
Responsible Institution: China Association for Science and Technology
Sponsor: China Ordnance Society
ISSN 1000-1093 CN 11-2176/TJ
Sponsor: China Ordnance Society
ISSN 1000-1093 CN 11-2176/TJ
Acta Armamentarii ›› 2025, Vol. 46 ›› Issue (8): 240978-.doi: 10.12382/bgxb.2024.0978
Previous Articles Next Articles
WANG Yu1,*( ), LI Yuanpeng1, GUO Zhongyu1, LI Shuo1, REN Tianjun2
), LI Yuanpeng1, GUO Zhongyu1, LI Shuo1, REN Tianjun2
Received:2024-10-21
Online:2025-08-28
Contact:
WANG Yu
CLC Number:
WANG Yu, LI Yuanpeng, GUO Zhongyu, LI Shuo, REN Tianjun. Hierarchical Decision-making for UAV Air Combat Based on DDQN-D3PG[J]. Acta Armamentarii, 2025, 46(8): 240978-.
Add to citation manager EndNote|Ris|BibTeX

Fig.1 Schematic diagram of UAV engaging targets
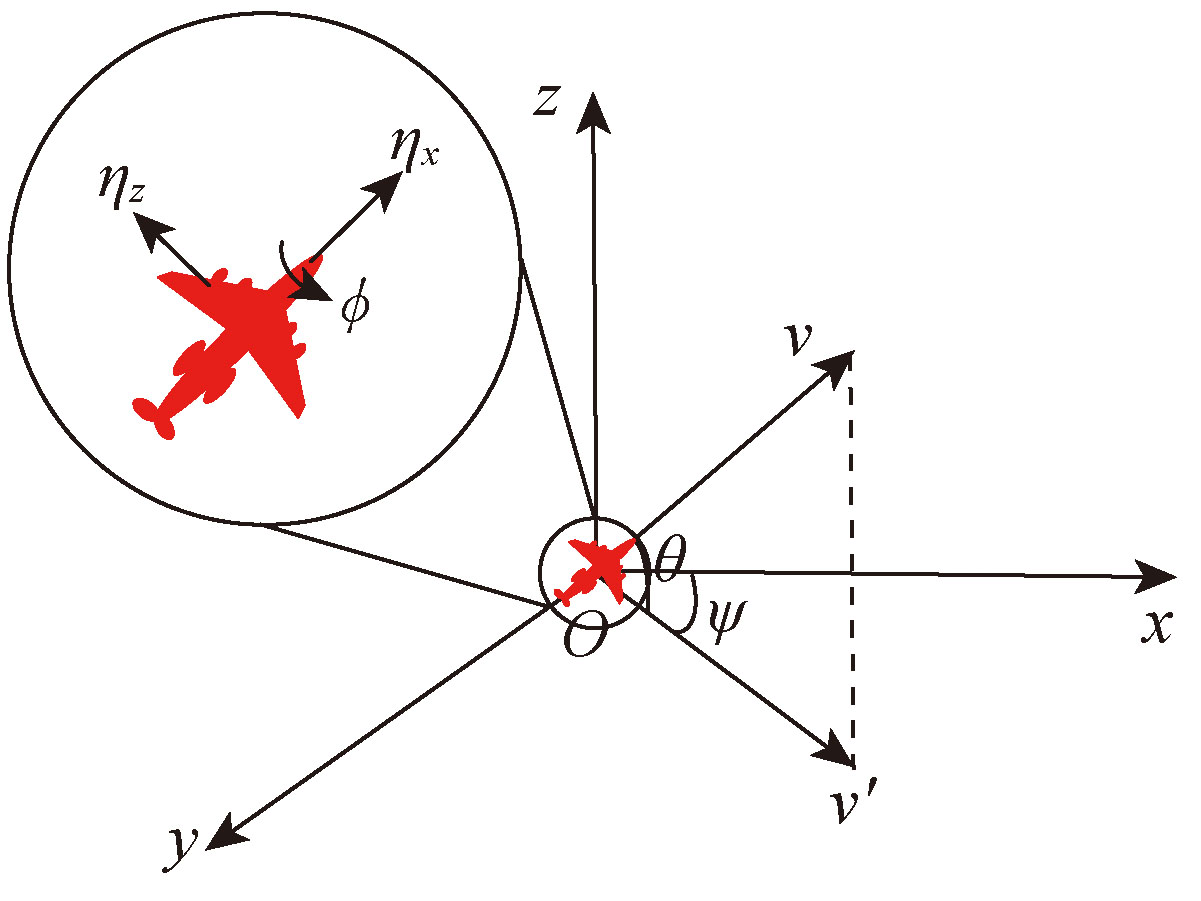
Fig.2 Motion model of UAV
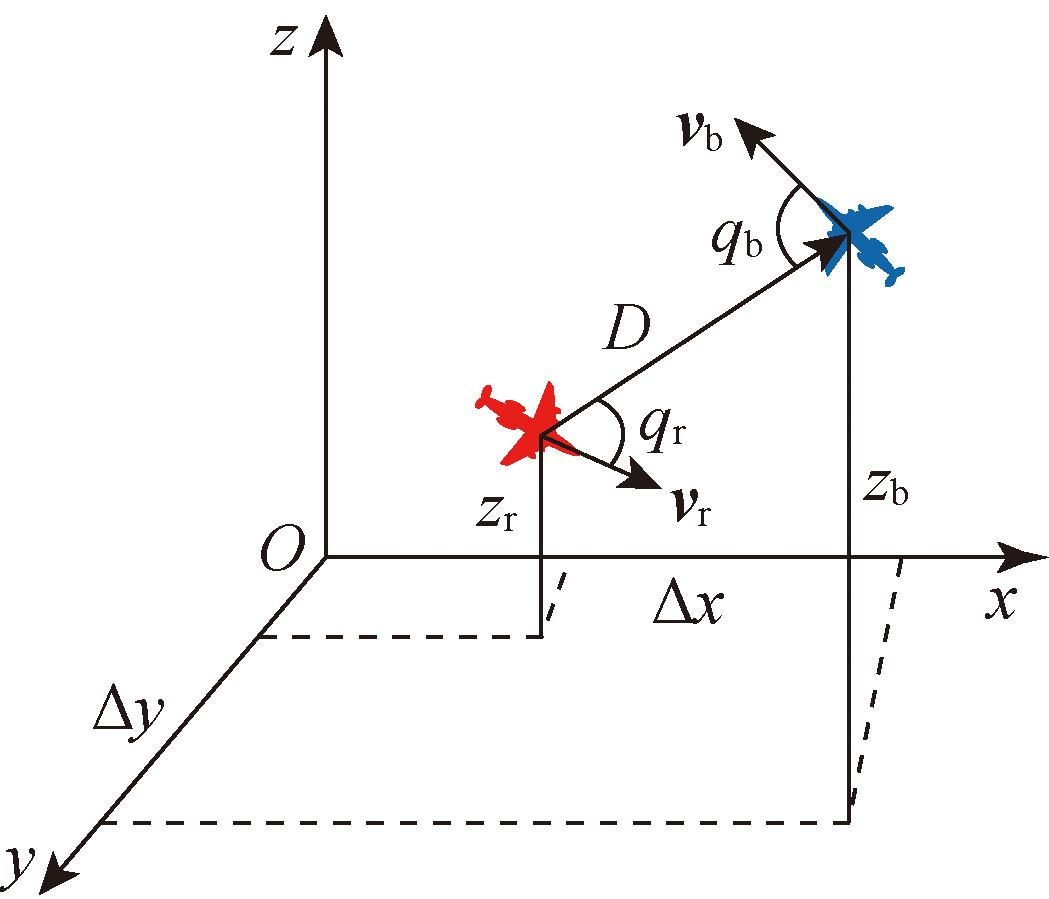
Fig.3 Air combat model of UAV
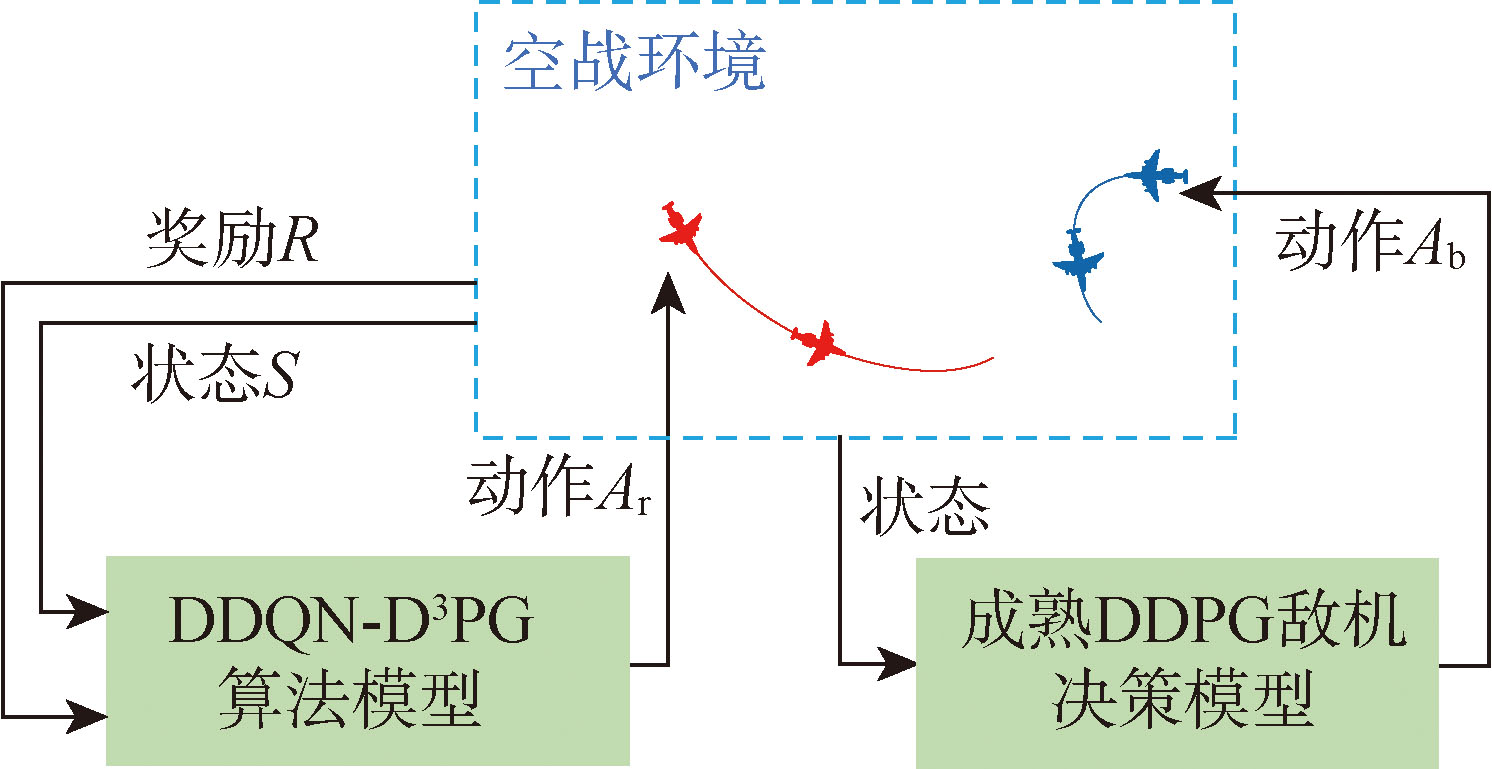
Fig.4 Air aombat decision-making system
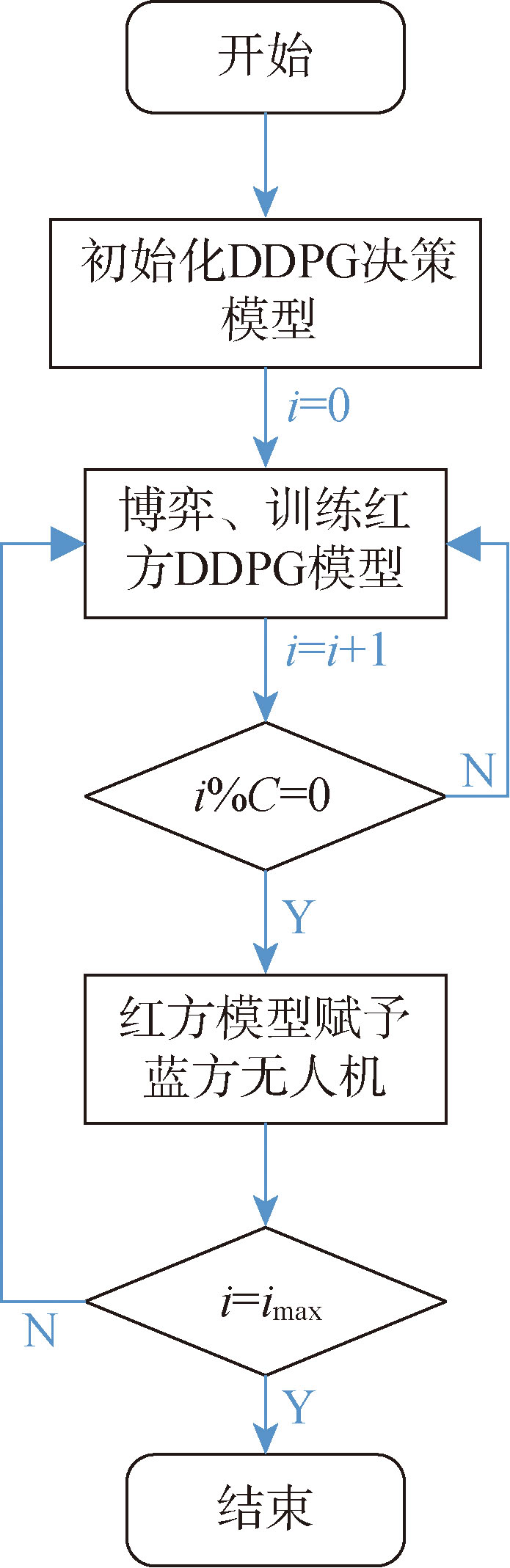
Fig.5 Training process of enemy UAV model
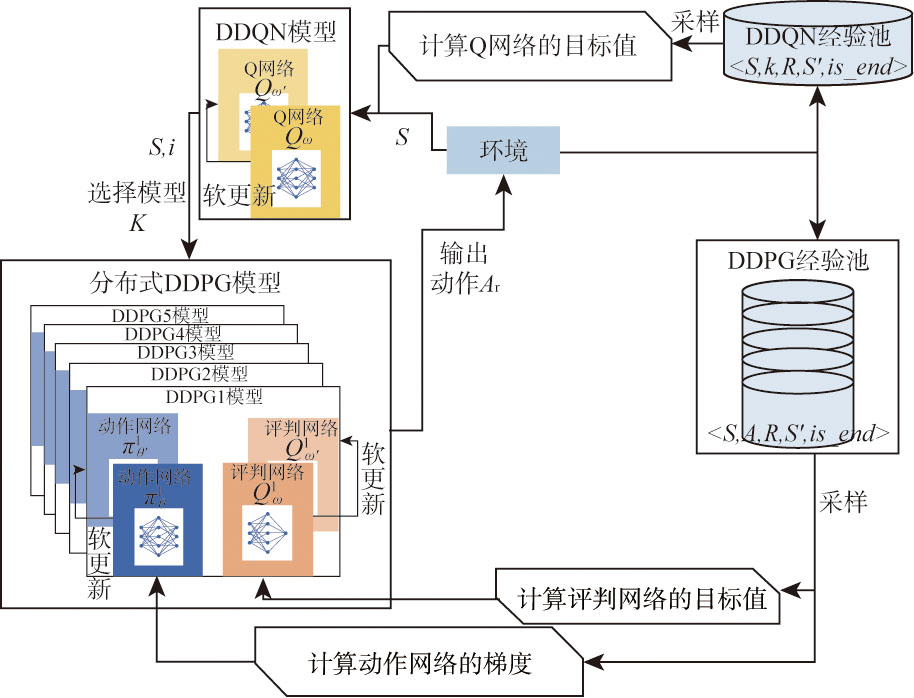
Fig.6 DDQN-D3PG model
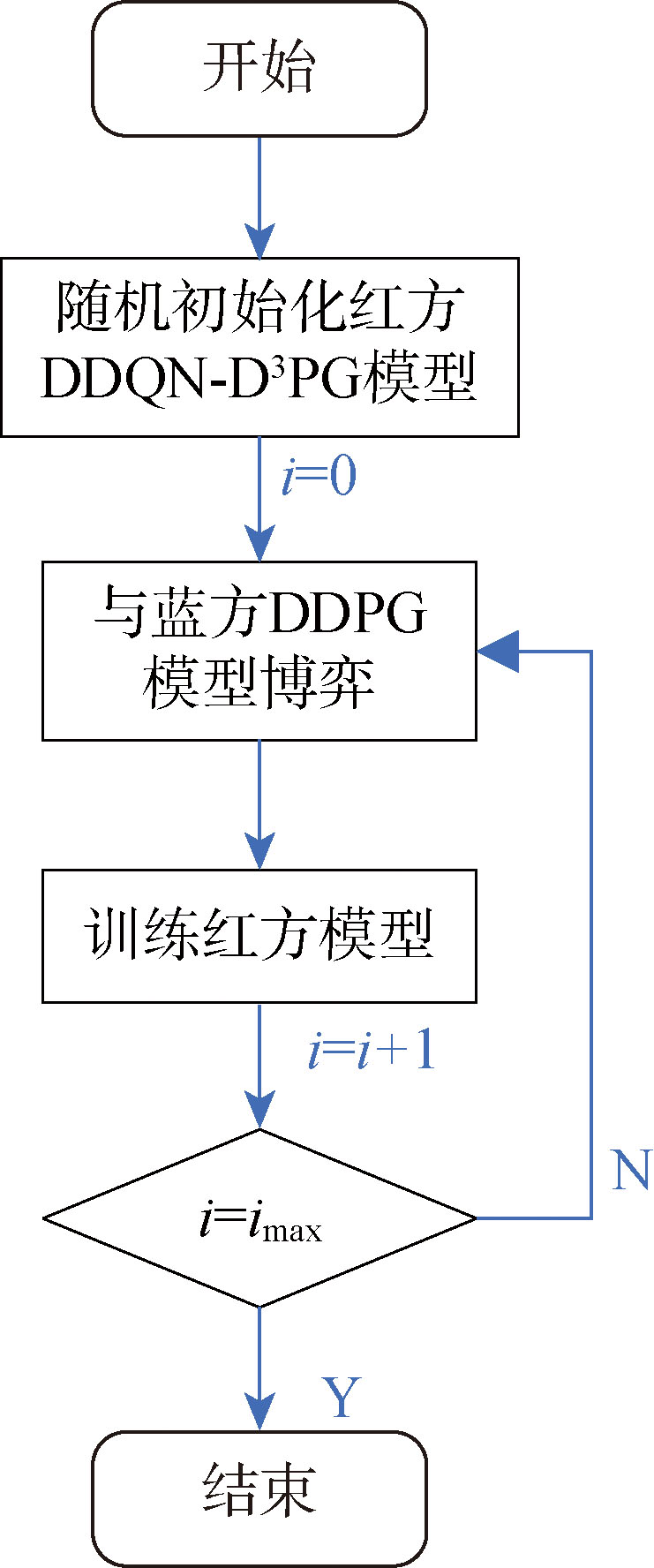
Fig.7 Training process of DDQN-D3PG model
| 参数 | 数值 | 参数 | 数值 |
|---|---|---|---|
| /m | 4000 | qmax/rad | π/6 |
| zmin/m | 2000 | zmax/m | 12000 |
| vmin/(m·s-1) | 50 | vmax/(m·s-1) | 400 |
Table 1 Parameters of adversarial environment
| 参数 | 数值 | 参数 | 数值 |
|---|---|---|---|
| /m | 4000 | qmax/rad | π/6 |
| zmin/m | 2000 | zmax/m | 12000 |
| vmin/(m·s-1) | 50 | vmax/(m·s-1) | 400 |
| 参数 | 数值 | 参数 | 数值 |
|---|---|---|---|
| N | 300 | M | 100 |
| Fb | 30 | Ft | 100 |
| T | 200 |
Table 2 Parameters of model training process
| 参数 | 数值 | 参数 | 数值 |
|---|---|---|---|
| N | 300 | M | 100 |
| Fb | 30 | Ft | 100 |
| T | 200 |
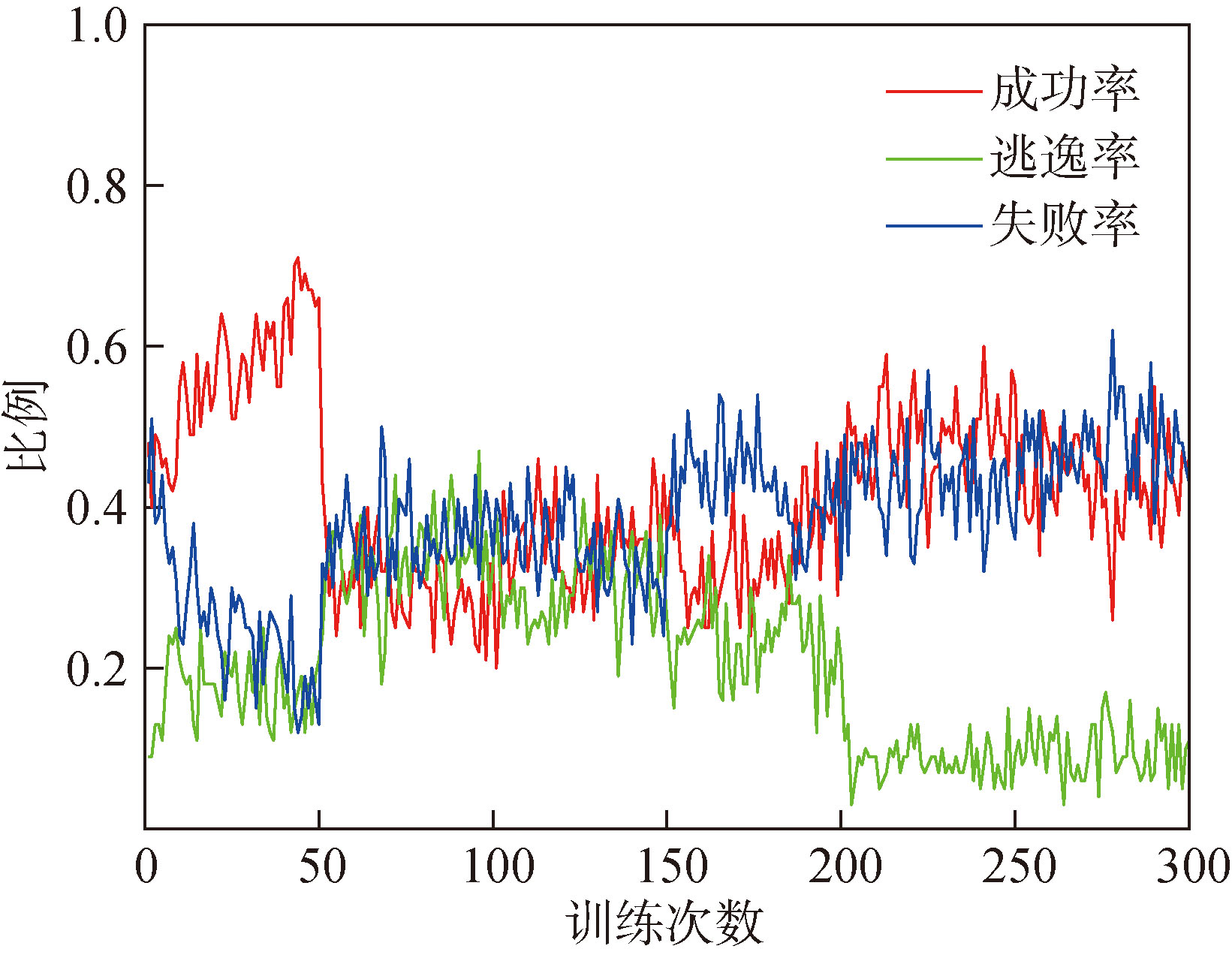
Fig.8 Training process of blue UAV model
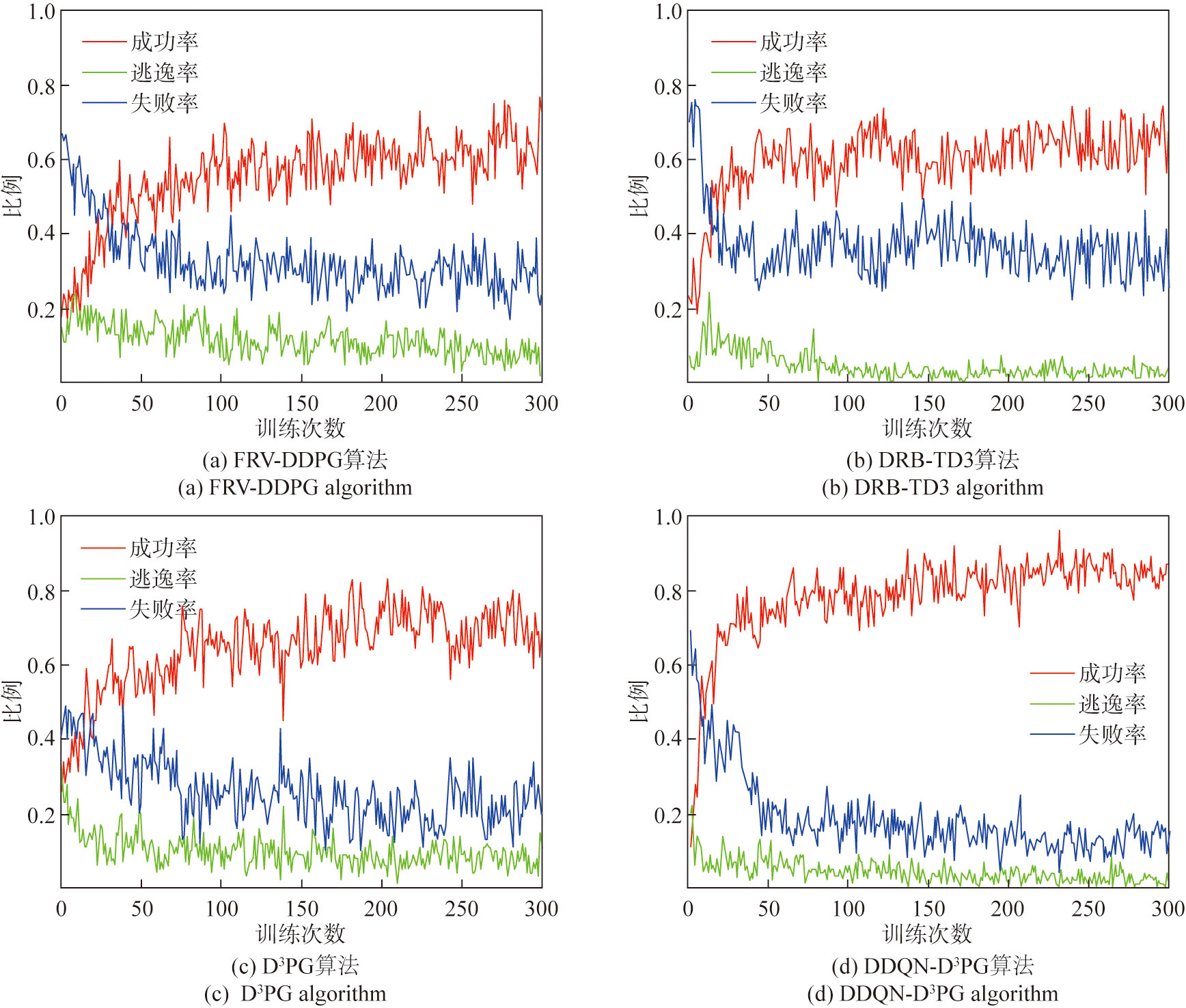
Fig.9 Comparison of training results for four algorithms
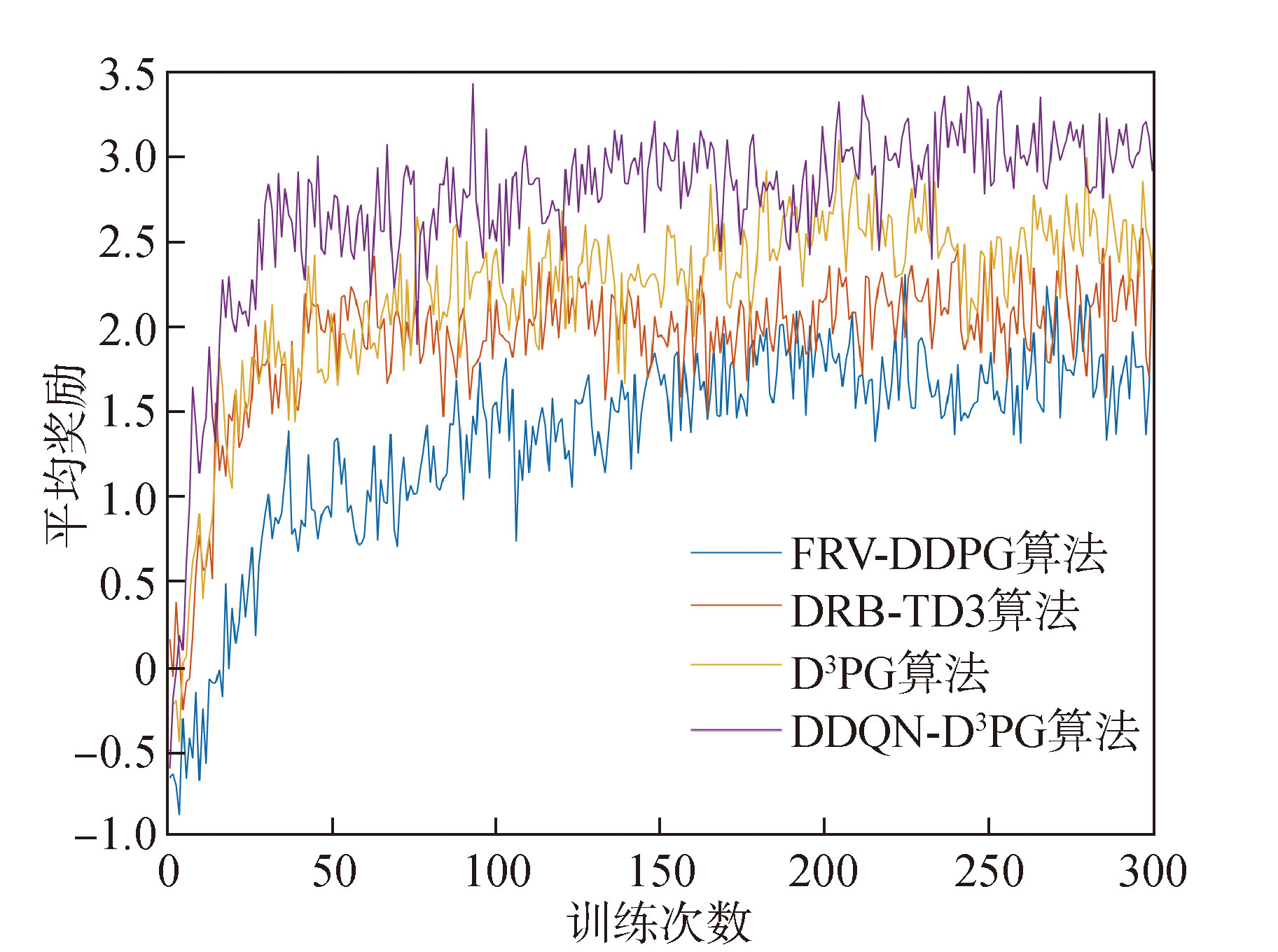
Fig.10 Average reward

Fig.11 Average combat time

Fig.12 The game process under the advantaged situation
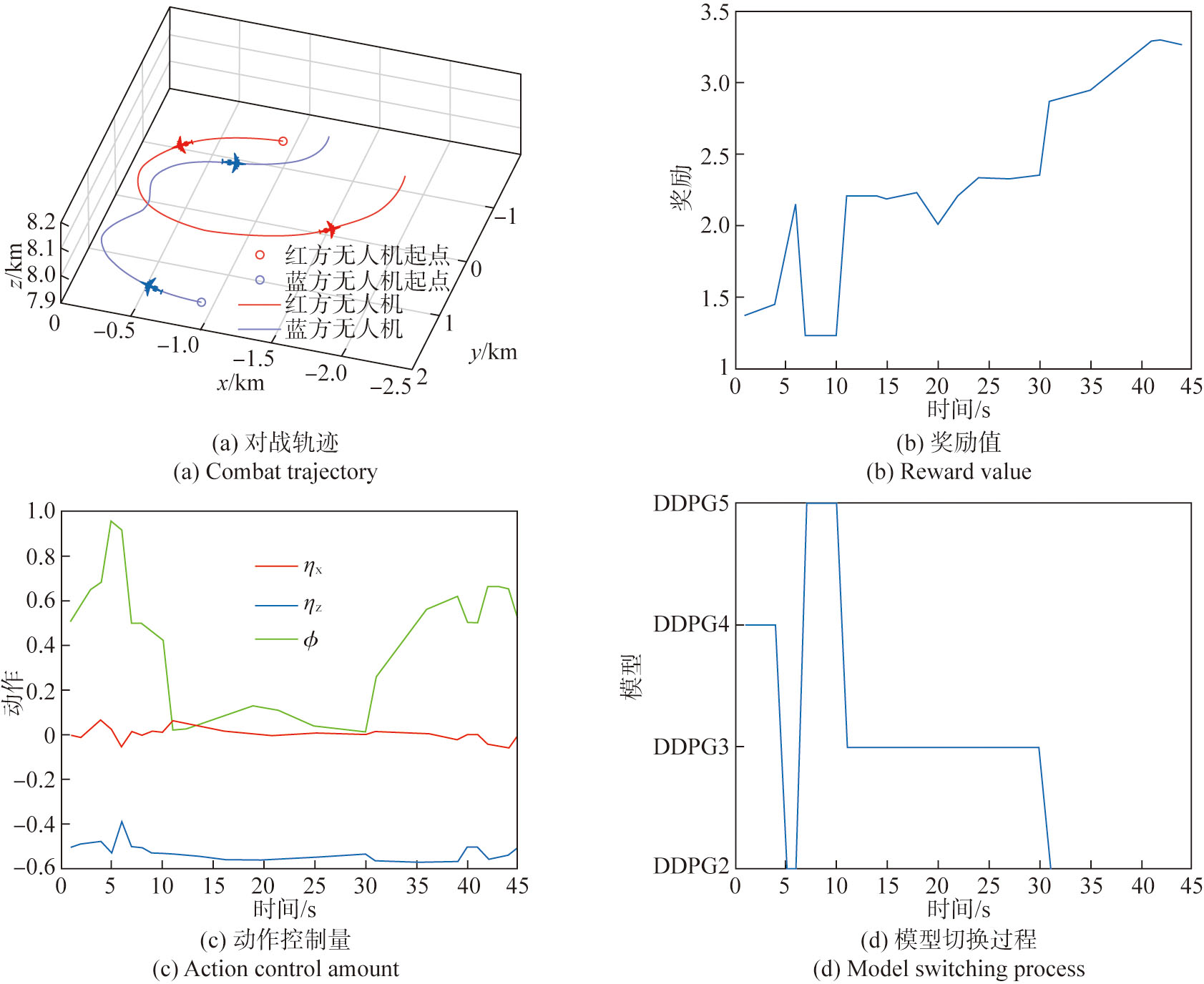
Fig.13 Game process under the equilibrium situation

Fig.14 Game process under the disadvantageous situation
| [1] |
於志文, 孙卓, 程岳, 等. 智能无人机集群协同感知计算研究综述[J]. 航空学报, 2024, 45(20):630912.
|
|
|
|
| [2] |
周新民, 吴佳晖, 贾圣德, 等. 无人机空战决策技术研究进展[J]. 国防科技, 2021, 42(3):33-41.
|
|
|
|
| [3] |
董一群, 艾剑良. 自主空战技术中的机动决策:进展与展望[J]. 航空学报, 2020, 41(增刊2):724264.
|
|
|
|
| [4] |
|
| [5] |
|
| [6] |
车竞, 钱炜祺, 和争春. 基于矩阵博弈的两机攻防对抗空战仿真[J]. 飞行力学, 2015, 33(2):173-177.
|
|
|
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
吴傲, 杨任农, 梁晓龙, 等. 基于模糊推理的无人战斗机视距空战机动决策[J]. 南京航空航天大学学报, 2021, 53(6):898-908.
|
|
|
|
| [11] |
|
| [12] |
何子琦, 李博宸, 王成罡, 等. 针对区域防御的多无人机序列捕捉策略[J]. 兵工学报, 2025, 46(4):240343.
doi: 10.12382/bgxb.2024.0343 |
|
|
|
| [13] |
张耀中, 吴卓然, 张建东, 等. 基于ME-DDPG算法的无人机多对一追逃博弈[J/OL]. 系统工程与电子技术, 2024(2024-10-10)[2024-12-24]. http://kns.cnki.net/kcms/detail/11.2422.tn.20241009.1739.012.html.
|
|
|
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
钟皓俊, 王振雷. 基于双经验回放池TD3算法的PID参数优化[J/OL]. 控制理论与应用, 2024(2024-10-25)[2024-12-24].
|
|
|
|
| [18] |
周攀, 黄江涛, 章胜, 等. 基于深度强化学习的智能空战决策与仿真[J]. 航空学报, 2023, 44(4):126731.
doi: 10.7527/S1000-6893.2022.26731 |
|
doi: 10.7527/S1000-6893.2022.26731 |
|
| [19] |
李永丰, 吕永玺, 史静平, 等. 深度确定性策略梯度和预测相结合的无人机空战决策研究[J]. 西北工业大学学报, 2023, 41(1):56-64.
|
|
|
|
| [20] |
李曾琳, 李波, 白双霞, 等. 基于AM-SAC的无人机自主-空战决策[J]. 兵工学报, 2023, 44(9):2849-2858.
doi: 10.12382/bgxb.2022.0669 |
|
doi: 10.12382/bgxb.2022.0669 |
|
| [21] |
王昱, 任田君, 范子琳, 等. 基于角度特征的分布式DDPG无人机追击决策[J]. 控制理论与应用, 2025, 42(7):1356-1366.
|
|
|
|
| [22] |
王昱, 任田君, 范子琳. 基于引导Minimax-DDQN的无人机空战机动决策[J]. 计算机应用, 2023, 43(8):2636-2643.
doi: 10.11772/j.issn.1001-9081.2022071069 |
|
doi: 10.11772/j.issn.1001-9081.2022071069 |
| [1] | WANG Cuncan, WANG Xiaofang, LIN Hai. A Cooperative Guidance Law Based on Meta-learning and Reinforcement Learning for Multiple Aerial Vehicles [J]. Acta Armamentarii, 2025, 46(7): 240568-. |
| [2] | LU Xiaoran, ZOU Yuan, ZHANG Xudong, SUN Wei, MENG Yihao, ZHANG Bin. Energy Management Strategy Optimized by Munchausen-PER-DDQN for Hybrid Tracked Vehicle [J]. Acta Armamentarii, 2025, 46(6): 240498-. |
| [3] | ZHOU Zhenlin, LONG Teng, LIU Dawei, SUN Jingliang, ZHONG Jianxin, LI Junzhi. Path Planning Method for Large-scale UAV Swarms Based on Reinforcement Learning Conflict Resolution [J]. Acta Armamentarii, 2025, 46(5): 241146-. |
| [4] | XIAN Sujie, WANG Kang, ZENG Xin, SONG Jie, WU Zhilin. An Impact Angle and Field of View Constraints Guidance Law Based on Deep Reinforcement Learning [J]. Acta Armamentarii, 2025, 46(4): 240435-. |
| [5] | PAN Yunwei, LI Min, ZENG Xiangguang, HUANG Ao, ZHANG Jiaheng, REN Wenzhe, PENG Bei. AUV Obstacle Avoidance and Path Planning Based on Artificial Potential Field and Improved Reinforcement Learning [J]. Acta Armamentarii, 2025, 46(4): 240300-. |
| [6] | LI Chuanhao, MING Zhenjun, WANG Guoxin, YAN Yan, DING Wei, WAN Silai, DING Tao. Dynamic Decision-making Method of Unmanned Platform Chaff Jamming for Terminal Defense Based on Multi-agent Deep Reinforcement Learning [J]. Acta Armamentarii, 2025, 46(3): 240251-. |
| [7] | ZHANG Wang, SHAO Xuehui, TANG Huilong, WEI Jianlin, WANG Wei. A Reinforcement Learning-based Radar Jamming Decision-making Method with Adaptive Setting of Exploration Rate [J]. Acta Armamentarii, 2025, 46(3): 240357-. |
| [8] | XIAO Liujun, LI Yaxuan, LIU Xinfu. Adaptive Terminal Guidance for Hypersonic Gliding Vehicles Using Reinforcement Learning [J]. Acta Armamentarii, 2025, 46(2): 240222-. |
| [9] | SUN Hao, LI Haiqing, LIANG Yan, MA Chaoxiong, WU Han. Dynamic Penetration Decision of Loitering Munition Group Based on Knowledge-assisted Reinforcement Learning [J]. Acta Armamentarii, 2024, 45(9): 3161-3176. |
| [10] | HU Yanyang, HE Fan, BAI Chengchao. Cooperative Obstacle Avoidance Decision Method for the Terminal Guidance Phase of Hypersonic Vehicles [J]. Acta Armamentarii, 2024, 45(9): 3147-3160. |
| [11] | CHEN Wenjie, CUI Xiaohong, WANG Binrui. Safety Optimal Tracking Control Algorithm and Robot Arm Simulation [J]. Acta Armamentarii, 2024, 45(8): 2688-2697. |
| [12] | WANG Xiaolong, CHEN Yang, HU Mian, LI Xudong. Robot Path Planning for Persistent Monitoring Based on Improved Deep Q Networks [J]. Acta Armamentarii, 2024, 45(6): 1813-1823. |
| [13] | DONG Mingze, WEN Zhuanglei, CHEN Xiai, YANG Jiongkun, ZENG Tao. Research on Robot Navigation Method Integrating Safe Convex Space and Deep Reinforcement Learning [J]. Acta Armamentarii, 2024, 45(12): 4372-4382. |
| [14] | LOU Shuhan, WANG Chongchong, GONG Wei, DENG Liyuan, LI Li. Collaborative Regional Information Collection Strategy Based on MLAT-DRL Algorithm [J]. Acta Armamentarii, 2024, 45(12): 4423-4434. |
| [15] | LI Jiashen, WANG Xiaofang, LIN Hai. Intelligent Penetration Policy for Hypersonic Cruise Missiles Based on Virtual Targets [J]. Acta Armamentarii, 2024, 45(11): 3856-3867. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||