
Responsible Institution: China Association for Science and Technology
Sponsor: China Ordnance Society
ISSN 1000-1093 CN 11-2176/TJ
Sponsor: China Ordnance Society
ISSN 1000-1093 CN 11-2176/TJ
Acta Armamentarii ›› 2025, Vol. 46 ›› Issue (3): 240357-.doi: 10.12382/bgxb.2024.0357
Previous Articles Next Articles
ZHANG Wang, SHAO Xuehui, TANG Huilong, WEI Jianlin, WANG Wei*( )
)
Received:2024-05-10
Online:2025-03-26
Contact:
WANG Wei
ZHANG Wang, SHAO Xuehui, TANG Huilong, WEI Jianlin, WANG Wei. A Reinforcement Learning-based Radar Jamming Decision-making Method with Adaptive Setting of Exploration Rate[J]. Acta Armamentarii, 2025, 46(3): 240357-.
Add to citation manager EndNote|Ris|BibTeX

Fig.1 Radar jamming decision-making based on reinforcement learning
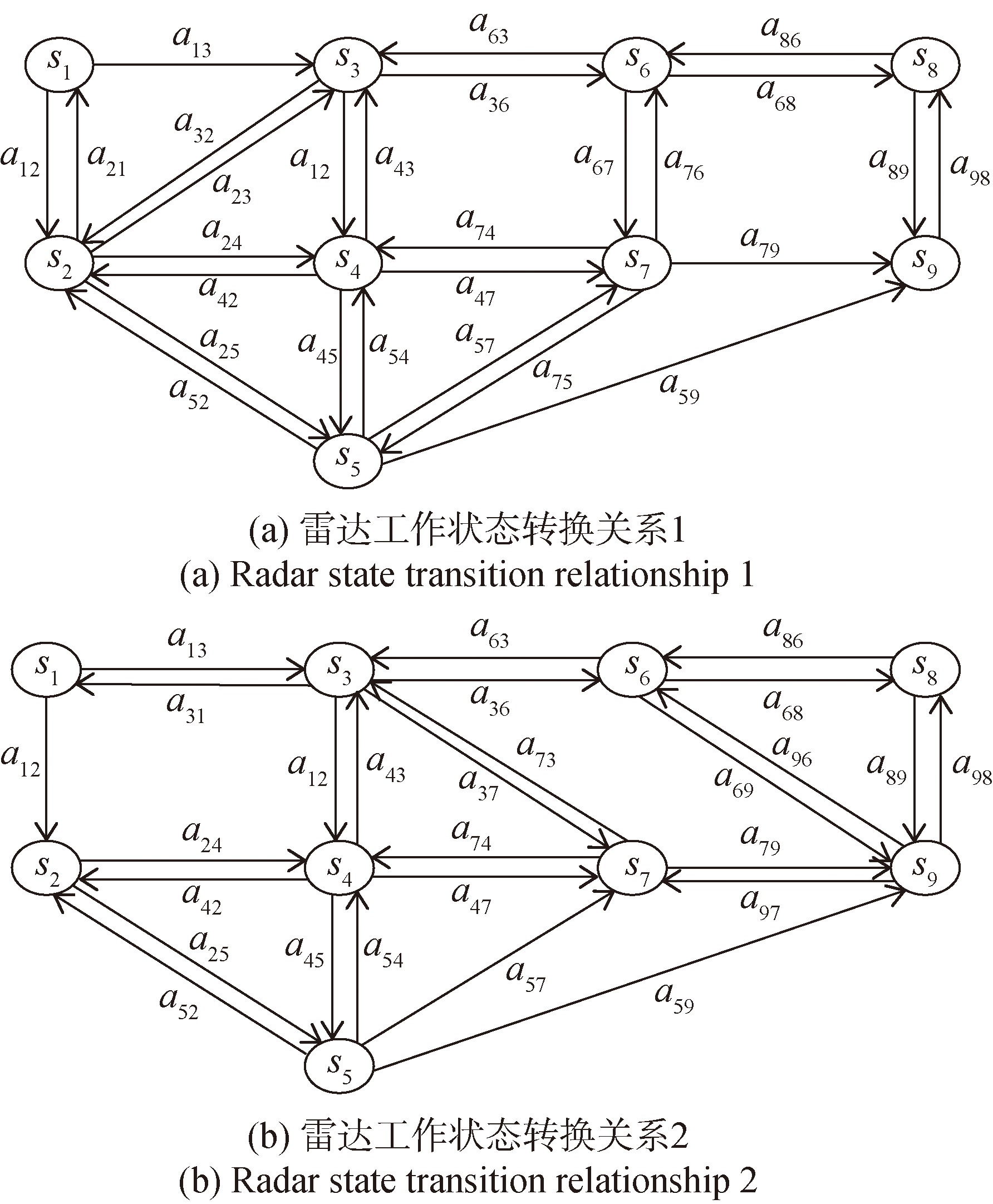
Fig.2 Radar state transition relationship
| S | S' | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
| 1 | 0.65 | 0.07 | 0.28 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0.13 | 0.35 | 0.11 | 0.34 | 0.07 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0.54 | 0.20 | 0.11 | 0 | 0.15 | 0 | 0 | 0 |
| 4 | 0 | 0.22 | 0.17 | 0.12 | 0.29 | 0 | 0.20 | 0 | 0 |
| 5 | 0 | 0.17 | 0 | 0.28 | 0.09 | 0 | 0.23 | 0 | 0.23 |
| 6 | 0 | 0 | 0.35 | 0 | 0 | 0.53 | 0.07 | 0.05 | 0 |
| 7 | 0 | 0 | 0 | 0.18 | 0.27 | 0.32 | 0.04 | 0 | 0.19 |
| 8 | 0 | 0 | 0 | 0 | 0 | 0.57 | 0 | 0.02 | 0.41 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.17 | 0.83 |
Table 1 State transition matrix
| S | S' | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
| 1 | 0.65 | 0.07 | 0.28 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0.13 | 0.35 | 0.11 | 0.34 | 0.07 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0.54 | 0.20 | 0.11 | 0 | 0.15 | 0 | 0 | 0 |
| 4 | 0 | 0.22 | 0.17 | 0.12 | 0.29 | 0 | 0.20 | 0 | 0 |
| 5 | 0 | 0.17 | 0 | 0.28 | 0.09 | 0 | 0.23 | 0 | 0.23 |
| 6 | 0 | 0 | 0.35 | 0 | 0 | 0.53 | 0.07 | 0.05 | 0 |
| 7 | 0 | 0 | 0 | 0.18 | 0.27 | 0.32 | 0.04 | 0 | 0.19 |
| 8 | 0 | 0 | 0 | 0 | 0 | 0.57 | 0 | 0.02 | 0.41 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.17 | 0.83 |
| S | S' | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
| 1 | 0.32 | 0.35 | 0.32 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0.32 | 0 | 0.16 | 0.52 | 0 | 0 | 0 | 0 |
| 3 | 0.02 | 0 | 0.18 | 0.27 | 0 | 0..21 | 0.32 | 0 | 0 |
| 4 | 0 | 0.18 | 0.31 | 0.09 | 0.11 | 0 | 0.31 | 0 | 0 |
| 5 | 0 | 0.16 | 0 | 0.30 | 0.35 | 0 | 0.2 | 0 | 0 |
| 6 | 0 | 0 | 0.26 | 0 | 0 | 0.38 | 0 | 0.15 | 0.21 |
| 7 | 0 | 0 | 0.35 | 0.14 | 0 | 0 | 0.16 | 0 | 0.35 |
| 8 | 0 | 0 | 0 | 0 | 0 | 0.21 | 0 | 0.59 | 0.2 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0.41 | 0.05 | 0.04 | 0.50 |
Table 2 State transition matrix 2
| S | S' | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
| 1 | 0.32 | 0.35 | 0.32 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0.32 | 0 | 0.16 | 0.52 | 0 | 0 | 0 | 0 |
| 3 | 0.02 | 0 | 0.18 | 0.27 | 0 | 0..21 | 0.32 | 0 | 0 |
| 4 | 0 | 0.18 | 0.31 | 0.09 | 0.11 | 0 | 0.31 | 0 | 0 |
| 5 | 0 | 0.16 | 0 | 0.30 | 0.35 | 0 | 0.2 | 0 | 0 |
| 6 | 0 | 0 | 0.26 | 0 | 0 | 0.38 | 0 | 0.15 | 0.21 |
| 7 | 0 | 0 | 0.35 | 0.14 | 0 | 0 | 0.16 | 0 | 0.35 |
| 8 | 0 | 0 | 0 | 0 | 0 | 0.21 | 0 | 0.59 | 0.2 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0.41 | 0.05 | 0.04 | 0.50 |
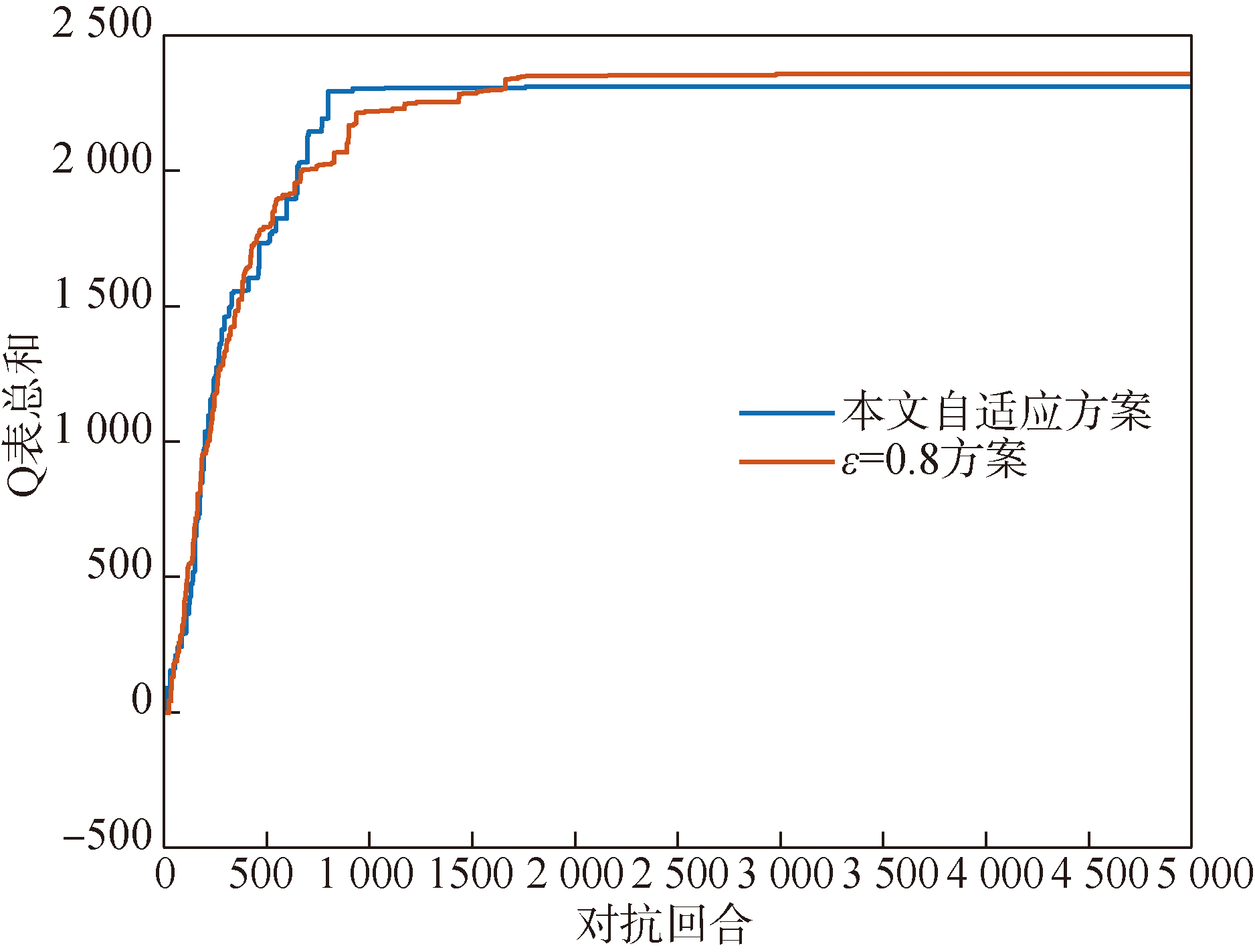
Fig.3 Simulation of exploration rate adaptive setting strategy
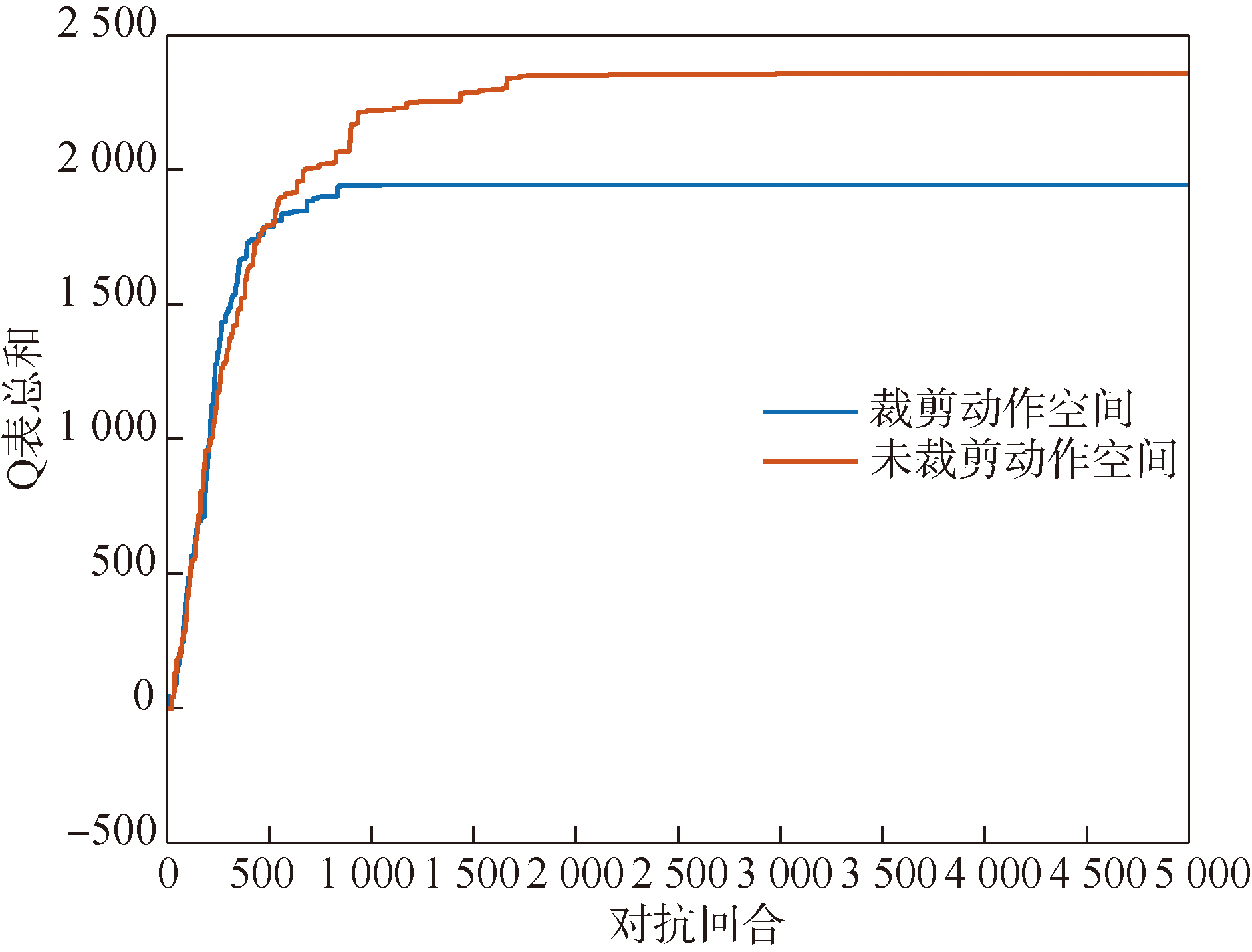
Fig.4 Simulation of jamming action space cropping strategy
| S | a | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
| 1 | 37.0 | 50.1 | 53.6 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 44.4 | 56.5 | 53.6 | 65.8 | 81.0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 50.6 | 41.6 | 61.9 | 0 | 65.8 | 0 | 0 | 0 |
| 4 | 0 | 56.1 | -0.6 | 59.2 | 78.6 | 0 | 81.0 | 0 | 0 |
| 5 | 0 | 54.0 | 0 | 63.7 | 67.4 | 0 | 81.0 | 0 | 100 |
| 6 | 0 | 0 | 49.8 | 0 | 0 | 60.1 | -0.5 | 81 | 0 |
| 7 | 0 | 0 | 0 | 62.4 | 78.9 | 59.8 | 35.5 | 0 | 100 |
| 8 | 0 | 0 | 0 | 0 | 0 | 59.3 | 0 | 0 | 100 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Table 3 Adaptive exploration rate convergence matrix
| S | a | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
| 1 | 37.0 | 50.1 | 53.6 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 44.4 | 56.5 | 53.6 | 65.8 | 81.0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 50.6 | 41.6 | 61.9 | 0 | 65.8 | 0 | 0 | 0 |
| 4 | 0 | 56.1 | -0.6 | 59.2 | 78.6 | 0 | 81.0 | 0 | 0 |
| 5 | 0 | 54.0 | 0 | 63.7 | 67.4 | 0 | 81.0 | 0 | 100 |
| 6 | 0 | 0 | 49.8 | 0 | 0 | 60.1 | -0.5 | 81 | 0 |
| 7 | 0 | 0 | 0 | 62.4 | 78.9 | 59.8 | 35.5 | 0 | 100 |
| 8 | 0 | 0 | 0 | 0 | 0 | 59.3 | 0 | 0 | 100 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
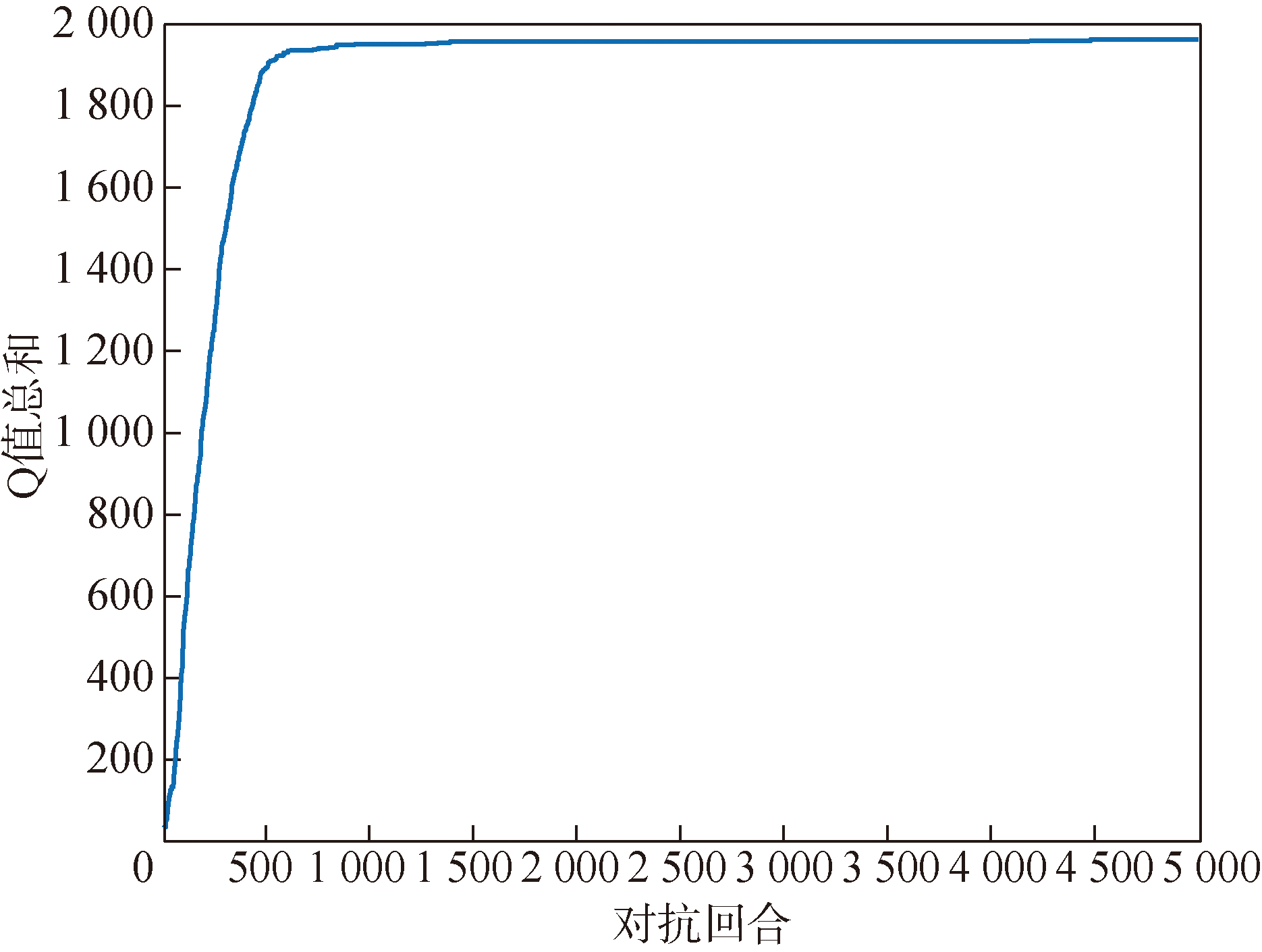
Fig.5 Q-table total convergence curve

Fig.6 Changes in various variables

Fig.7 Adaptive exploration rate
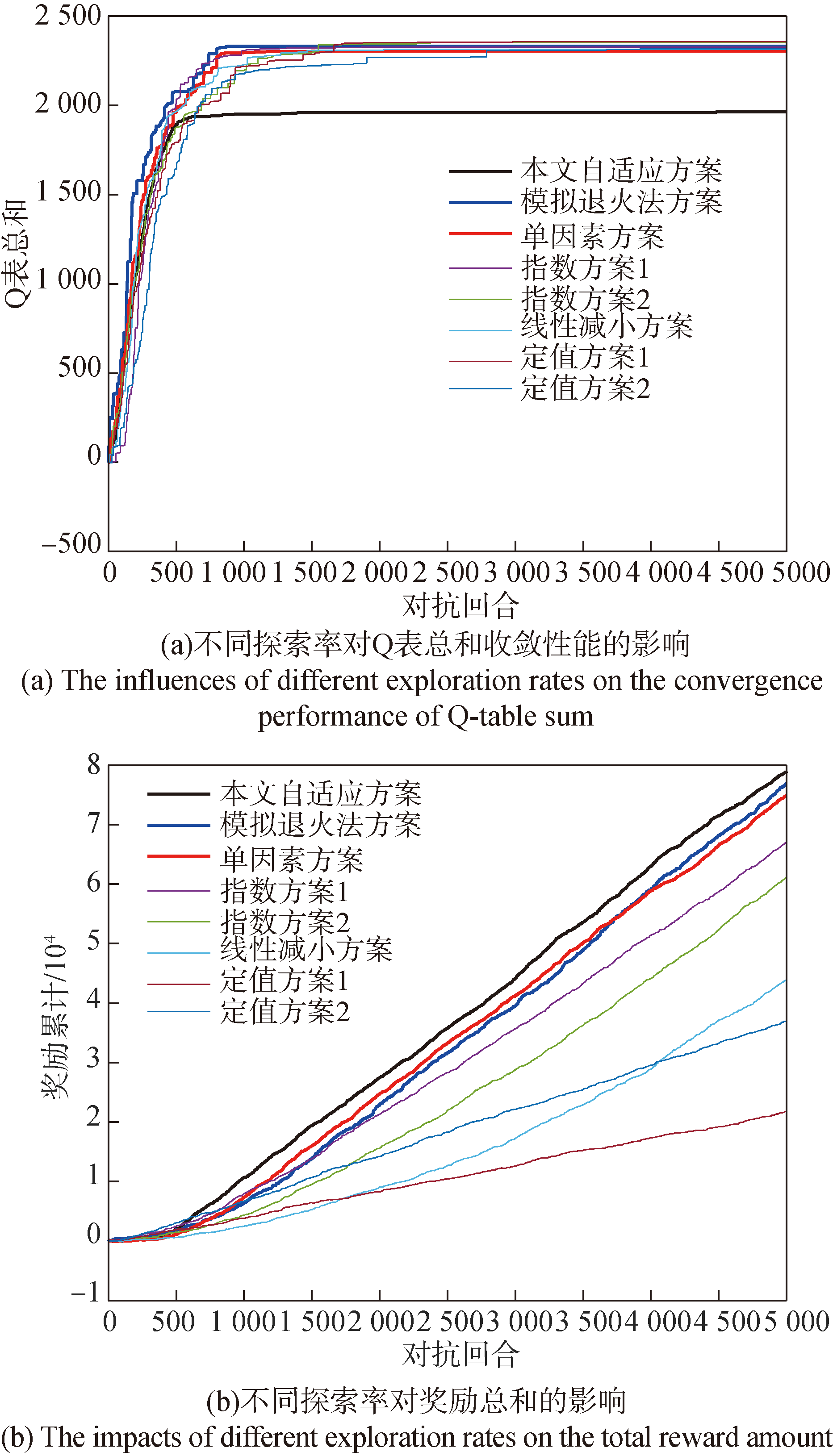
Fig.8 The influences of different exploration rates on the convergence performance of algorithm
| S | a | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
| 1 | 50.1 | 63.8 | 52.2 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 49.5 | 63.8 | 52.1 | 65.8 | 81.0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 63.8 | 51.0 | 63.2 | 0 | 65.0 | 0 | 0 | 0 |
| 4 | 0 | 63.8 | 50.2 | 63.5 | 79.0 | 0 | 81.0 | 0 | 0 |
| 5 | 0 | 63.8 | 0 | 63.8 | 78.9 | 0 | 81.0 | 0 | 100 |
| 6 | 0 | 0 | 50.9 | 0 | 0 | 62.9 | 79 | 79.5 | 0 |
| 7 | 0 | 0 | 0 | 63.5 | 79.0 | 62.2 | 74.3 | 0 | 100 |
| 8 | 0 | 0 | 0 | 0 | 0 | 62.2 | 0 | 24.1 | 100 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Table 4 Exploration rate convergence matrix of simulated annealing method
| S | a | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
| 1 | 50.1 | 63.8 | 52.2 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 49.5 | 63.8 | 52.1 | 65.8 | 81.0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 63.8 | 51.0 | 63.2 | 0 | 65.0 | 0 | 0 | 0 |
| 4 | 0 | 63.8 | 50.2 | 63.5 | 79.0 | 0 | 81.0 | 0 | 0 |
| 5 | 0 | 63.8 | 0 | 63.8 | 78.9 | 0 | 81.0 | 0 | 100 |
| 6 | 0 | 0 | 50.9 | 0 | 0 | 62.9 | 79 | 79.5 | 0 |
| 7 | 0 | 0 | 0 | 63.5 | 79.0 | 62.2 | 74.3 | 0 | 100 |
| 8 | 0 | 0 | 0 | 0 | 0 | 62.2 | 0 | 24.1 | 100 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
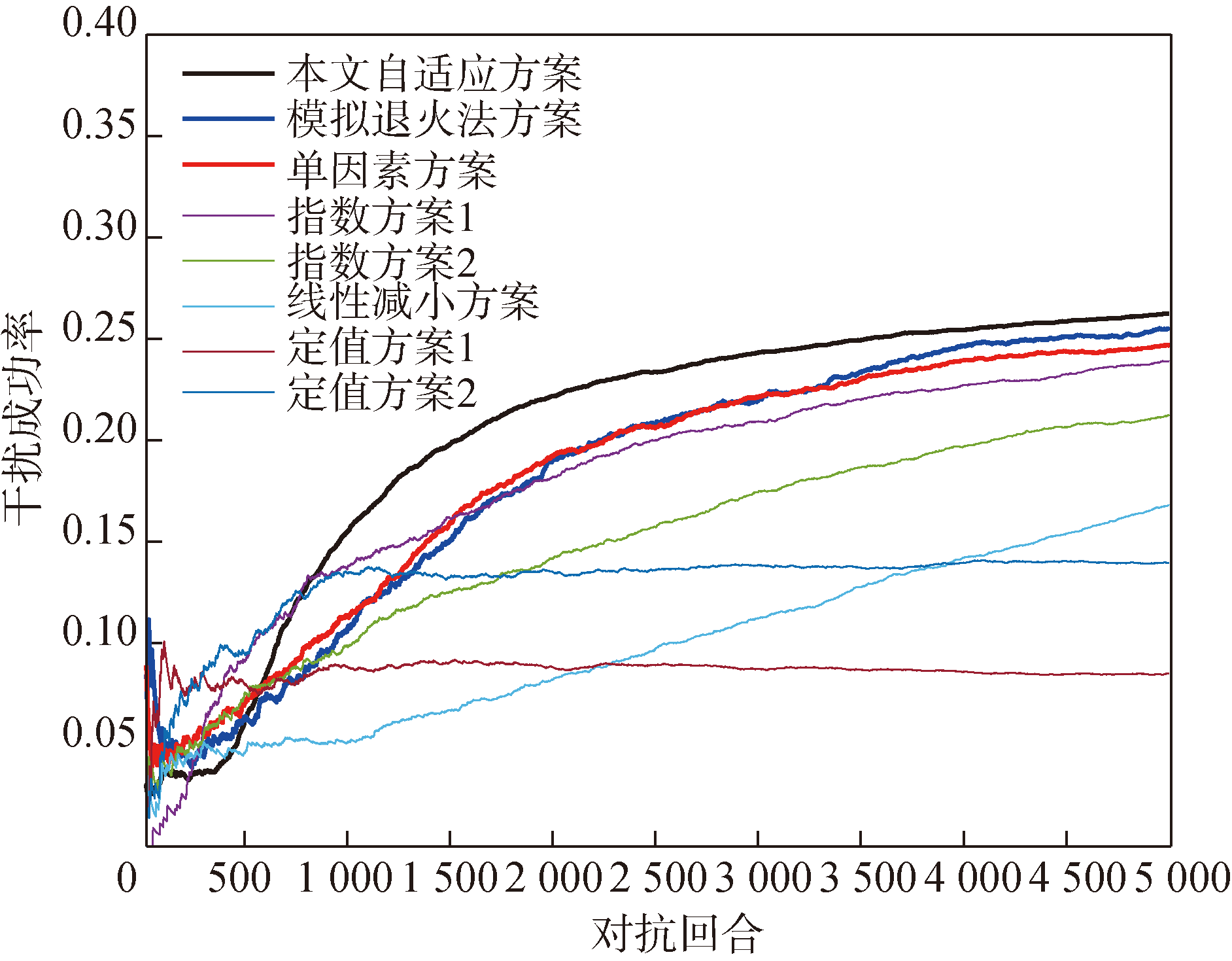
Fig.9 Jamming success rates under different exploration rates
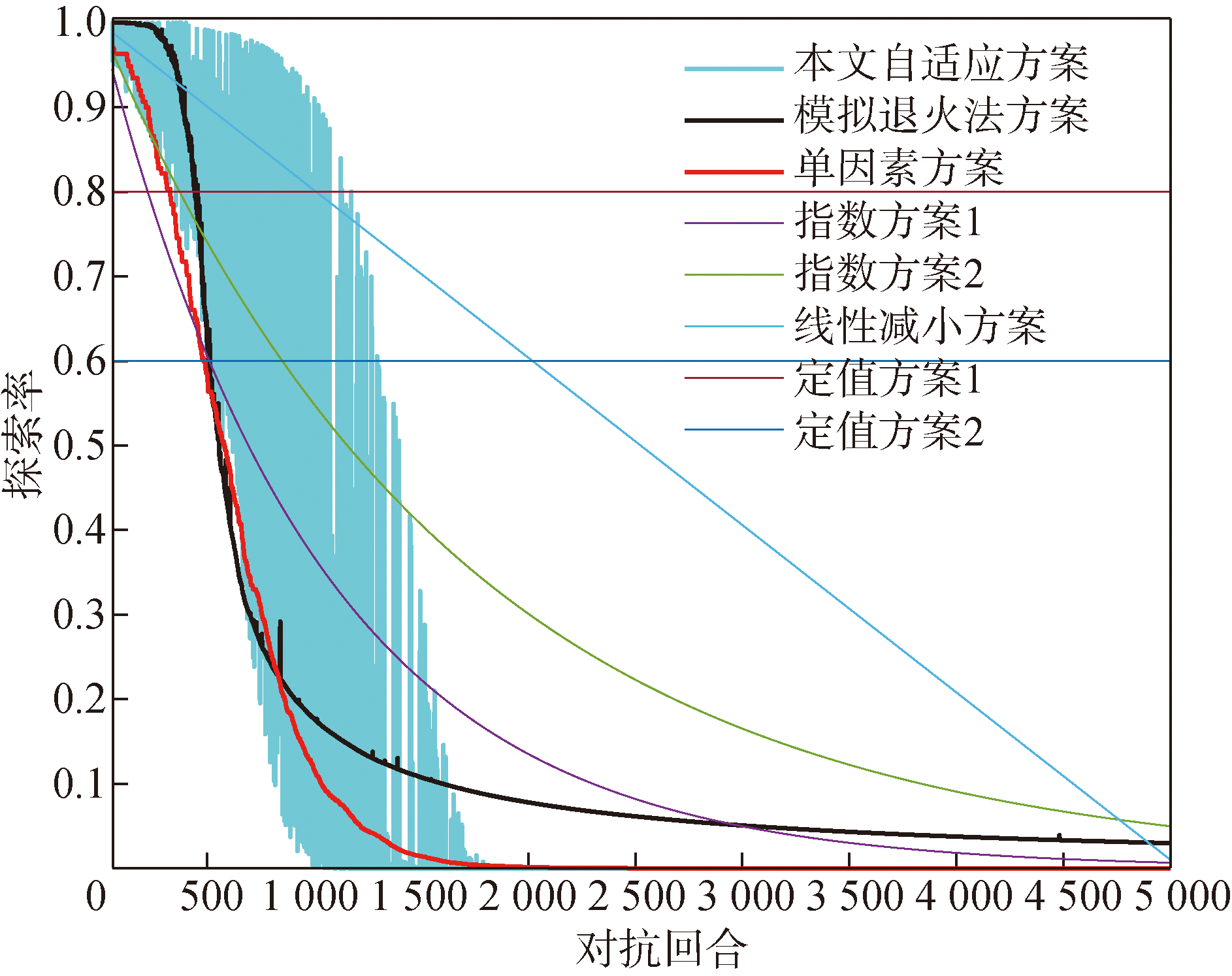
Fig.10 Different exploration rate curves
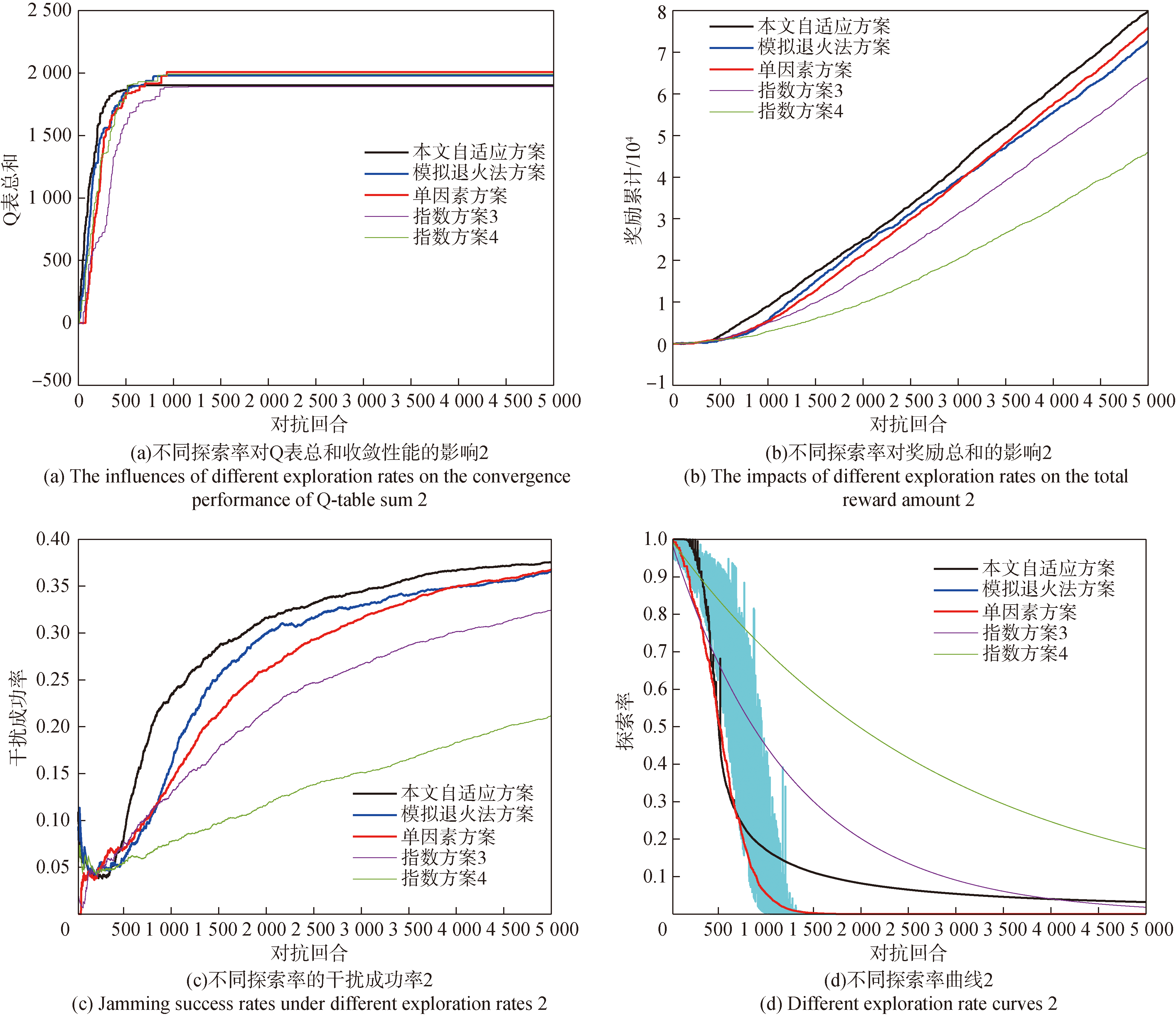
Fig.11 Performance comparison
| [1] |
张柏开, 朱卫纲. MFR认知干扰决策体系构建及关键技术[J]. 系统工程与电子技术, 2020, 42(9):1969-1975.
doi: 10.3969/j.issn.1001-506X.2020.09.12 |
|
|
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
黄知涛, 王翔, 赵雨睿. 认知电子战综述[J]. 国防科技大学学报, 2023, 45(5):1-11.
|
|
|
|
| [6] |
|
| [7] |
冯路为, 刘松涛, 徐华志. 基于POMDP模型的智能雷达干扰决策方法[J]. 系统工程与电子技术, 2023, 45(9):2755-2760.
doi: 10.12305/j.issn.1001-506X.2023.09.13 |
|
|
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
李云杰, 朱云鹏, 高梅国. 基于Q-学习算法的认知雷达对抗过程设计[J]. 北京理工大学学报, 2015, 35(11):1194-1199.
|
|
|
|
| [13] |
邢强, 贾鑫, 朱卫纲. 基于Q-学习的智能雷达对抗[J]. 系统工程与电子技术, 2018, 40(5):1031-1035.
|
|
|
|
| [14] |
张柏开, 朱卫纲. 基于Q-Learning的多功能雷达认知干扰决策方法[J]. 电讯技术, 2020, 60(2):129-136.
|
|
|
|
| [15] |
张柏开, 朱卫纲. 对多功能雷达的DQN认知干扰决策方法[J]. 系统工程与电子技术, 2020, 42(4):819-825.
doi: 10.3969/j.issn.1001-506X.2020.04.12 |
|
|
|
| [16] |
朱霸坤, 朱卫纲, 李伟, 等. 基于先验知识的多功能雷达智能干扰决策方法[J]. 系统工程与电子技术, 2022, 44(12):3685-3695.
doi: 10.12305/j.issn.1001-506X.2022.12.12 |
|
|
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
廖艳苹, 谢榕浩. 基于双层强化学习的多功能雷达认知干扰决策方法[J]. 应用科技, 2023, 50(6):56-62.
|
|
|
|
| [21] |
|
| [22] |
侯志杰. 雷达个体识别及干扰决策[D]. 西安: 西安电子科技大学, 2021.
|
|
|
|
| [23] |
尹依伊, 王晓芳, 周健. 基于Q学习的多无人机协同航迹规划方法[J]. 兵工学报, 2023, 44(2):484-495.
doi: 10.12382/bgxb.2021.0606 |
|
|
|
| [24] |
毛少卿. 基于强化学习的智能干扰决策方法研究[D]. 哈尔滨: 哈尔滨工业大学, 2021.
|
|
|
| [1] | LI Chuanhao, MING Zhenjun, WANG Guoxin, YAN Yan, DING Wei, WAN Silai, DING Tao. Dynamic Decision-making Method of Unmanned Platform Chaff Jamming for Terminal Defense Based on Multi-agent Deep Reinforcement Learning [J]. Acta Armamentarii, 2025, 46(3): 240251-. |
| [2] | XIAO Liujun, LI Yaxuan, LIU Xinfu. Adaptive Terminal Guidance for Hypersonic Gliding Vehicles Using Reinforcement Learning [J]. Acta Armamentarii, 2025, 46(2): 240222-. |
| [3] | SUN Hao, LI Haiqing, LIANG Yan, MA Chaoxiong, WU Han. Dynamic Penetration Decision of Loitering Munition Group Based on Knowledge-assisted Reinforcement Learning [J]. Acta Armamentarii, 2024, 45(9): 3161-3176. |
| [4] | HU Yanyang, HE Fan, BAI Chengchao. Cooperative Obstacle Avoidance Decision Method for the Terminal Guidance Phase of Hypersonic Vehicles [J]. Acta Armamentarii, 2024, 45(9): 3147-3160. |
| [5] | CHEN Wenjie, CUI Xiaohong, WANG Binrui. Safety Optimal Tracking Control Algorithm and Robot Arm Simulation [J]. Acta Armamentarii, 2024, 45(8): 2688-2697. |
| [6] | WANG Xiaolong, CHEN Yang, HU Mian, LI Xudong. Robot Path Planning for Persistent Monitoring Based on Improved Deep Q Networks [J]. Acta Armamentarii, 2024, 45(6): 1813-1823. |
| [7] | DONG Mingze, WEN Zhuanglei, CHEN Xiai, YANG Jiongkun, ZENG Tao. Research on Robot Navigation Method Integrating Safe Convex Space and Deep Reinforcement Learning [J]. Acta Armamentarii, 2024, 45(12): 4372-4382. |
| [8] | LOU Shuhan, WANG Chongchong, GONG Wei, DENG Liyuan, LI Li. Collaborative Regional Information Collection Strategy Based on MLAT-DRL Algorithm [J]. Acta Armamentarii, 2024, 45(12): 4423-4434. |
| [9] | LI Jiashen, WANG Xiaofang, LIN Hai. Intelligent Penetration Policy for Hypersonic Cruise Missiles Based on Virtual Targets [J]. Acta Armamentarii, 2024, 45(11): 3856-3867. |
| [10] | FU Yanfang, LEI Kailin, WEI Jianing, CAO Zijian, YANG Bo, WANG Wei, SUN Zelong, LI Qinjie. A Hierarchical Multi-Agent Collaborative Decision-making Method Based on the Actor-critic Framework [J]. Acta Armamentarii, 2024, 45(10): 3385-3396. |
| [11] | CAO Zijian, SUN Zelong, YAN Guochuang, FU Yanfang, YANG Bo, LI Qinjie, LEI Kailin, GAO Linghang. Simulation of Reinforcement Learning-based UAV Swarm Adversarial Strategy Deduction [J]. Acta Armamentarii, 2023, 44(S2): 126-134. |
| [12] | LI Song, MA Zhuangzhuang, ZHANG Yunlin, SHAO Jinliang. Multi-agent Coverage Path Planning Based on Security Reinforcement Learning [J]. Acta Armamentarii, 2023, 44(S2): 101-113. |
| [13] | YANG Jiaxiu, LI Xinkai, ZHANG Hongli, WANG Hao. Robust Tracking of Quadrotor UAVs Based on Integral Reinforcement Learning [J]. Acta Armamentarii, 2023, 44(9): 2802-2813. |
| [14] | ZHANG Jiandong, WANG Dinghan, YANG Qiming, SHI Guoqing, LU Yi, ZHANG Yaozhong. Multi-Dimensional Decision-Making for UAV Air Combat Based on Hierarchical Reinforcement Learning [J]. Acta Armamentarii, 2023, 44(6): 1547-1563. |
| [15] | LI Chao, WANG Ruixing, HUANG Jianzhong, JIANG Feilong, WEI Xuemei, SUN Yanxin. Autonomous Decision-making and Intelligent Collaboration of UAV Swarms Based on Reinforcement Learning with Sparse Rewards [J]. Acta Armamentarii, 2023, 44(6): 1537-1546. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||