样权重裁剪因子ε | 0.2 |
| 初始学习率 | 0.015 |
| 学习率衰减节点 | 20、40、60、80 |
| 学习率衰减因子 | 0.6 |

图6 策略的平均累计奖励
Fig.6 Average cumulative reward of the policies

图7 策略在Ctrain各个上下文中的hm
Fig.7 hm of the policies in each context of Ctrain

图8 策略在Ctrain各个上下文中的
Fig.8 τm of the policies in each context of Ctrain

图9 4种突防策略的性能对比
Fig.9 Performance comparison of four policies

图10 虚拟目标的径向距离
Fig.10 Radial distance of virtual target

图11 虚拟目标的周向扭转角
Fig.11 Rotation angle of virtual target

图12 拦截弹的速度矢量前置角
Fig.12 Lead angle of velocity vector for interceptor

图13 巡航弹加速度变化图
Fig.13 Change in acceleration of cruise missile

图14 拦截弹加速度变化图
Fig.14 Change in acceleration of interceptor

图15 攻防双方飞行器机动弹道
Fig.15 Maneuvering trajectories of both vehicles

图16 包络面内的巡航弹机动弹道和虚拟目标
Fig.16 Maneuvering trajectories of the cruise missile and the virtual targets within the envelope
| [1] |
雷虎民, 骆长鑫, 周池军, 等. 临近空间防御作战拦截弹制导与控制关键技术综述[J]. 航空兵器, 2021, 28(2):1-10.
|
|
|
|
| [2] |
汪丰麟, 李沁远, 范博, 等. 高超声速武器防御体系的发展现状与演进趋势[J]. 指挥与控制学报, 2022, 8(4):378-388.
|
|
|
|
| [3] |
张荣升, 陈万春. THAAD增程型拦截弹预测制导方法[J]. 北京航空航天大学学报, 2021, 47(4):863-874.
|
|
|
|
| [4] |
石安华, 李海燕, 石卫波, 等. 临近空间高超声速巡航飞行器红外特征[J]. 兵工学报, 2022, 43(4):796-803.
|
|
doi: 10.12382/bgxb.2021.0105 |
|
| [5] |
|
| [6] |
|
| [7] |
郭行, 符文星, 付斌, 等. 吸气式高超声速飞行器巡航段突防弹道规划[J]. 宇航学报, 2017, 38(3):287-295.
|
|
|
|
| [8] |
王雨琪, 宁国栋, 王晓峰, 等. 基于微分对策的临近空间飞行器机动突防策略[J]. 航空学报, 2020, 41(增刊2):724276.
|
|
|
|
| [9] |
|
| [10] |
|
| [11] |
王芳, 林涛, 张克. 基于控制变量参数化的主动反拦截突防最优控制计算方法[J]. 航空学报, 2015, 36(6):2037-2046.
doi: 10.7527/S1000-6893.2014.0359 |
|
doi: 10.7527/S1000-6893.2014.0359 |
|
| [12] |
樊博璇, 陈桂明, 林洪涛. 弹道导弹中段反应式机动突防规避策略[J]. 兵工学报, 2022, 43(1):69-78.
|
|
doi: 10.3969/j.issn.1000-1093.2022.01.008 |
|
| [13] |
|
| [14] |
张晚晴, 余文斌, 李静琳, 等. 基于纵程解析解的飞行器智能横程机动再入协同制导[J]. 兵工学报, 2021, 42(7): 1400-1411.
|
|
doi: 10.3969/j.issn.1000-1093.2021.07.007 |
|
| [15] |
|
| [16] |
吴杰, 张成, 李淼, 等. 基于凸优化和LQR的火箭返回轨迹跟踪制导[J]. 北京航空航天大学学报, 2022, 48(11):2270-2280.
|
|
|
|
| [17] |
|
| [18] |
王琦, 杨毅远, 江季. Easy RL:强化学习教程[M]. 北京: 人民邮电出版社, 2022:37-98.
|
|
|
|
| [19] |
|
| [20] |
|
| [21] |
|
| [1] | 胡砚洋, 何凡, 白成超. 高超声速飞行器末制导段协同避障决策方法[J]. 兵工学报, 2024, 45(9): 3147-3160. |
| [2] | 孙浩, 黎海青, 梁彦, 马超雄, 吴翰. 基于知识辅助深度强化学习的巡飞弹组动态突防决策[J]. 兵工学报, 2024, 45(9): 3161-3176. |
| [3] | 陈文杰, 崔小红, 王斌锐. 安全最优跟踪控制算法与机械手仿真[J]. 兵工学报, 2024, 45(8): 2688-2697. |
| [4] | 王霄龙, 陈洋, 胡棉, 李旭东. 基于改进深度Q网络的机器人持续监测路径规划[J]. 兵工学报, 2024, 45(6): 1813-1823. |
| [5] | 傅妍芳, 雷凯麟, 魏佳宁, 曹子建, 杨博, 王炜, 孙泽龙, 李秦洁. 基于演员-评论家框架的层次化多智能体协同决策方法[J]. 兵工学报, 2024, 45(10): 3385-3396. |
| [6] | 李松, 麻壮壮, 张蕴霖, 邵晋梁. 基于安全强化学习的多智能体覆盖路径规划[J]. 兵工学报, 2023, 44(S2): 101-113. |
| [7] | 曹子建, 孙泽龙, 闫国闯, 傅妍芳, 杨博, 李秦洁, 雷凯麟, 高领航. 基于强化学习的无人机集群对抗策略推演仿真[J]. 兵工学报, 2023, 44(S2): 126-134. |
| [8] | 杨加秀, 李新凯, 张宏立, 王昊. 基于积分强化学习的四旋翼无人机鲁棒跟踪[J]. 兵工学报, 2023, 44(9): 2802-2813. |
| [9] | 张建东, 王鼎涵, 杨啟明, 史国庆, 陆屹, 张耀中. 基于分层强化学习的无人机空战多维决策[J]. 兵工学报, 2023, 44(6): 1547-1563. |
| [10] | 李超, 王瑞星, 黄建忠, 江飞龙, 魏雪梅, 孙延鑫. 稀疏奖励下基于强化学习的无人集群自主决策与智能协同[J]. 兵工学报, 2023, 44(6): 1537-1546. |
| [11] | 郑泽新, 李伟, 邹鲲, 李艳福. 基于强化学习的对空雷达抗干扰波形设计[J]. 兵工学报, 2023, 44(5): 1422-1430. |
| [12] | 赵文飞, 陈健, 王, 滕克难. 基于强化学习的海上要地群协同防空动态火力分配[J]. 兵工学报, 2023, 44(11): 3516-3528. |
| [13] | 蒋岩, 丁语嫣, 张兴龙, 徐昕. 基于模型预测与策略学习的智能车辆人机协同控制算法[J]. 兵工学报, 2023, 44(11): 3465-3477. |
| [14] | 李佳键, 史彦军, 杨雨, 李波, 赵熙俊. 无人集群作战任务的多智能体强化学习卸载决策[J]. 兵工学报, 2023, 44(11): 3295-3309. |
| [15] | 卫宁, 王冠. 强化学习在智能无人系统决策管理中的应用[J]. 兵工学报, 2022, 43(S2): 164-169. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
 京公网安备11010802024360号 京ICP备05059581号-4
京公网安备11010802024360号 京ICP备05059581号-4