
Responsible Institution: China Association for Science and Technology
Sponsor: China Ordnance Society
ISSN 1000-1093 CN 11-2176/TJ
Sponsor: China Ordnance Society
ISSN 1000-1093 CN 11-2176/TJ
Acta Armamentarii ›› 2025, Vol. 46 ›› Issue (7): 240568-.doi: 10.12382/bgxb.2024.0568
Previous Articles Next Articles
WANG Cuncan, WANG Xiaofang*( ), LIN Hai
), LIN Hai
Received:2024-07-10
Online:2025-08-12
Contact:
WANG Xiaofang
CLC Number:
WANG Cuncan, WANG Xiaofang, LIN Hai. A Cooperative Guidance Law Based on Meta-learning and Reinforcement Learning for Multiple Aerial Vehicles[J]. Acta Armamentarii, 2025, 46(7): 240568-.
Add to citation manager EndNote|Ris|BibTeX
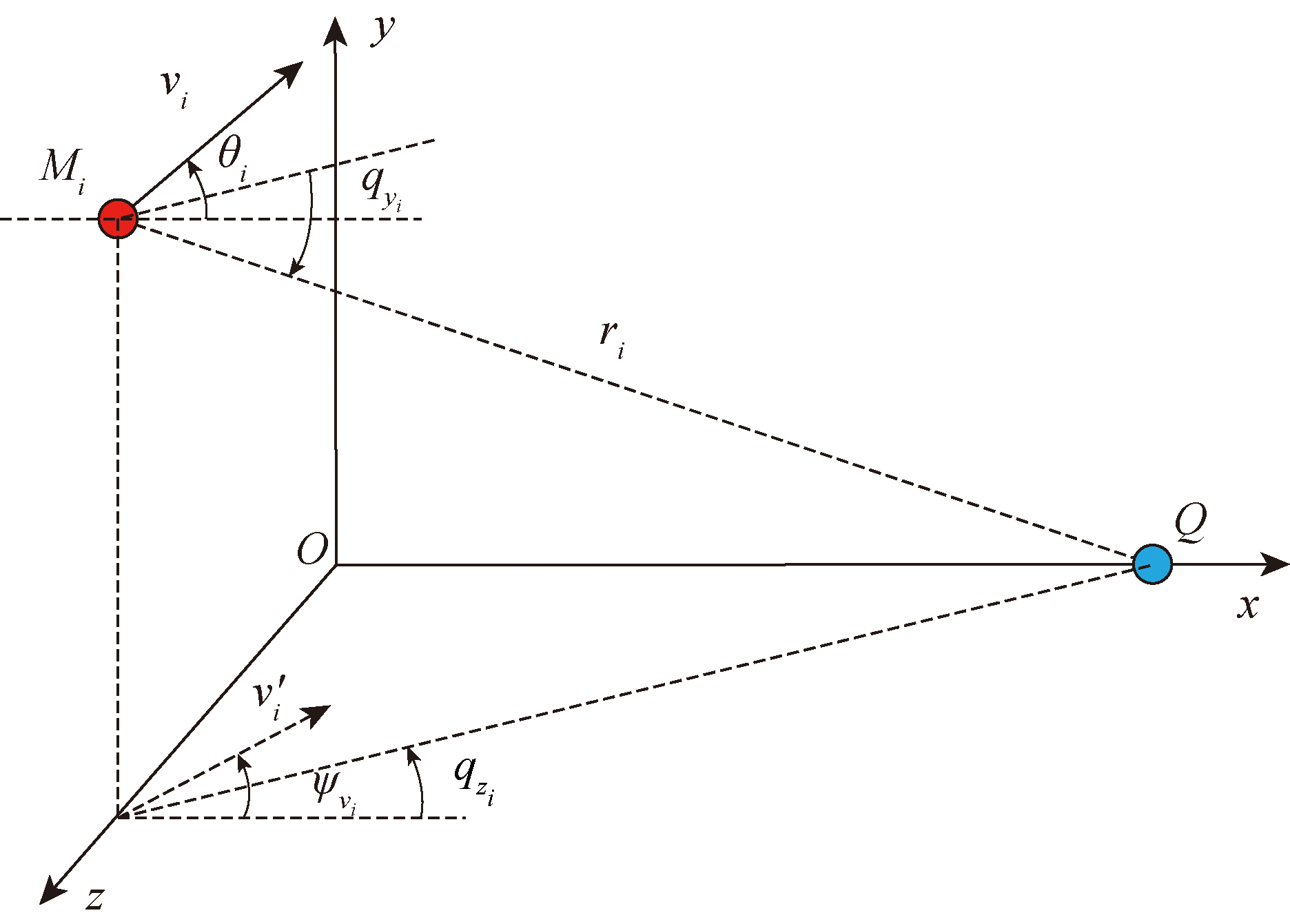
Fig.1 Missile-target relative motion diagram
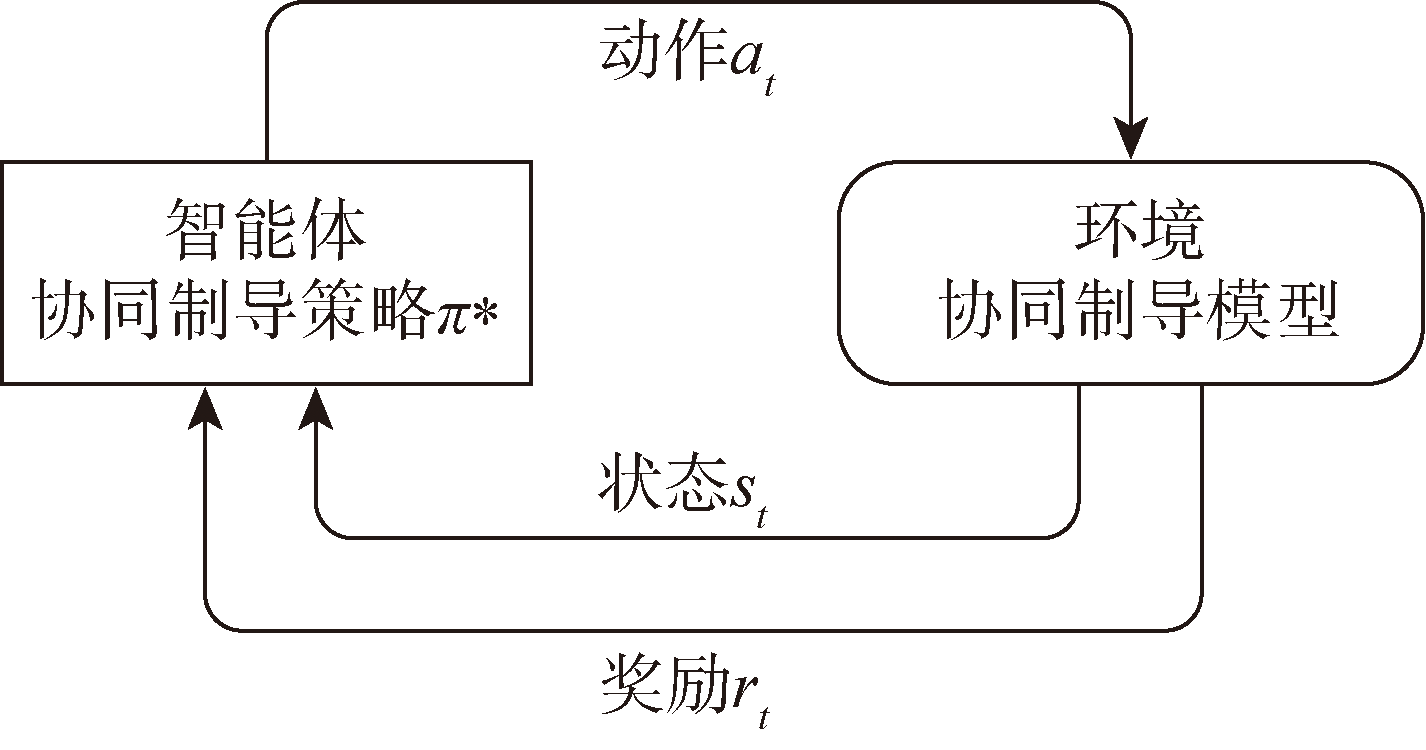
Fig.2 Cooperative guidance interaction process
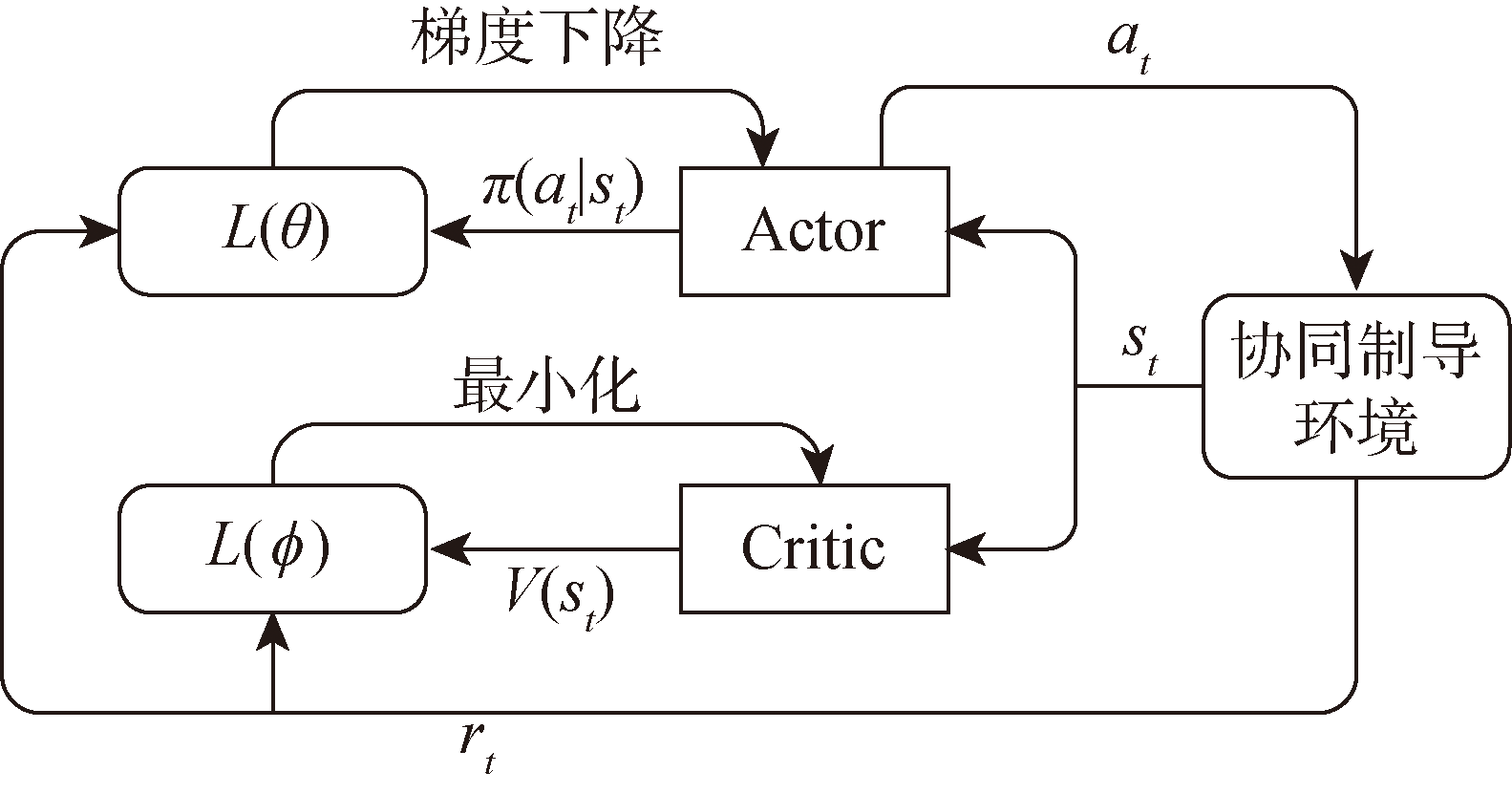
Fig.3 Structural diagram of PPO algorithm network

Fig.4 Basic structure of GRU network
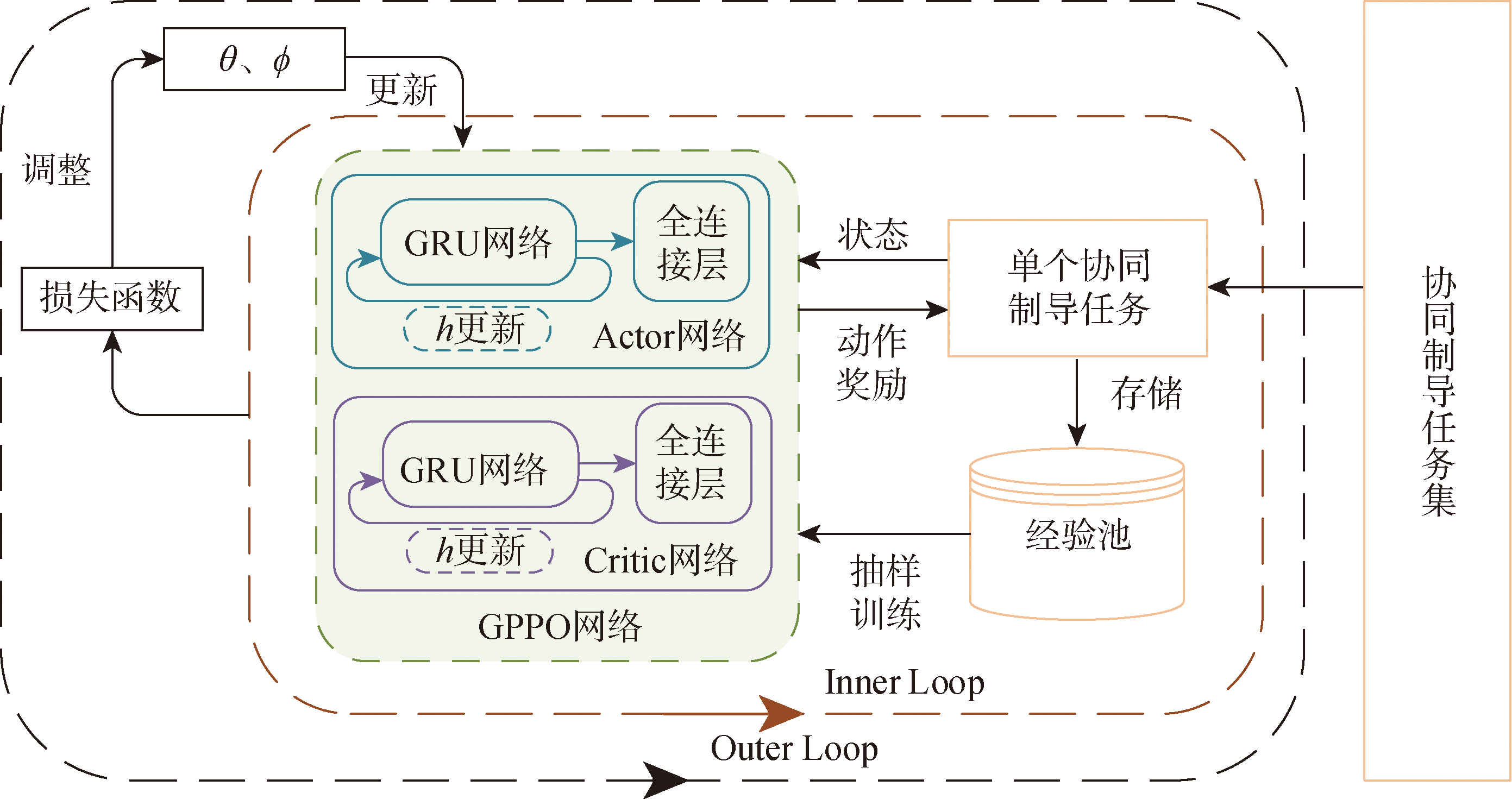
Fig.5 Structural diagram of GPPO algorithm
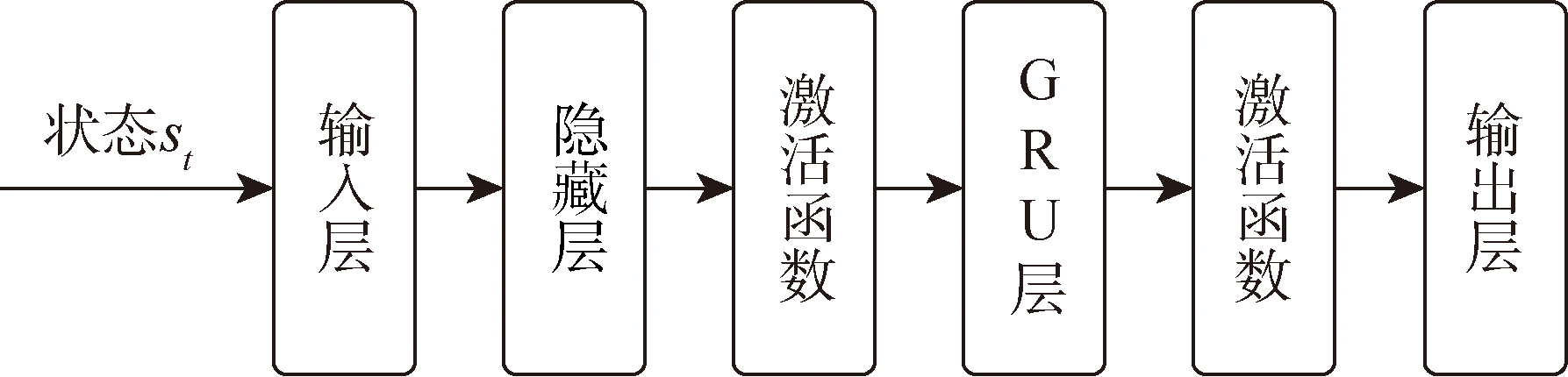
Fig.6 Basic structure of Actor and Critic networks
| 参数 | 初始值 |
|---|---|
| 目标初始位置/m | (45000,0,0) |
| M1初始位置/m | (0,30000,0) |
| M1速度/(m·s-1) | 1200 |
| M1初始弹道倾角/(°) | 0 |
| M1初始弹道偏角/(°) | -5 |
| M2初始位置/m | (0,30000,1000) |
| M2速度/(m·s-1) | 1200 |
| M2初始弹道倾角/(°) | 0 |
| M2初始弹道偏角/(°) | -20 |
| M3初始位置/m | (0,30000,-1000) |
| M3速度/(m·s-1) | 1200 |
| M3初始弹道倾角/(°) | 0 |
| M3初始弹道偏角/(°) | 15 |
Table 1 Initial parameters of 3 missiles and the target
| 参数 | 初始值 |
|---|---|
| 目标初始位置/m | (45000,0,0) |
| M1初始位置/m | (0,30000,0) |
| M1速度/(m·s-1) | 1200 |
| M1初始弹道倾角/(°) | 0 |
| M1初始弹道偏角/(°) | -5 |
| M2初始位置/m | (0,30000,1000) |
| M2速度/(m·s-1) | 1200 |
| M2初始弹道倾角/(°) | 0 |
| M2初始弹道偏角/(°) | -20 |
| M3初始位置/m | (0,30000,-1000) |
| M3速度/(m·s-1) | 1200 |
| M3初始弹道倾角/(°) | 0 |
| M3初始弹道偏角/(°) | 15 |
| 参数 | 数值 | 参数 | 数值 |
|---|---|---|---|
| a | 100 | b4 | -10 |
| b1 | -0.5 | b5 | -50 |
| b2 | 30 | c1 | 0.1 |
| b3 | 10 | c2 | -0.1 |
Table 2 Reward function parameters
| 参数 | 数值 | 参数 | 数值 |
|---|---|---|---|
| a | 100 | b4 | -10 |
| b1 | -0.5 | b5 | -50 |
| b2 | 30 | c1 | 0.1 |
| b3 | 10 | c2 | -0.1 |
| 参数 | Actor网络 | Critic网络 |
|---|---|---|
| 输入层 | 10 | 10 |
| 隐藏层 | 64 | 64 |
| 激活函数 | Tanh | Tanh |
| GRU层 | 64 | 64 |
| 激活函数 | Tanh | Tanh |
| 输出层 | 3 | 1 |
| 激活函数 | Tanh | - |
Table 3 Network structure parameters
| 参数 | Actor网络 | Critic网络 |
|---|---|---|
| 输入层 | 10 | 10 |
| 隐藏层 | 64 | 64 |
| 激活函数 | Tanh | Tanh |
| GRU层 | 64 | 64 |
| 激活函数 | Tanh | Tanh |
| 输出层 | 3 | 1 |
| 激活函数 | Tanh | - |
| 参数 | 数值 |
|---|---|
| 学习率 | 0.0003 |
| 奖励折扣系数γ | 0.99 |
| GAE系数λ | 0.95 |
| 裁剪因子ε | 0.2 |
Table 4 Algorithm training hyperparameters
| 参数 | 数值 |
|---|---|
| 学习率 | 0.0003 |
| 奖励折扣系数γ | 0.99 |
| GAE系数λ | 0.95 |
| 裁剪因子ε | 0.2 |
| 干扰 | 大小 |
|---|---|
| (i=1,2,3)/((°)·s-1) | 0.1N(0,1) |
| (i=1,2,3)/((°)·s-1) | 0.1N(0,1) |
Table 5 Interference experienced by the missile
| 干扰 | 大小 |
|---|---|
| (i=1,2,3)/((°)·s-1) | 0.1N(0,1) |
| (i=1,2,3)/((°)·s-1) | 0.1N(0,1) |
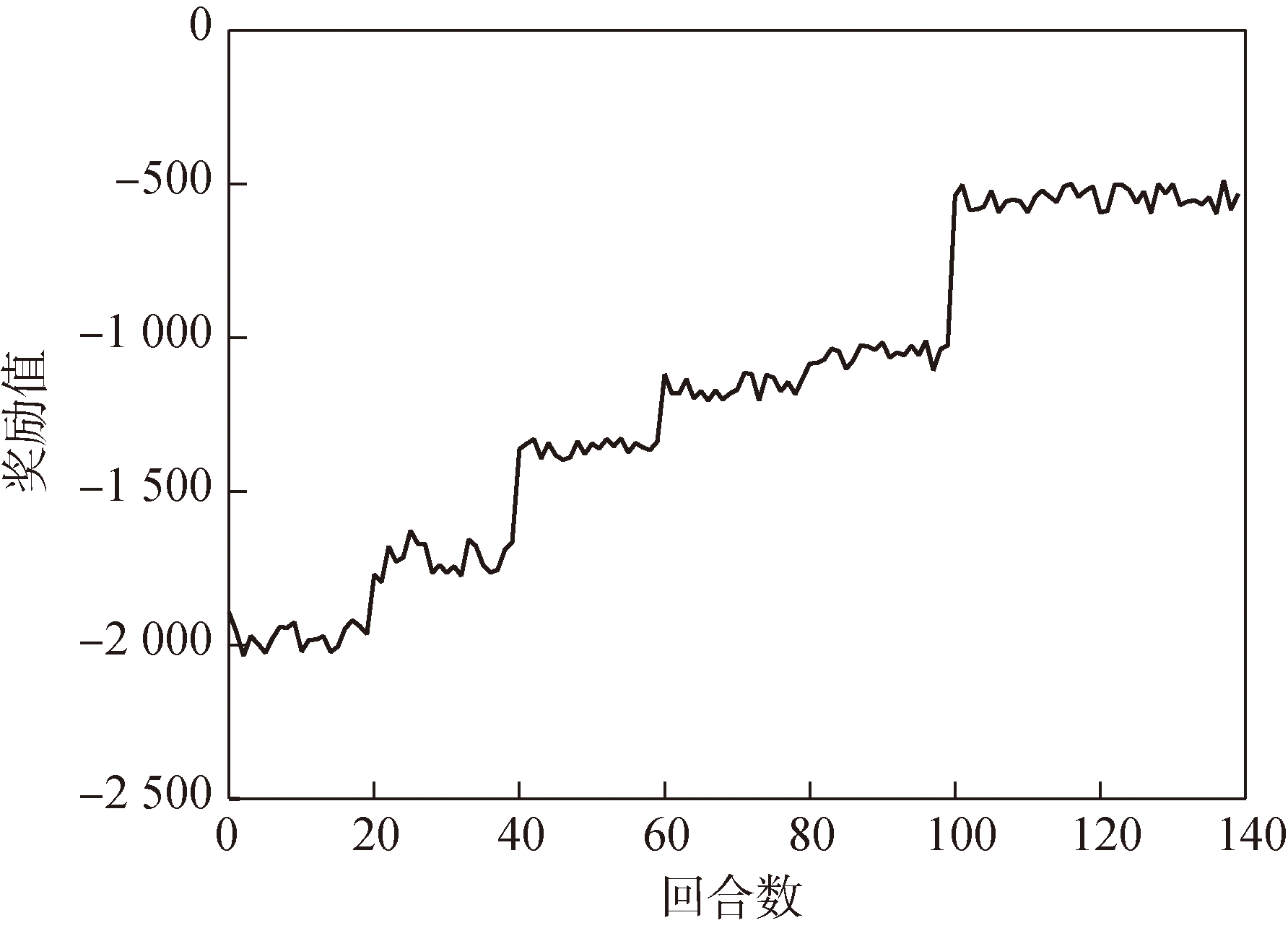
Fig.7 Reward function curve of PPO guidance network

Fig.8 Missile trajectory
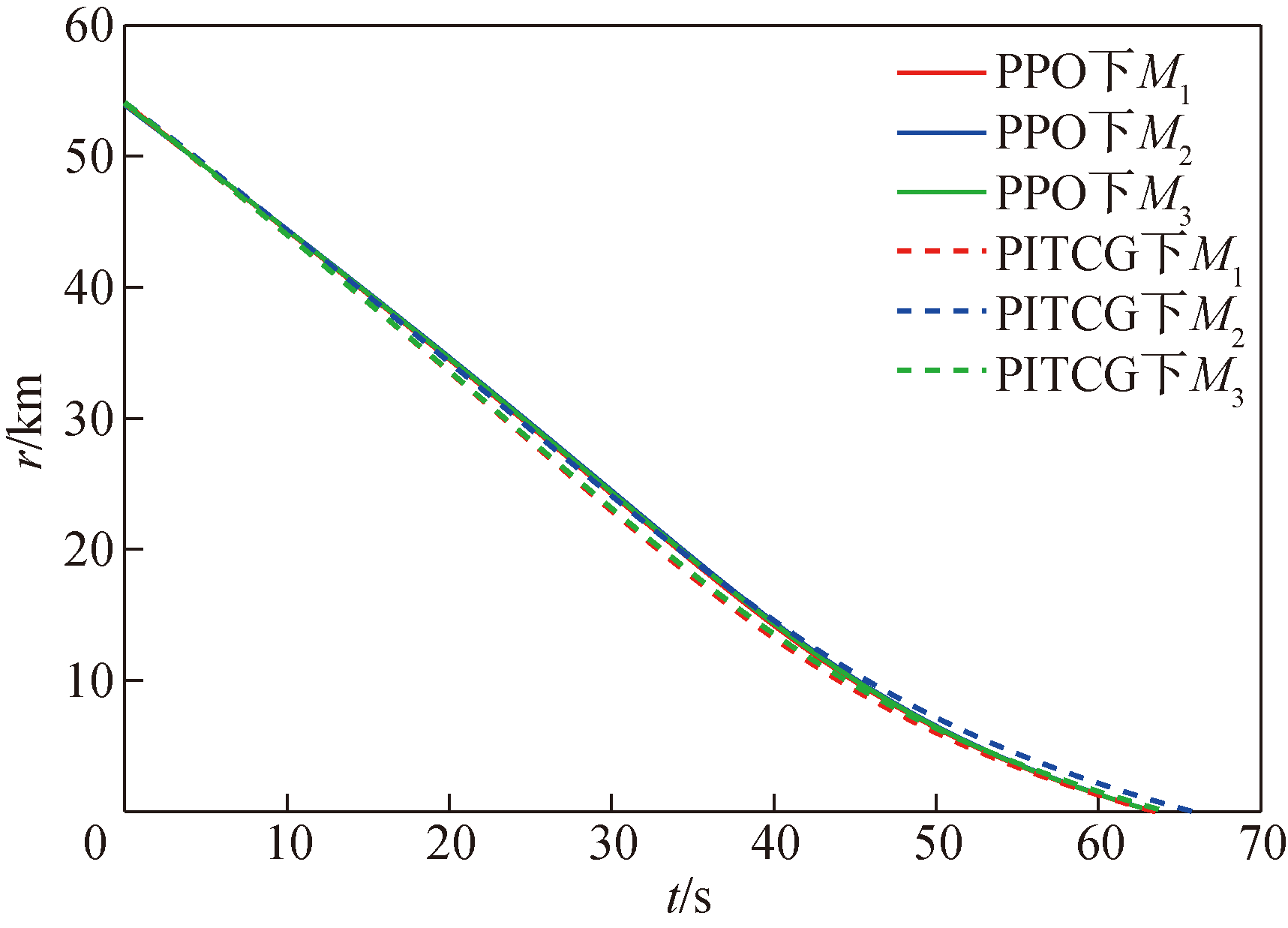
Fig.9 Missile-target relative distance over time
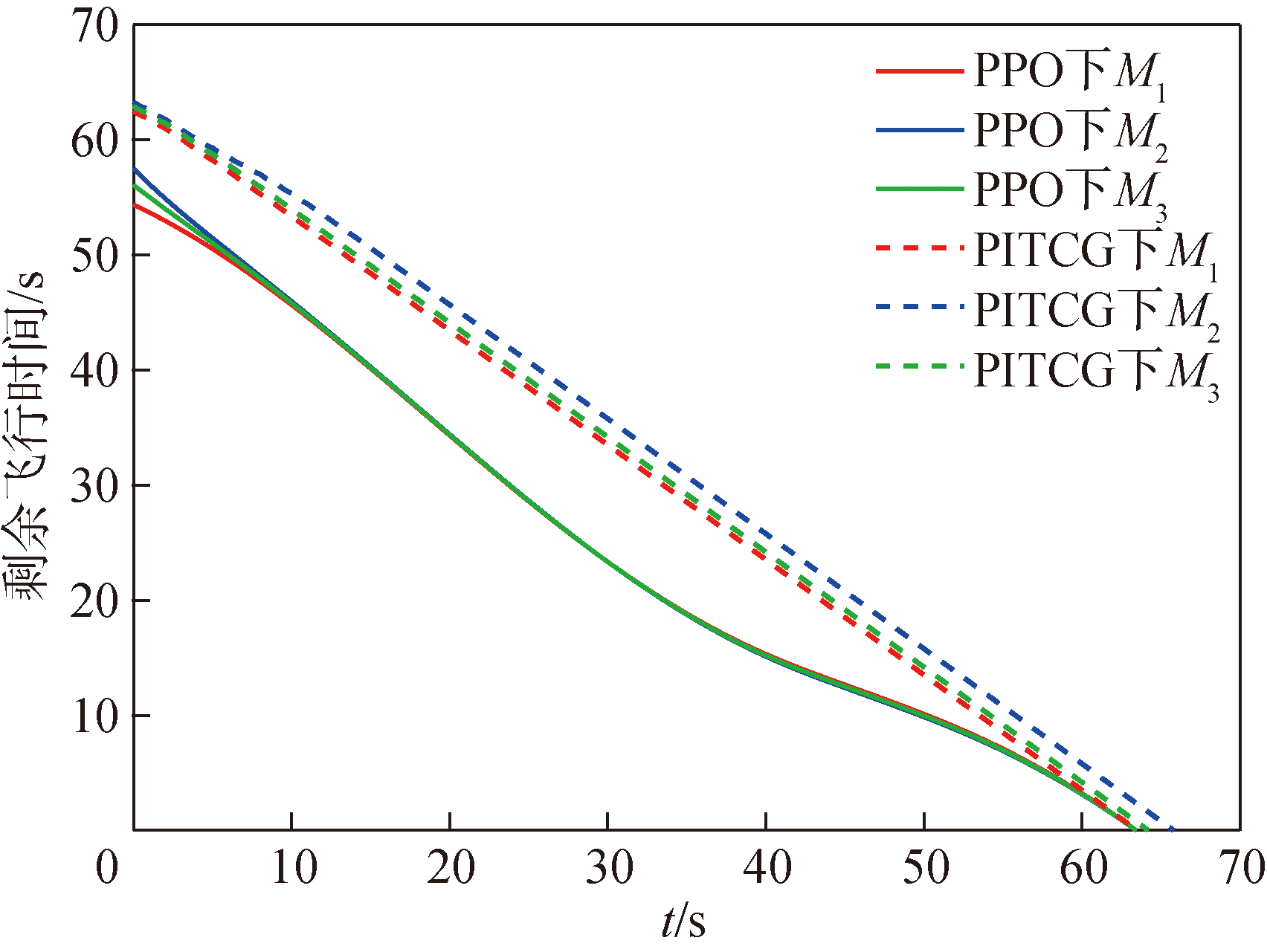
Fig.10 Remaining flight time tgo over time
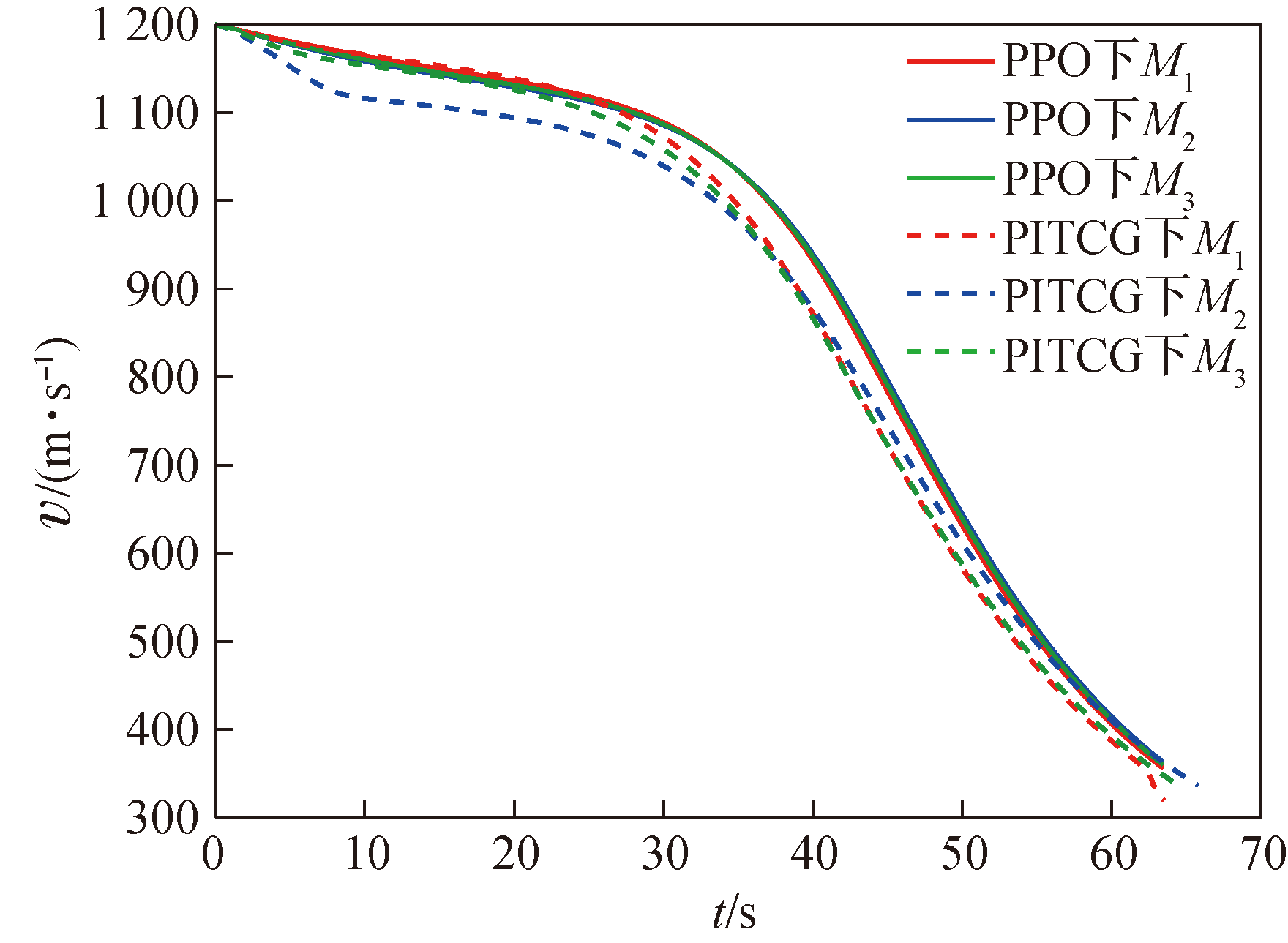
Fig.11 Missile velocity V over time
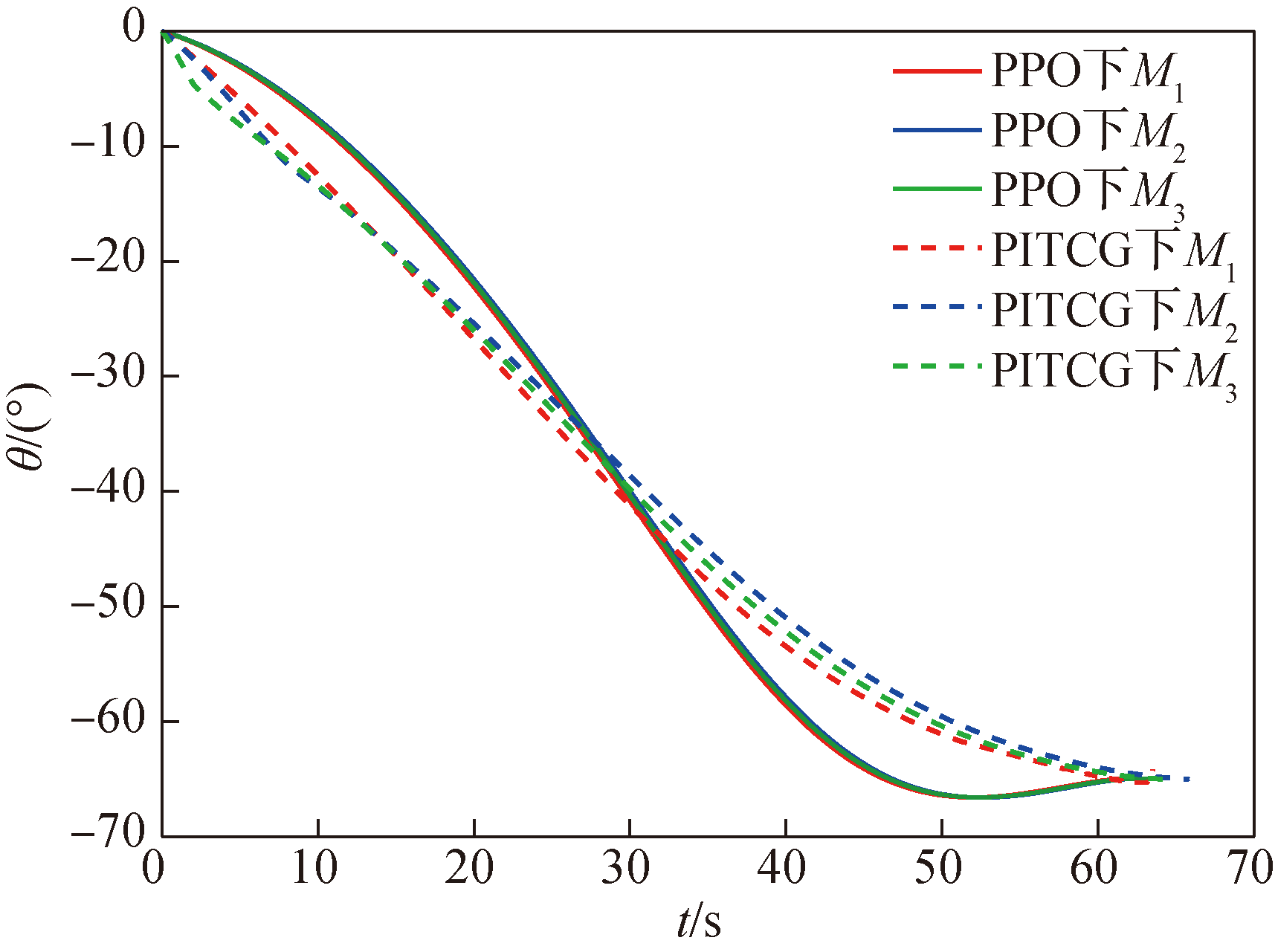
Fig.12 Missile trajectory inclination angle θ over time
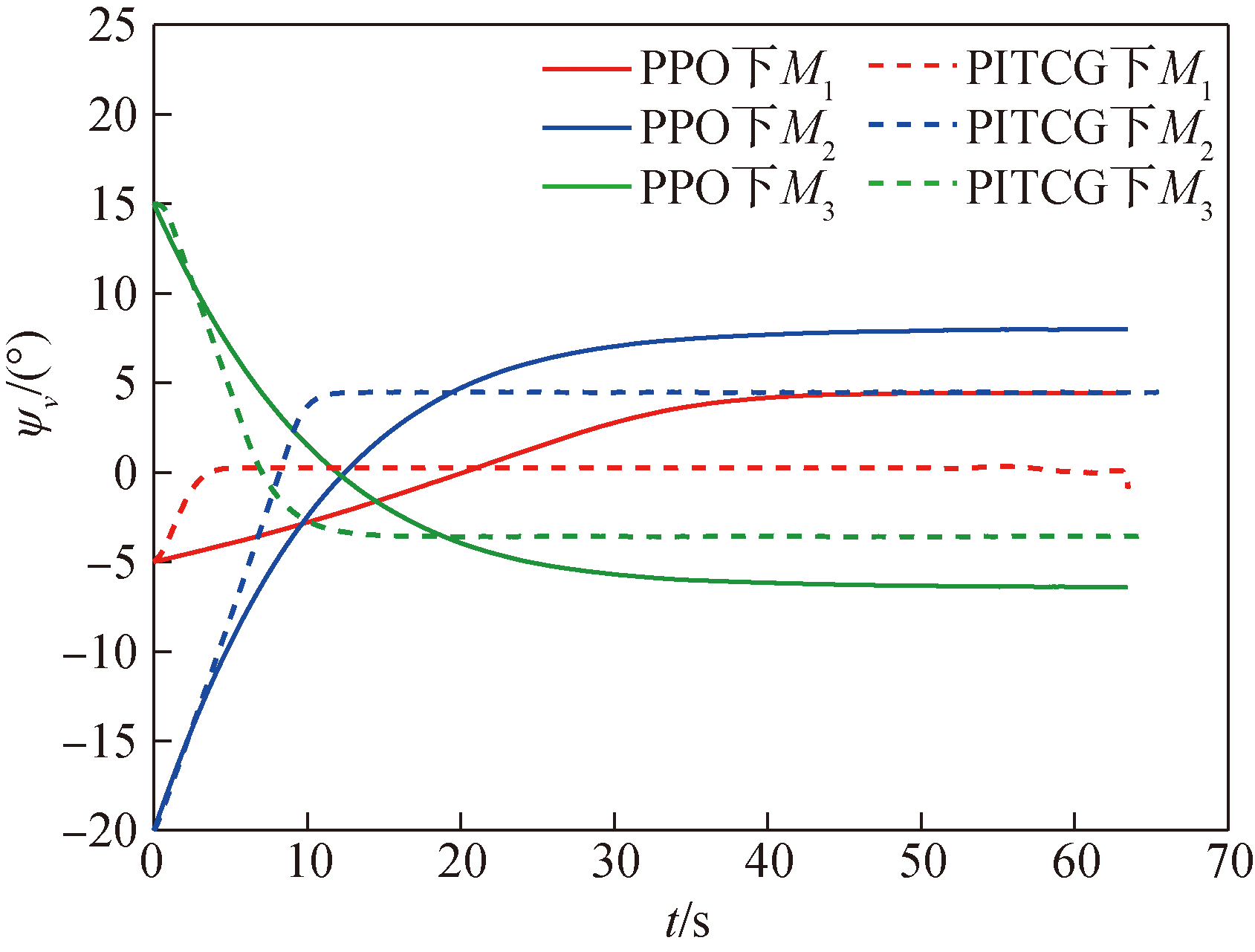
Fig.13 Missile trajectory deviation angle ψV over time
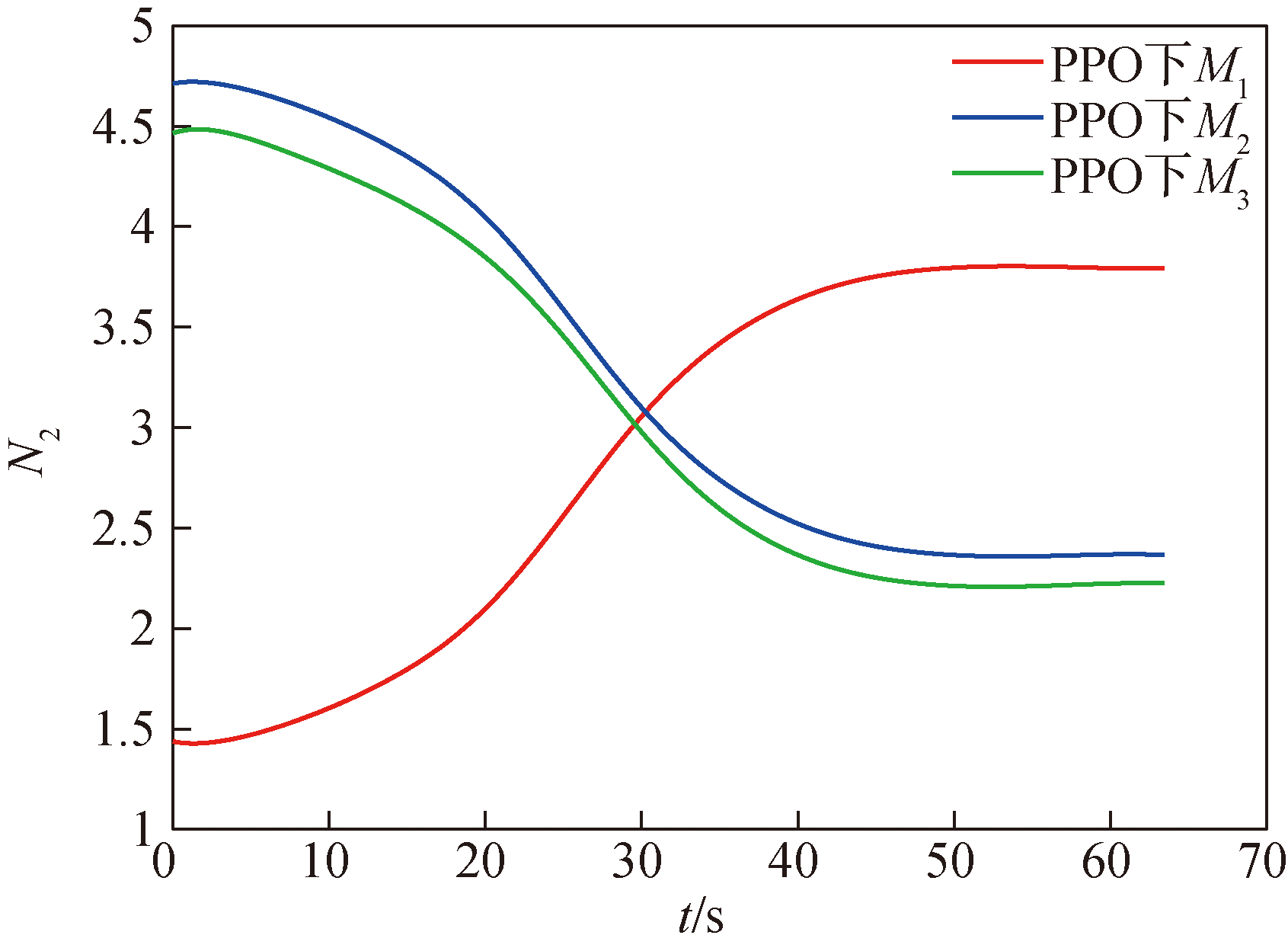
Fig.14 The curve of guidance coefficient variation under PPO
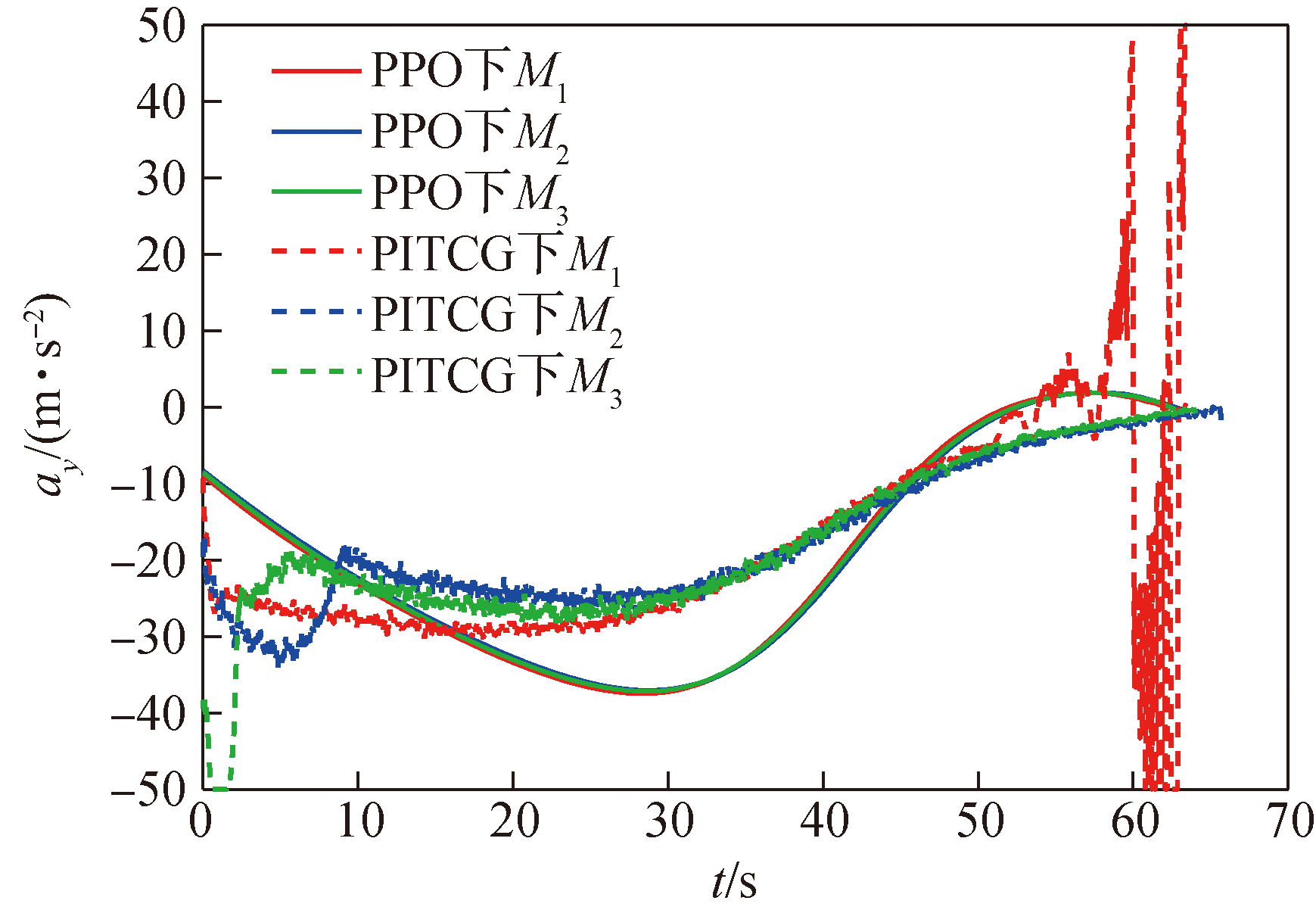
Fig.15 Missile longitudinal acceleration curve
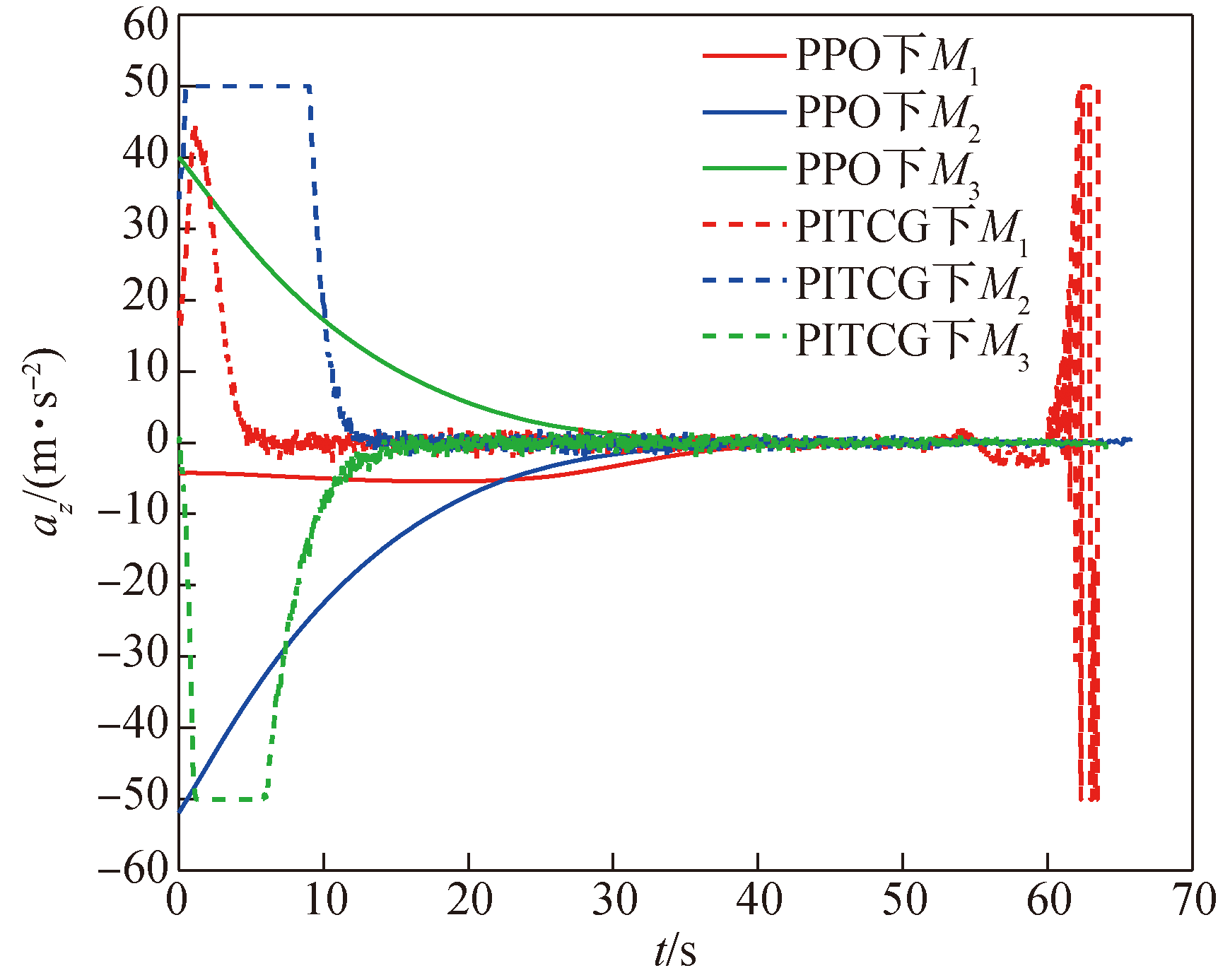
Fig.16 Missile lateral acceleration curve
| 制导律 | 导弹 | 脱靶量/m | 攻击时间/s | 攻击角度/(°) |
|---|---|---|---|---|
| PPO策略 | M1 | 0.74 | 63.45 | -65.00 |
| M2 | 3.42 | 63.46 | -64.98 | |
| M3 | 2.69 | 63.45 | -65.00 | |
| PITCG | M1 | 20.85 | 63.47 | -64.98 |
| M2 | 30.21 | 65.74 | -65.05 | |
| M3 | 23.57 | 64.17 | -65.04 |
Table 6 Missile miss distance,attack time,and angle of attack
| 制导律 | 导弹 | 脱靶量/m | 攻击时间/s | 攻击角度/(°) |
|---|---|---|---|---|
| PPO策略 | M1 | 0.74 | 63.45 | -65.00 |
| M2 | 3.42 | 63.46 | -64.98 | |
| M3 | 2.69 | 63.45 | -65.00 | |
| PITCG | M1 | 20.85 | 63.47 | -64.98 |
| M2 | 30.21 | 65.74 | -65.05 | |
| M3 | 23.57 | 64.17 | -65.04 |
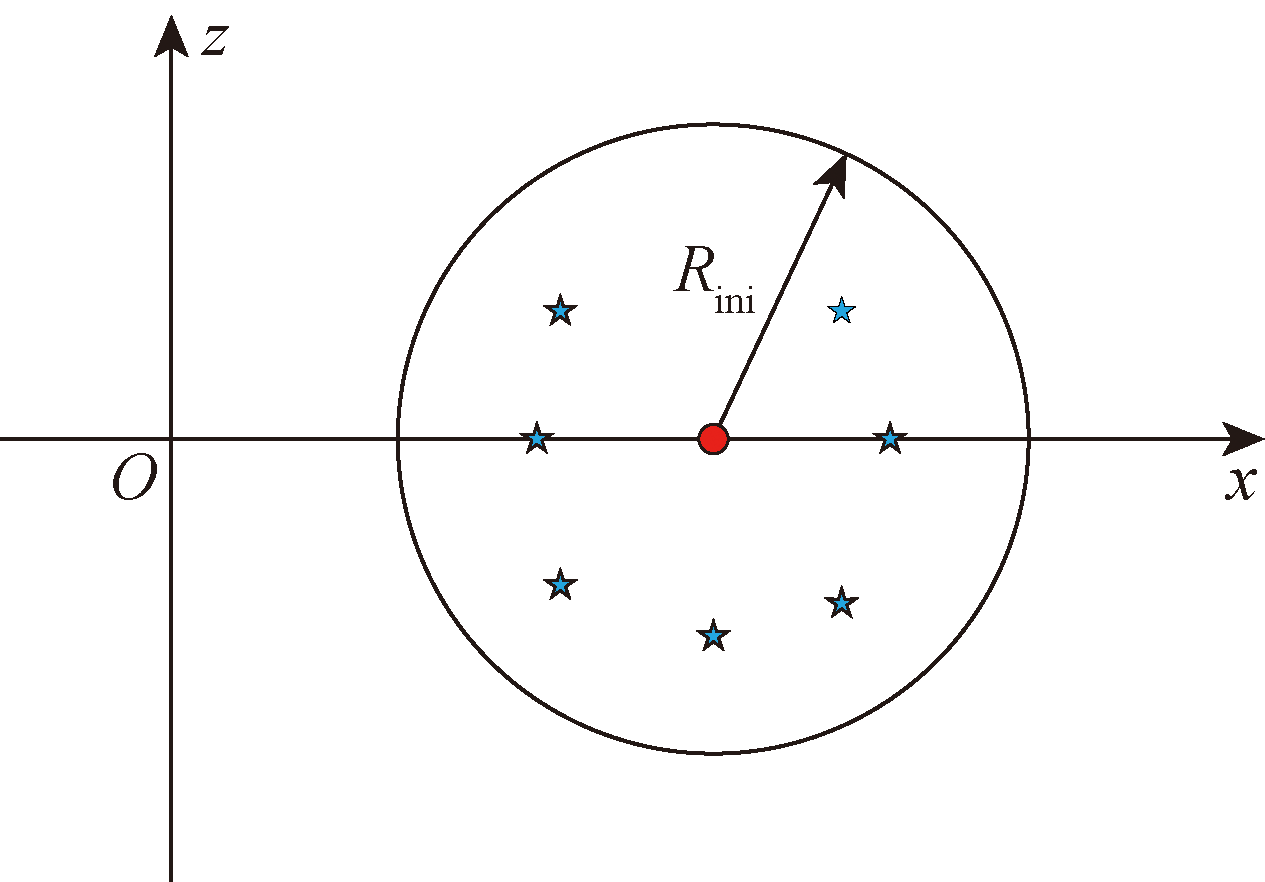
Fig.17 Schematic diagram of target position
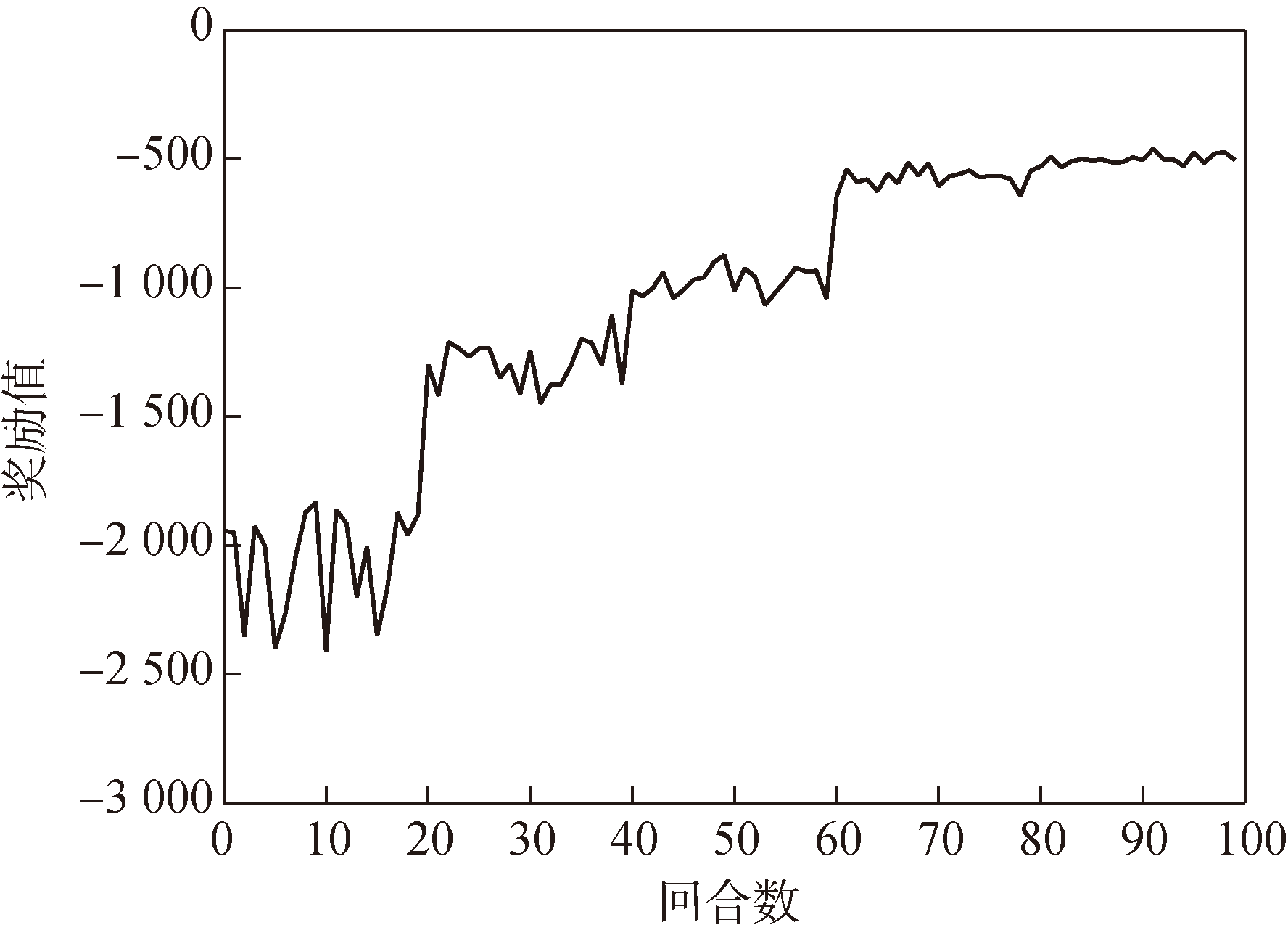
Fig.18 Reward function curve of GPPO guidance network
| 制导律 | 脱靶量/m | 攻击时间误差/s | 攻击角度误差/(°) | |||
|---|---|---|---|---|---|---|
| 平均值 | 标准差 | 平均值 | 标准差 | 平均值 | 标准差 | |
| PPO | 6.79 | 1.88 | 0.42 | 0.76 | 0.07 | 0.17 |
| GPPO | 5.46 | 0.49 | 0.17 | 0.18 | 0.03 | 0.08 |
Table 7 Online performance comparison of guidance laws under case 1
| 制导律 | 脱靶量/m | 攻击时间误差/s | 攻击角度误差/(°) | |||
|---|---|---|---|---|---|---|
| 平均值 | 标准差 | 平均值 | 标准差 | 平均值 | 标准差 | |
| PPO | 6.79 | 1.88 | 0.42 | 0.76 | 0.07 | 0.17 |
| GPPO | 5.46 | 0.49 | 0.17 | 0.18 | 0.03 | 0.08 |
| 制导律 | 脱靶量/m | 攻击时间误差/s | 攻击角度 误差/(°) | 平均训练 回合数 | |||
|---|---|---|---|---|---|---|---|
| 平均值 | 标准差 | 平均值 | 标准差 | 平均值 | 标准差 | ||
| PPO | 4.89 | 0.89 | 0.07 | 0.04 | 0.03 | 0.06 | 85 |
| GPPO | 2.57 | 0.61 | 0.02 | 0.02 | 0.01 | 0.02 | 40 |
Table 8 Online performance comparison of guidance laws under case 2
| 制导律 | 脱靶量/m | 攻击时间误差/s | 攻击角度 误差/(°) | 平均训练 回合数 | |||
|---|---|---|---|---|---|---|---|
| 平均值 | 标准差 | 平均值 | 标准差 | 平均值 | 标准差 | ||
| PPO | 4.89 | 0.89 | 0.07 | 0.04 | 0.03 | 0.06 | 85 |
| GPPO | 2.57 | 0.61 | 0.02 | 0.02 | 0.01 | 0.02 | 40 |
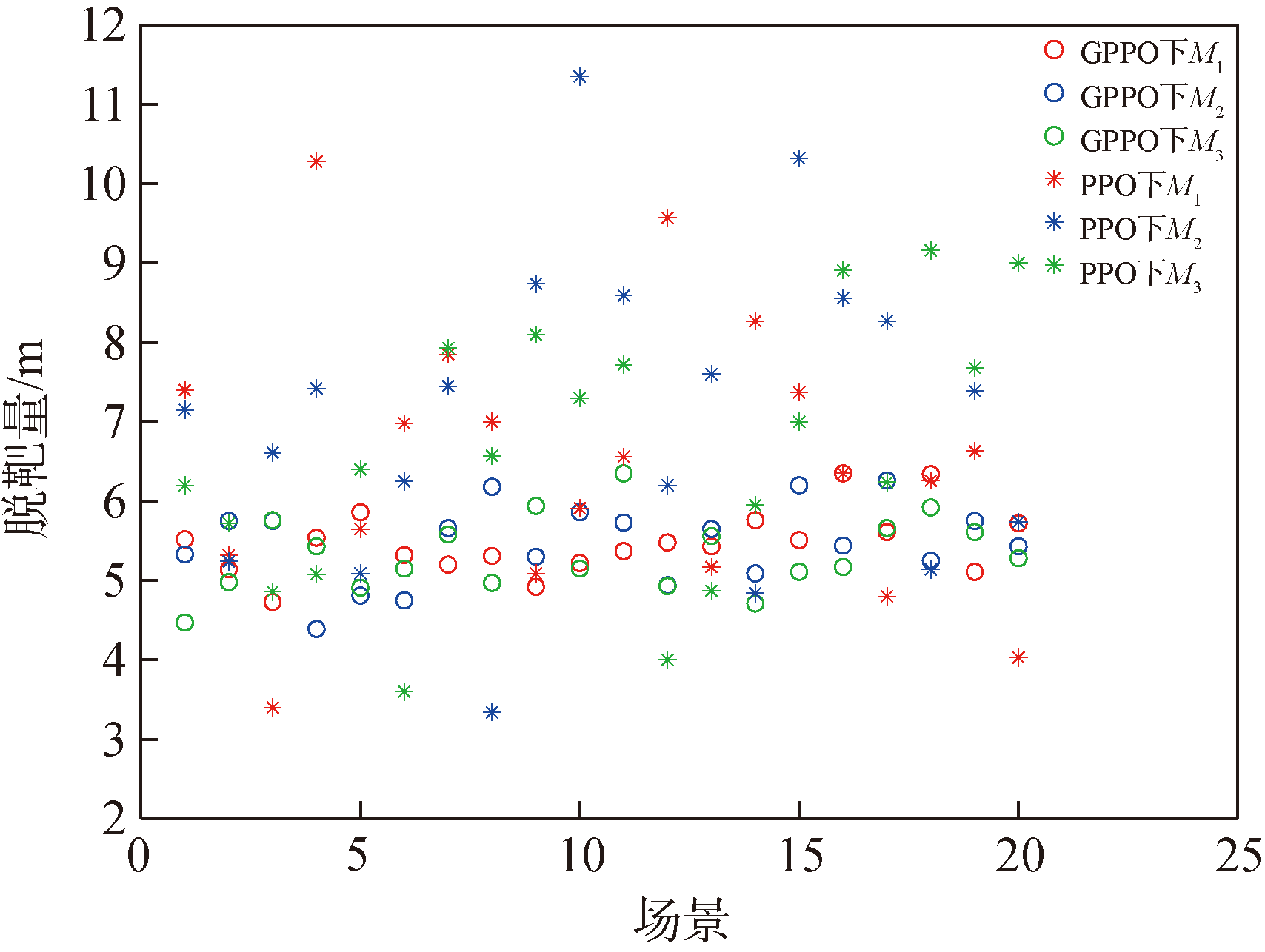
Fig.19 Miss distance in Case 1
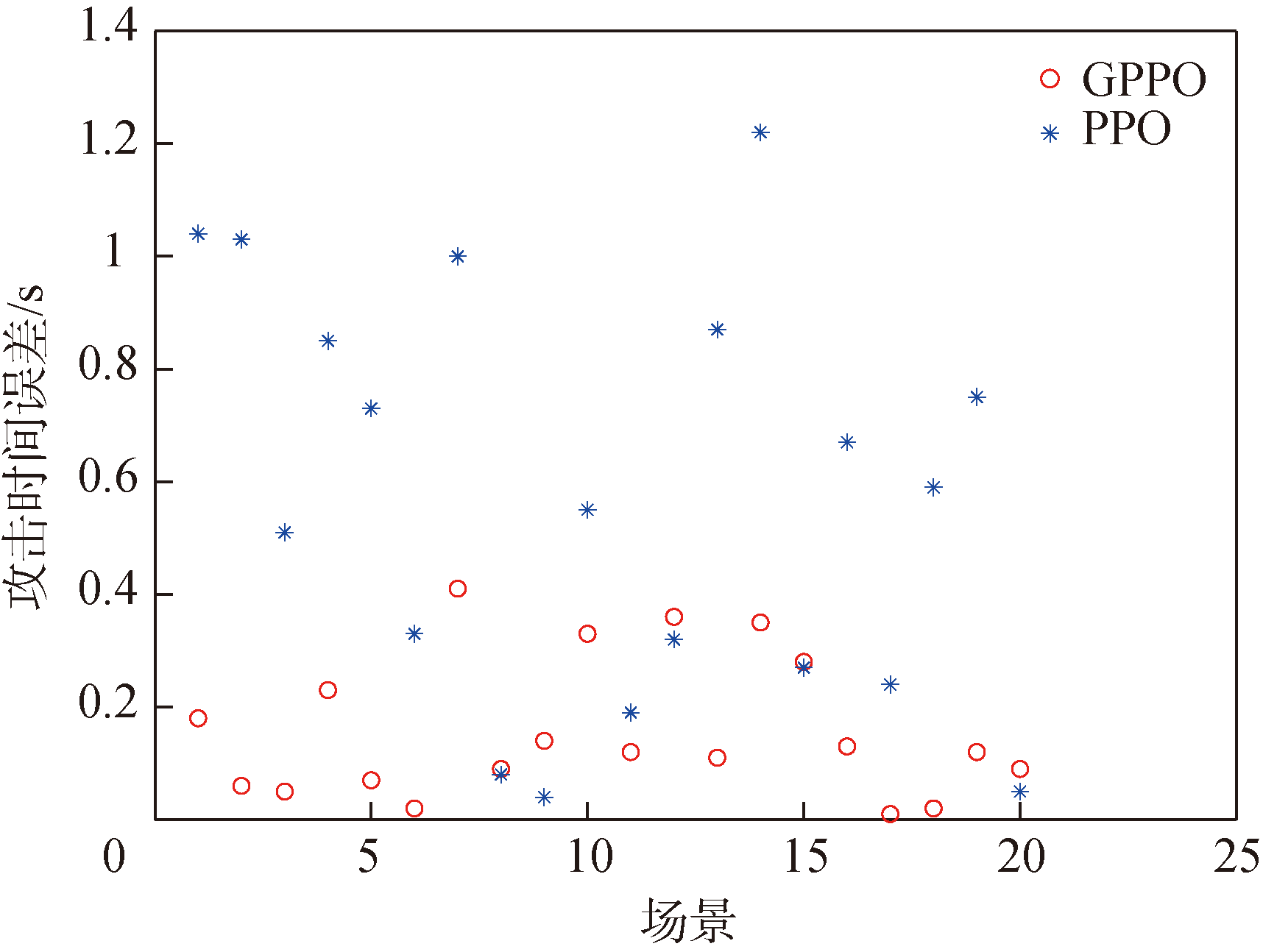
Fig.20 Attack time error in Case 1
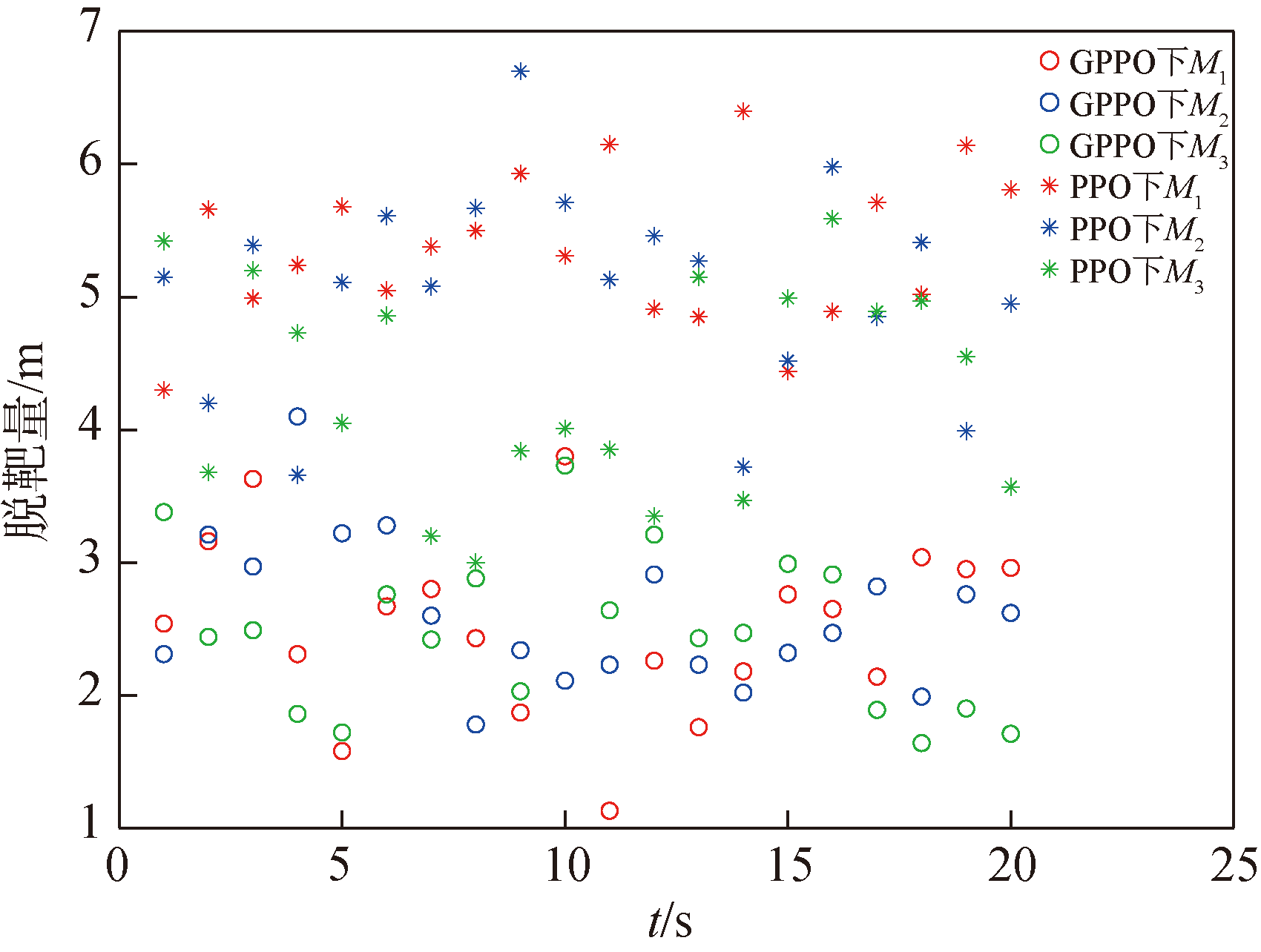
Fig.21 Miss distance in Case 2
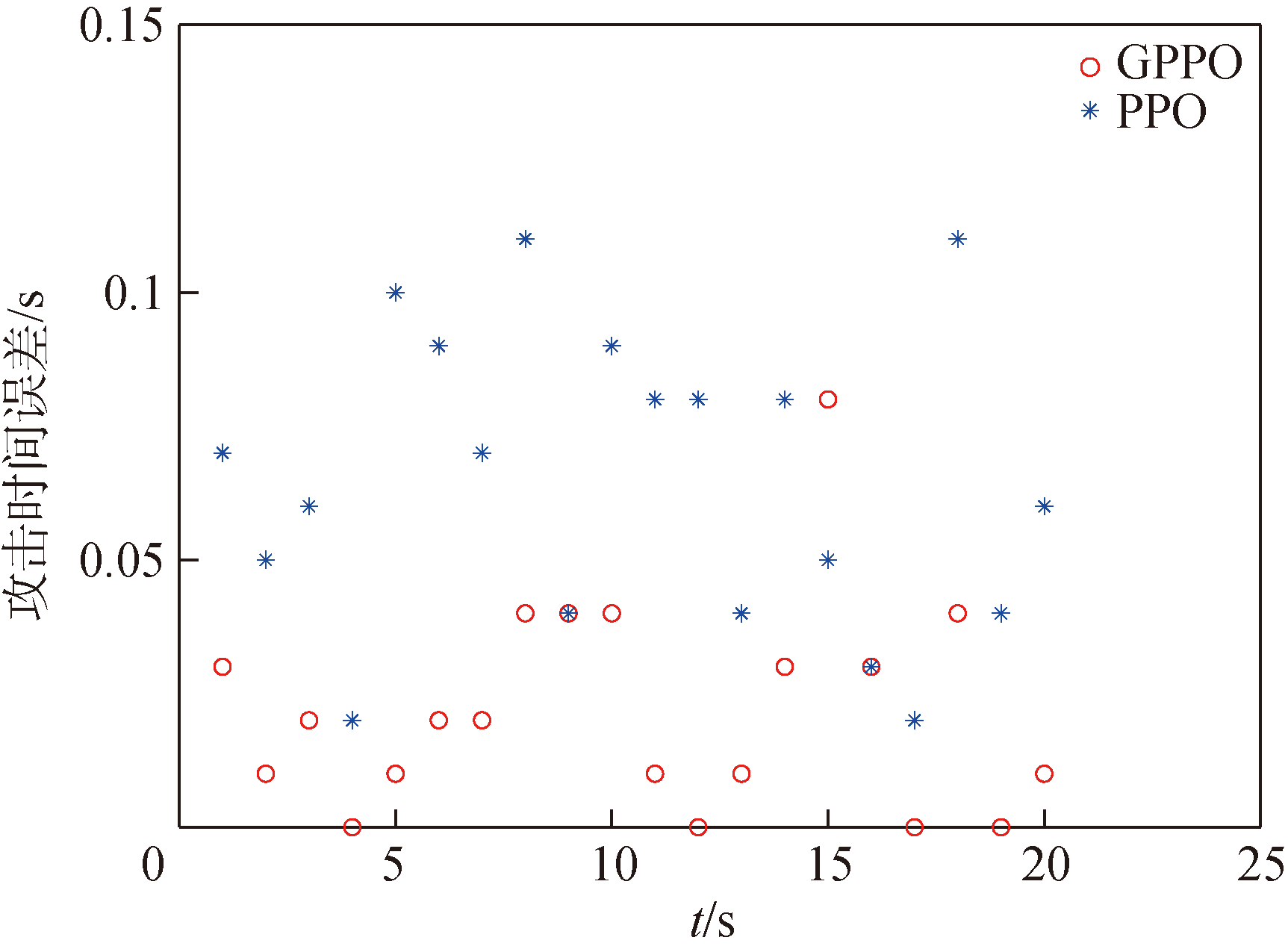
Fig.22 Attack time error in Case 2
| 参数 | 数值 |
|---|---|
| 目标位置/m | (42064,0,3535) |
| 弹1弹道偏角/(°) | 2 |
| 弹2弹道偏角/(°) | -17 |
| 弹3弹道偏角/(°) | 5 |
| 期望攻击角度/(°) | -65 |
Table 9 The parameters table of Scenario 1
| 参数 | 数值 |
|---|---|
| 目标位置/m | (42064,0,3535) |
| 弹1弹道偏角/(°) | 2 |
| 弹2弹道偏角/(°) | -17 |
| 弹3弹道偏角/(°) | 5 |
| 期望攻击角度/(°) | -65 |
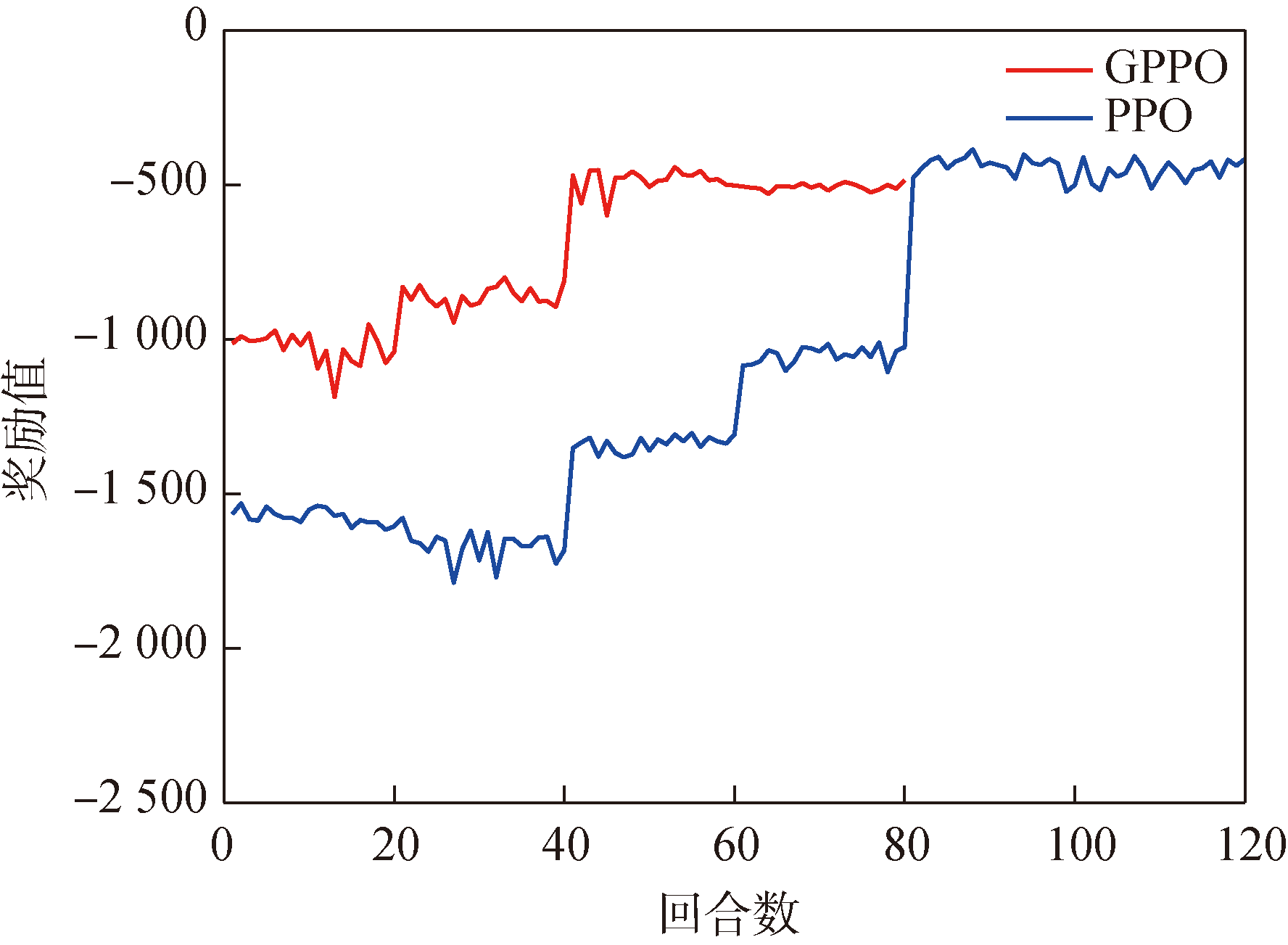
Fig.23 Cooperative guidance network reward in Scenario 1

Fig.24 Missile trajectory in Scenario 1
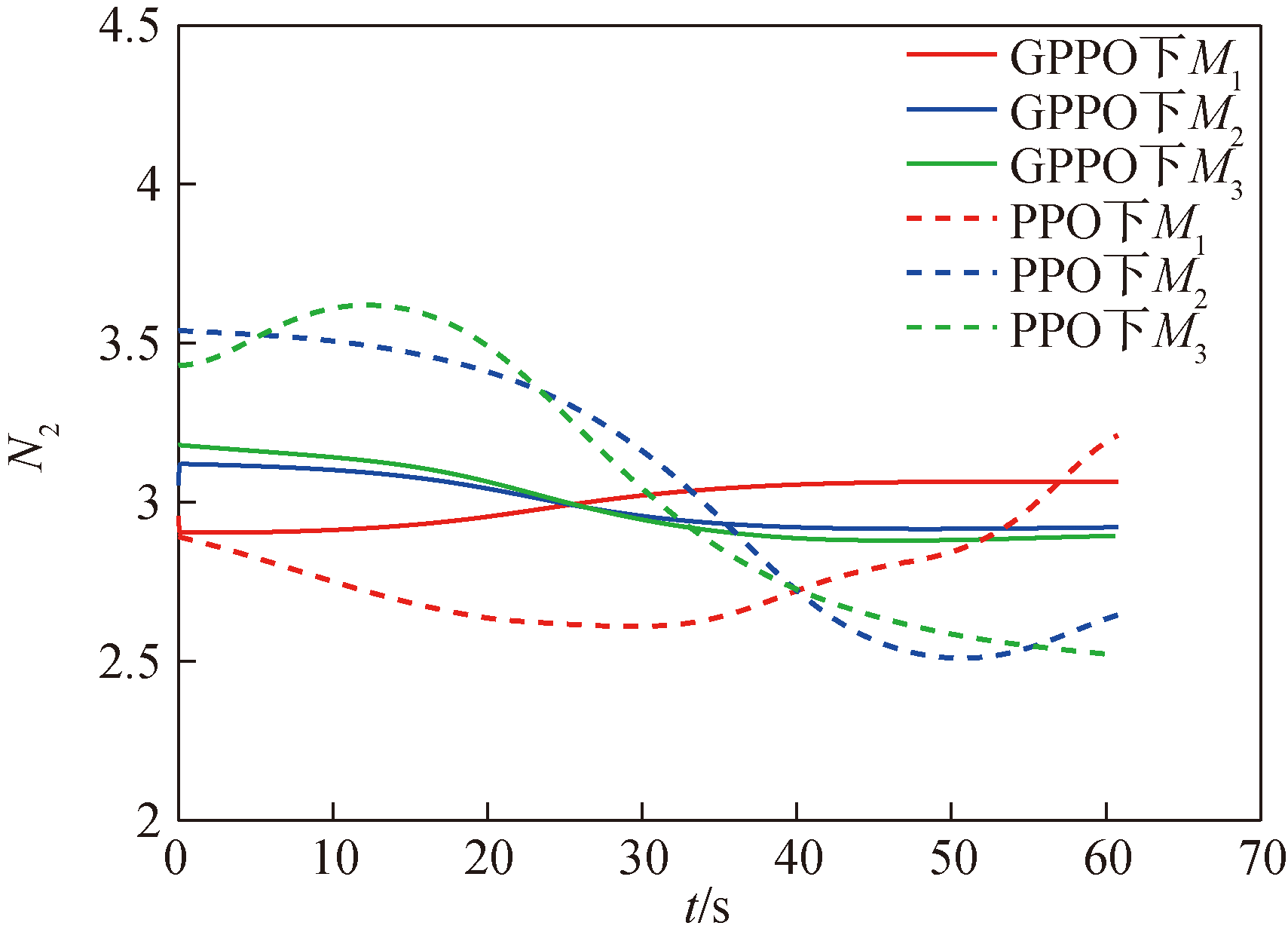
Fig.25 Variation curves of missile guidance coefficients in Scenario 1
| 参数 | 平均值 | 标准差 |
|---|---|---|
| 脱靶量/m | 4.28 | 0.78 |
| 攻击时间误差/s | 0.05 | 0.03 |
| 攻击角度/(°) | -65.02 | 0.07 |
| 训练回合数 | 59 | - |
Table 10 Performance parameters of PPO2 guidance law
| 参数 | 平均值 | 标准差 |
|---|---|---|
| 脱靶量/m | 4.28 | 0.78 |
| 攻击时间误差/s | 0.05 | 0.03 |
| 攻击角度/(°) | -65.02 | 0.07 |
| 训练回合数 | 59 | - |
| 参数 | 数值 |
|---|---|
| 目标位置/m | (42000,0,3500) |
| 弹1弹道偏角/(°) | 2 |
| 弹2弹道偏角/(°) | -15 |
| 弹3弹道偏角/(°) | 10 |
| 期望攻击角度/(°) | -70 |
Table 11 The parameters table of Scenario 2
| 参数 | 数值 |
|---|---|
| 目标位置/m | (42000,0,3500) |
| 弹1弹道偏角/(°) | 2 |
| 弹2弹道偏角/(°) | -15 |
| 弹3弹道偏角/(°) | 10 |
| 期望攻击角度/(°) | -70 |

Fig.26 Missile trajectory in Scenario 2
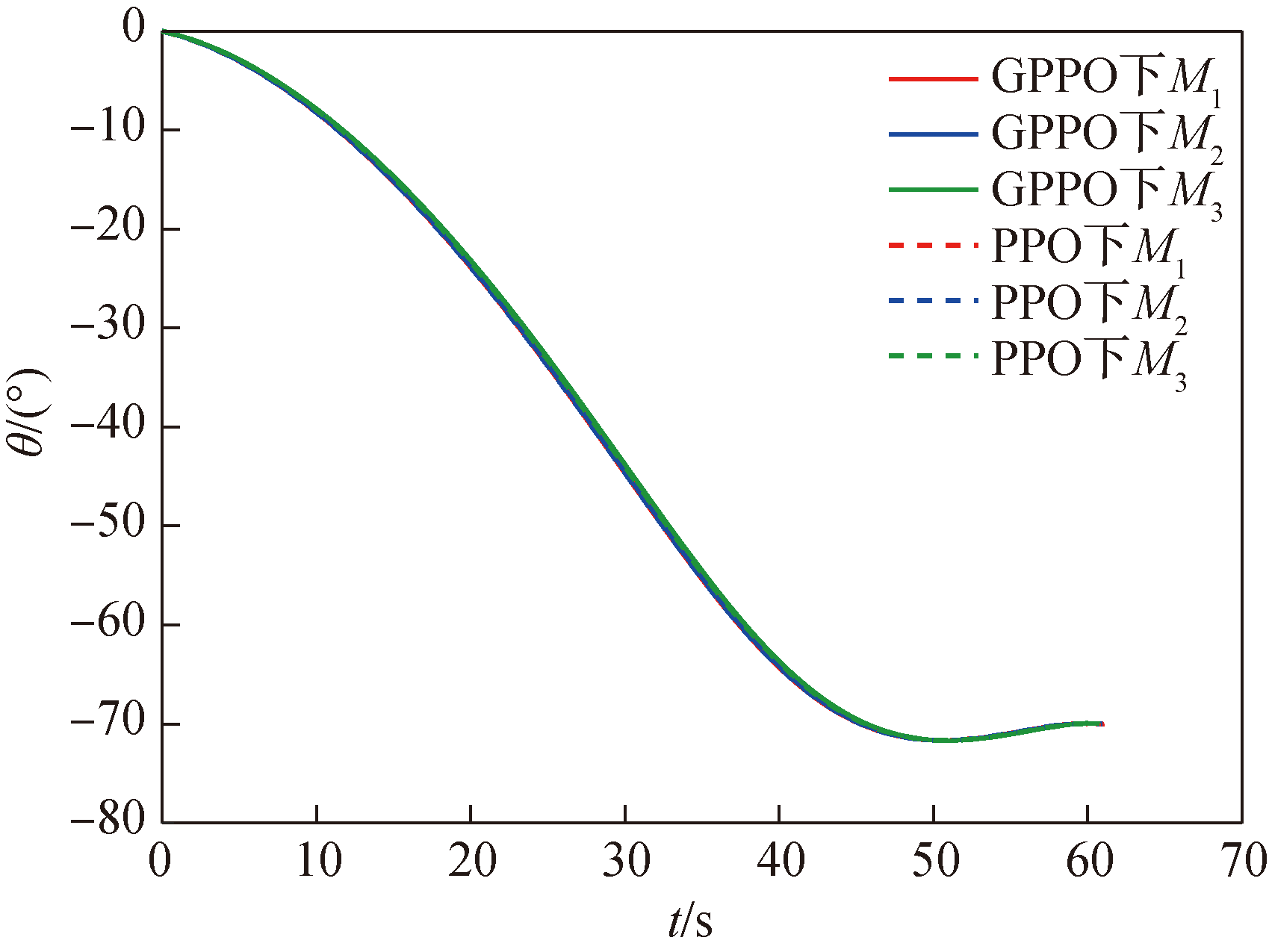
Fig.27 Missile trajectory inclination angle θ over time in Scenario 2
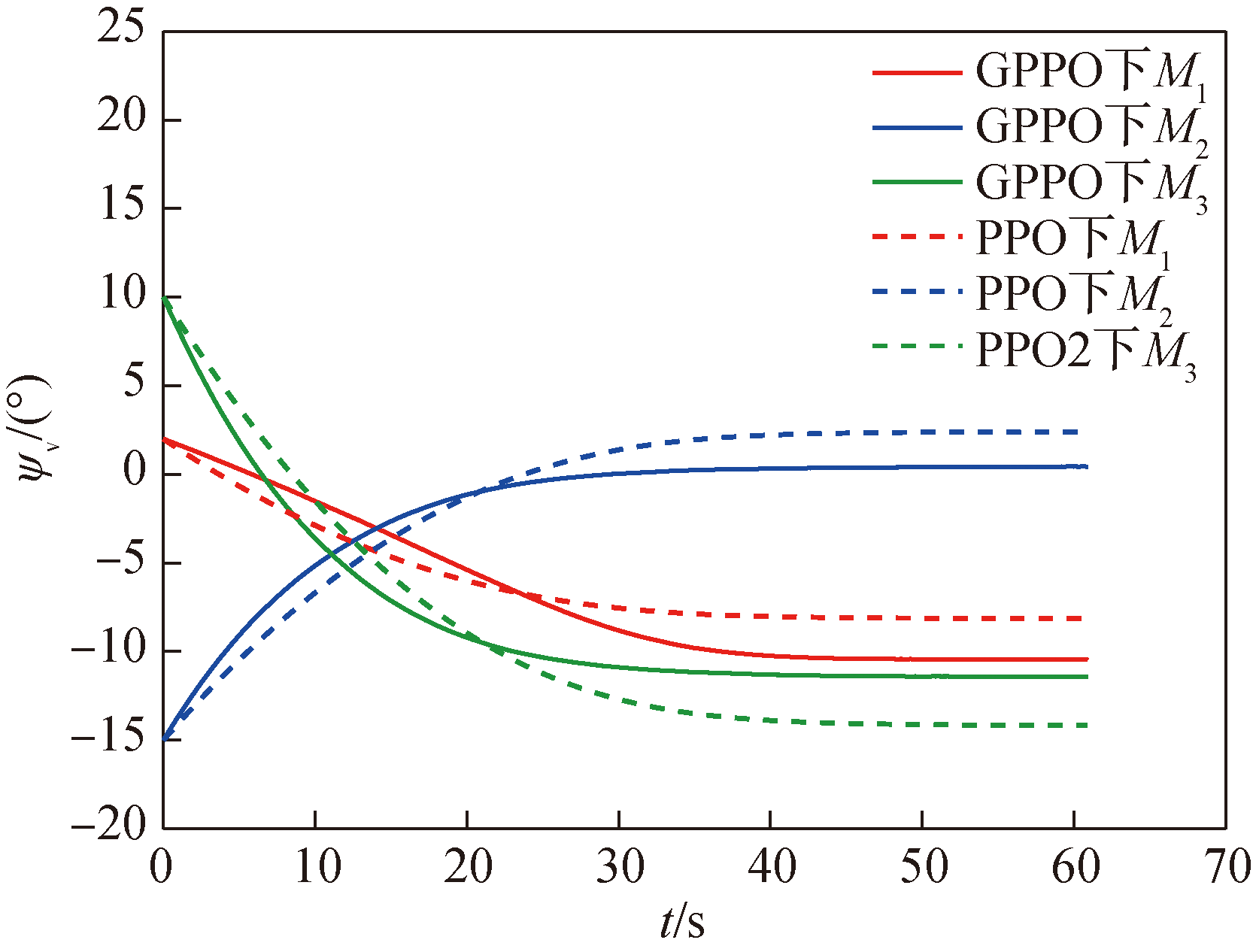
Fig.28 Missile trajectory deviation angle ψV over time in Scenario 2
| [1] |
|
| [2] |
|
| [3] |
黎克波, 廖选平, 梁彦刚, 等. 基于纯比例导引的拦截碰撞角约束制导策略[J]. 航空学报, 2020, 41(增刊2):724277.
|
|
|
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
李国飞, 汤清璞, 吴云洁. 从飞行器无导引头的主-从式多飞行器协同制导方法[J]. 兵工学报, 2023, 44(11):3436-3446.
doi: 10.12382/bgxb.2023.0678 |
|
doi: 10.12382/bgxb.2023.0678 |
|
| [12] |
|
| [13] |
|
| [14] |
doi: 10.23919/JSEE.2021.000038 |
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
陈中原, 韦文书, 陈万春. 基于强化学习的多发导弹协同攻击智能制导律[J]. 兵工学报, 2021, 42(8):1638-1647.
|
|
|
|
| [20] |
李博皓, 安旭曼, 杨晓飞, 等. 攻击角度约束下的分布式强化学习制导方法[J]. 宇航学报, 2022, 43(8):1061-1069.
|
|
|
|
| [21] |
|
| [22] |
刘旭, 李响, 王晓鹏. 高超声速滑翔飞行器解析协同再入制导[J]. 宇航学报, 2023, 44(5):731-742.
|
|
|
|
| [23] |
高峰, 唐胜景, 师娇, 等. 一种基于落角约束的偏置比例导引律[J]. 北京理工大学学报, 2014, 34(3):277-282.
|
|
|
|
| [24] |
李东旭, 王晓芳, 林海. 多高超声速导弹协同末制导律及可行初始位置域研究[J]. 弹道学报, 2019, 31(4):1-7.
doi: 10.12115/j.issn.1004-499X(2019)04-001 |
|
doi: 10.12115/j.issn.1004-499X(2019)04-001 |
| [1] | LU Xiaoran, ZOU Yuan, ZHANG Xudong, SUN Wei, MENG Yihao, ZHANG Bin. Energy Management Strategy Optimized by Munchausen-PER-DDQN for Hybrid Tracked Vehicle [J]. Acta Armamentarii, 2025, 46(6): 240498-. |
| [2] | WANG Jiang, ZHU Ziyang, LI Hongyan, WANG Peng. An Energy-optimal Relative-angle-constrained Cooperative Guidance Method Based on Distributed Convex Optimization [J]. Acta Armamentarii, 2025, 46(6): 240739-. |
| [3] | ZHOU Zhenlin, LONG Teng, LIU Dawei, SUN Jingliang, ZHONG Jianxin, LI Junzhi. Path Planning Method for Large-scale UAV Swarms Based on Reinforcement Learning Conflict Resolution [J]. Acta Armamentarii, 2025, 46(5): 241146-. |
| [4] | XIAN Sujie, WANG Kang, ZENG Xin, SONG Jie, WU Zhilin. An Impact Angle and Field of View Constraints Guidance Law Based on Deep Reinforcement Learning [J]. Acta Armamentarii, 2025, 46(4): 240435-. |
| [5] | PAN Yunwei, LI Min, ZENG Xiangguang, HUANG Ao, ZHANG Jiaheng, REN Wenzhe, PENG Bei. AUV Obstacle Avoidance and Path Planning Based on Artificial Potential Field and Improved Reinforcement Learning [J]. Acta Armamentarii, 2025, 46(4): 240300-. |
| [6] | LI Chuanhao, MING Zhenjun, WANG Guoxin, YAN Yan, DING Wei, WAN Silai, DING Tao. Dynamic Decision-making Method of Unmanned Platform Chaff Jamming for Terminal Defense Based on Multi-agent Deep Reinforcement Learning [J]. Acta Armamentarii, 2025, 46(3): 240251-. |
| [7] | ZHANG Wang, SHAO Xuehui, TANG Huilong, WEI Jianlin, WANG Wei. A Reinforcement Learning-based Radar Jamming Decision-making Method with Adaptive Setting of Exploration Rate [J]. Acta Armamentarii, 2025, 46(3): 240357-. |
| [8] | XIAO Liujun, LI Yaxuan, LIU Xinfu. Adaptive Terminal Guidance for Hypersonic Gliding Vehicles Using Reinforcement Learning [J]. Acta Armamentarii, 2025, 46(2): 240222-. |
| [9] | HU Yanyang, HE Fan, BAI Chengchao. Cooperative Obstacle Avoidance Decision Method for the Terminal Guidance Phase of Hypersonic Vehicles [J]. Acta Armamentarii, 2024, 45(9): 3147-3160. |
| [10] | SUN Hao, LI Haiqing, LIANG Yan, MA Chaoxiong, WU Han. Dynamic Penetration Decision of Loitering Munition Group Based on Knowledge-assisted Reinforcement Learning [J]. Acta Armamentarii, 2024, 45(9): 3161-3176. |
| [11] | CHEN Wenjie, CUI Xiaohong, WANG Binrui. Safety Optimal Tracking Control Algorithm and Robot Arm Simulation [J]. Acta Armamentarii, 2024, 45(8): 2688-2697. |
| [12] | YU Hang, LI Qingyu, DAI Keren, LI Haojie, ZOU Yao, ZHANG He. Three-dimensional Adaptive Fixed-time Multi-missile Cooperative Guidance Law [J]. Acta Armamentarii, 2024, 45(8): 2646-2657. |
| [13] | ZHANG Kun, HUA Shuai, YUAN Binlin, LI Yang. Multi-platform Networked Guidance Handover Technology [J]. Acta Armamentarii, 2024, 45(7): 2171-2181. |
| [14] | WANG Xiaolong, CHEN Yang, HU Mian, LI Xudong. Robot Path Planning for Persistent Monitoring Based on Improved Deep Q Networks [J]. Acta Armamentarii, 2024, 45(6): 1813-1823. |
| [15] | LOU Shuhan, WANG Chongchong, GONG Wei, DENG Liyuan, LI Li. Collaborative Regional Information Collection Strategy Based on MLAT-DRL Algorithm [J]. Acta Armamentarii, 2024, 45(12): 4423-4434. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||