
Responsible Institution: China Association for Science and Technology
Sponsor: China Ordnance Society
ISSN 1000-1093 CN 11-2176/TJ
Sponsor: China Ordnance Society
ISSN 1000-1093 CN 11-2176/TJ
Acta Armamentarii ›› 2025, Vol. 46 ›› Issue (2): 240222-.doi: 10.12382/bgxb.2024.0222
Previous Articles Next Articles
XIAO Liujun, LI Yaxuan, LIU Xinfu*( )
)
Received:2024-03-28
Online:2025-02-28
Contact:
LIU Xinfu
CLC Number:
XIAO Liujun, LI Yaxuan, LIU Xinfu. Adaptive Terminal Guidance for Hypersonic Gliding Vehicles Using Reinforcement Learning[J]. Acta Armamentarii, 2025, 46(2): 240222-.
Add to citation manager EndNote|Ris|BibTeX
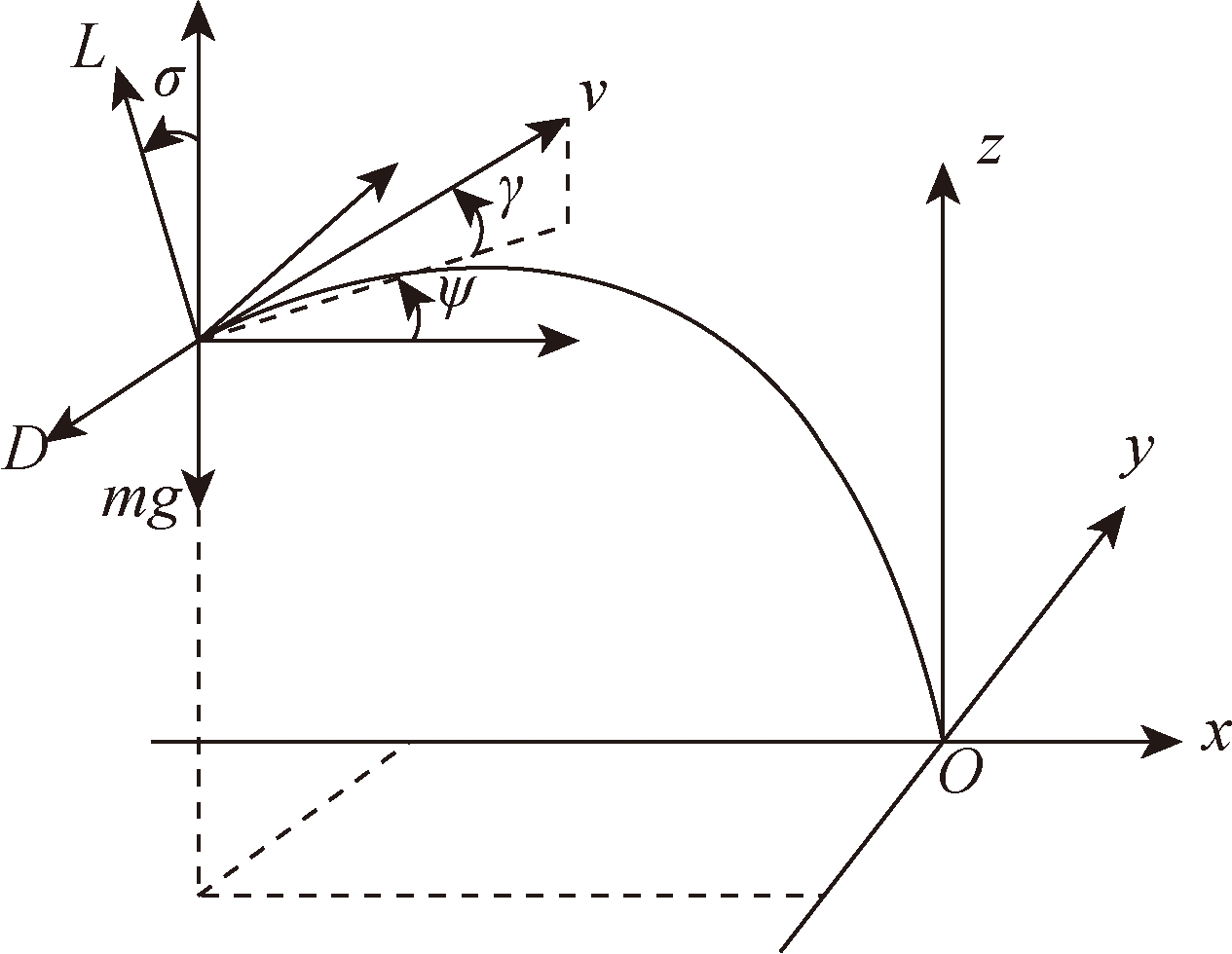
Fig.1 Three-dimensional guidance geometry
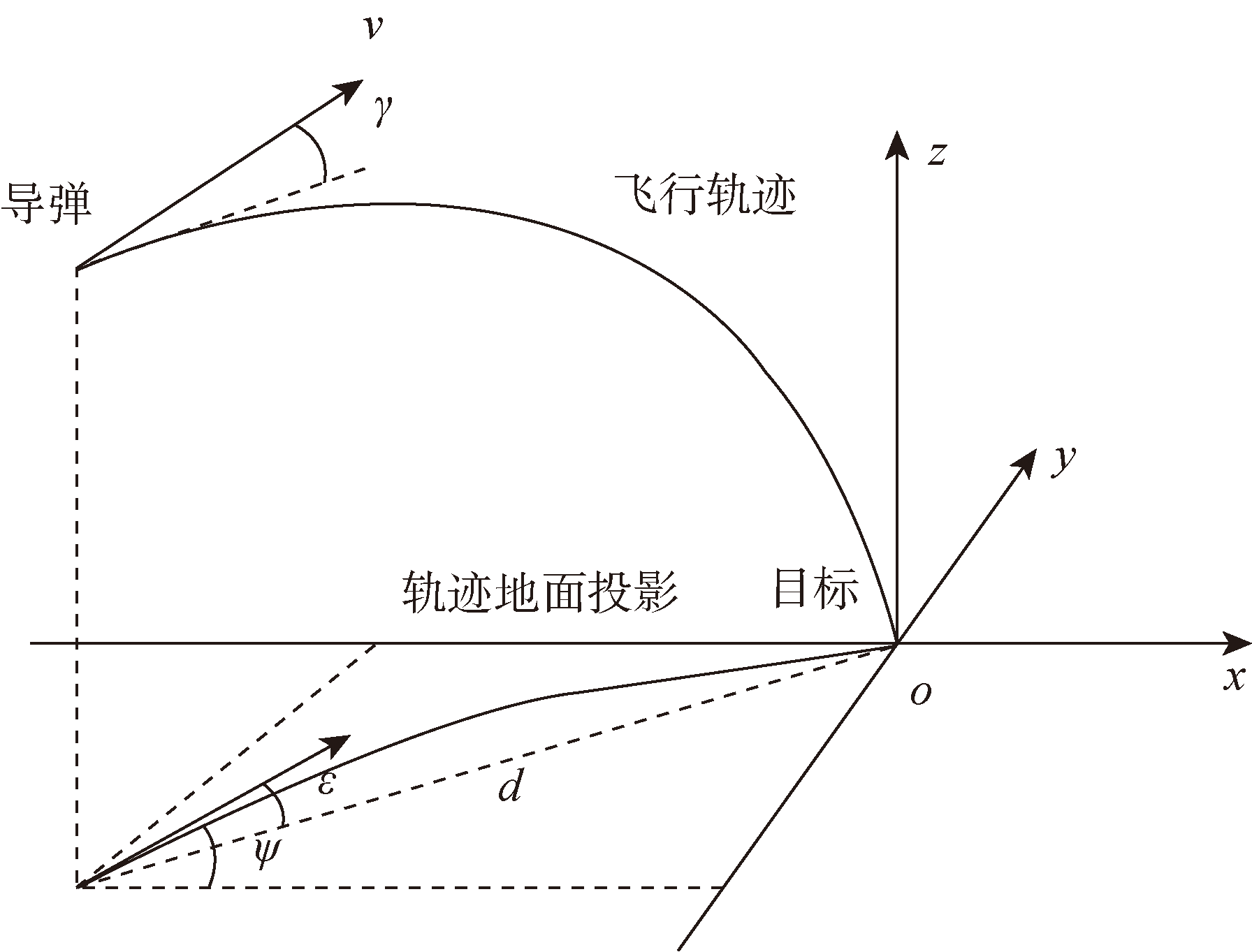
Fig.2 Definition of input parameters for neural networks
| 层数 | 神经元数量 | 激活函数 |
|---|---|---|
| 输入层 | 5 | Tanh |
| 隐藏层1 | 24 | Tanh |
| 隐藏层2 | 18 | Tanh |
| 输出层 | 2 |
Table 1 Network layer size
| 层数 | 神经元数量 | 激活函数 |
|---|---|---|
| 输入层 | 5 | Tanh |
| 隐藏层1 | 24 | Tanh |
| 隐藏层2 | 18 | Tanh |
| 输出层 | 2 |
| 飞行器起始状态参数 | 取值范围 |
|---|---|
| 速度v/(m·s-1) | (1700,1800) |
| 水平面弹目距离d/km | (-40,-30) |
| 弹道倾角γ/(°) | (-7.5,-2.5) |
| 弹道偏角ψ/(°) | (5,15) |
Table 2 Initial state parameters of terminal guidance of aerial vehicle
| 飞行器起始状态参数 | 取值范围 |
|---|---|
| 速度v/(m·s-1) | (1700,1800) |
| 水平面弹目距离d/km | (-40,-30) |
| 弹道倾角γ/(°) | (-7.5,-2.5) |
| 弹道偏角ψ/(°) | (5,15) |
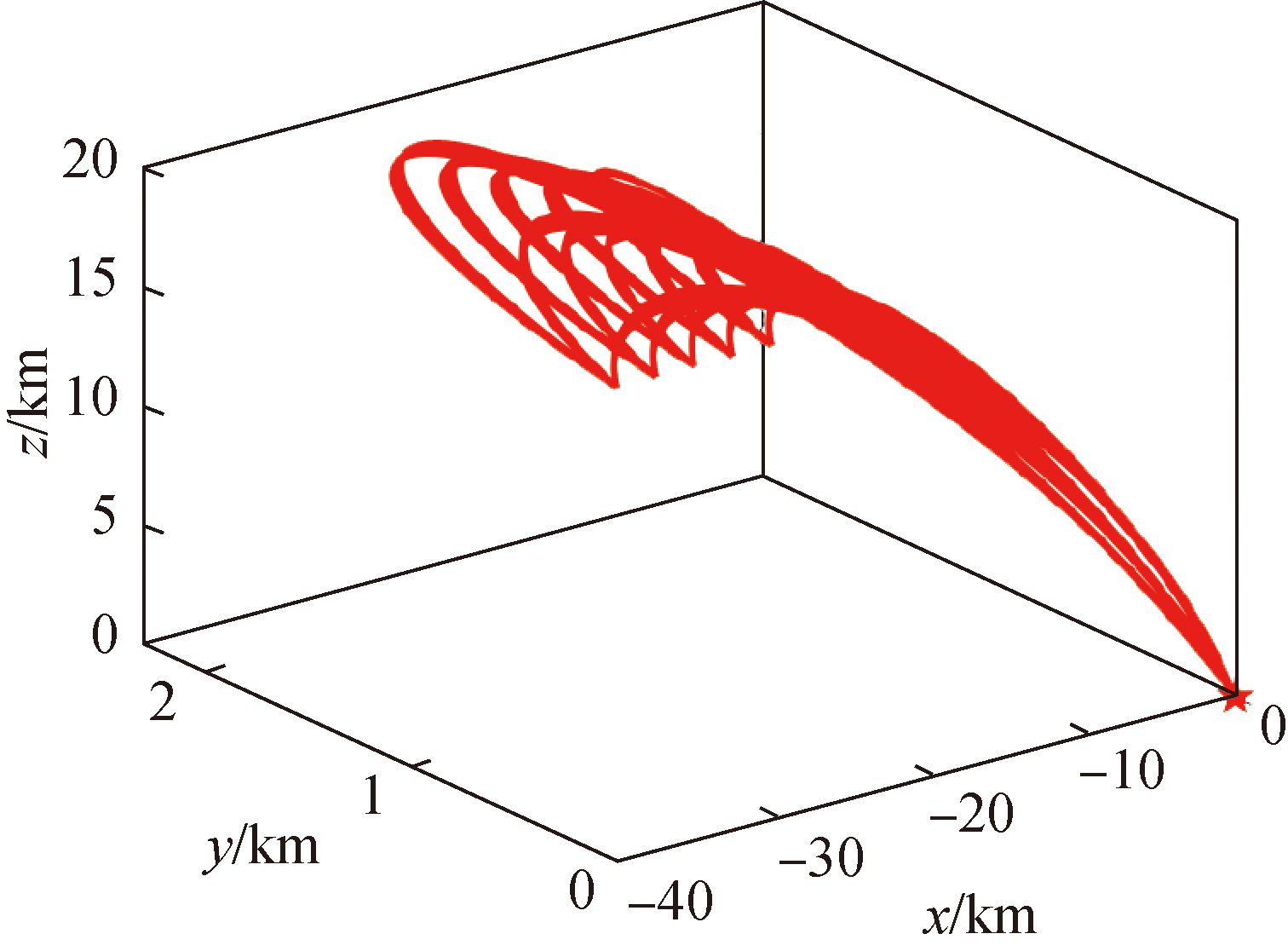
Fig.3 Optimal trajectories generated by sequential convex optimization
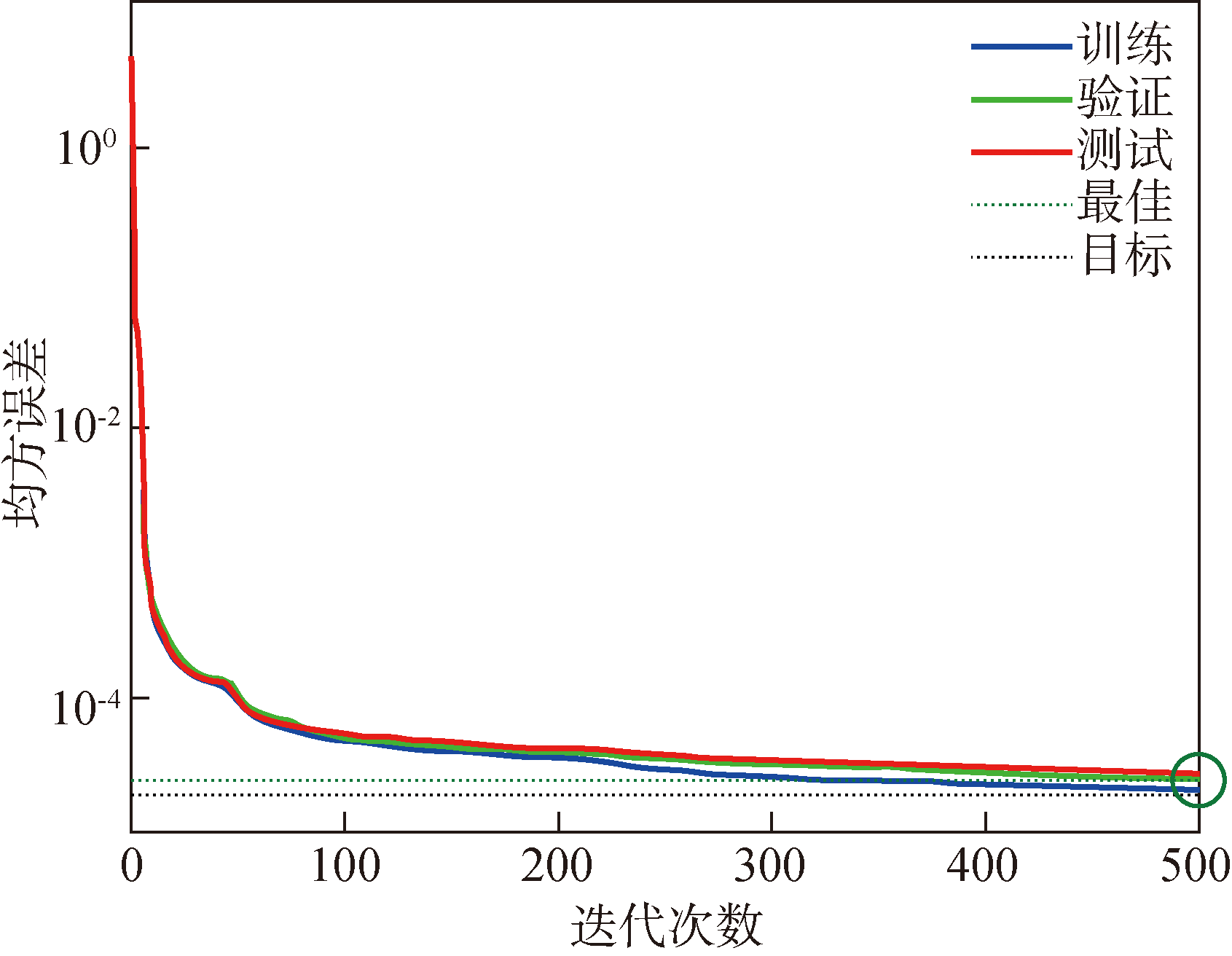
Fig.4 MSE-epoch variation curve
| 参数 | 控制响应延迟/s | 气动参数偏差/% | 状态测量噪声/% |
|---|---|---|---|
| 工况1 | 0.1 | 0 | 0 |
| 工况2 | 0 | 10 | 0 |
| 工况3 | 0.1s | 10 | 1 |
Table 3 Description of operating parameters
| 参数 | 控制响应延迟/s | 气动参数偏差/% | 状态测量噪声/% |
|---|---|---|---|
| 工况1 | 0.1 | 0 | 0 |
| 工况2 | 0 | 10 | 0 |
| 工况3 | 0.1s | 10 | 1 |
| 学习率 | 优化器 | 折扣因子 | 取样数 | 经验池 |
|---|---|---|---|---|
| 1×10-4 | Adam | 0.99 | 128 | 1×106 |
Table 4 Parameters of DDPG algorithm
| 学习率 | 优化器 | 折扣因子 | 取样数 | 经验池 |
|---|---|---|---|---|
| 1×10-4 | Adam | 0.99 | 128 | 1×106 |
| 方法 | 工况1 | 工况2 | 工况3 |
|---|---|---|---|
| 开环指令制导 | 154.09 | 669.11 | 869.11 |
| 监督学习制导 | 35.86 | 106.27 | 139.02 |
| 强化学习自适应制导 | 5.62 | 12.78 | 15.45 |
Table 5 Miss distances of different methods m
| 方法 | 工况1 | 工况2 | 工况3 |
|---|---|---|---|
| 开环指令制导 | 154.09 | 669.11 | 869.11 |
| 监督学习制导 | 35.86 | 106.27 | 139.02 |
| 强化学习自适应制导 | 5.62 | 12.78 | 15.45 |
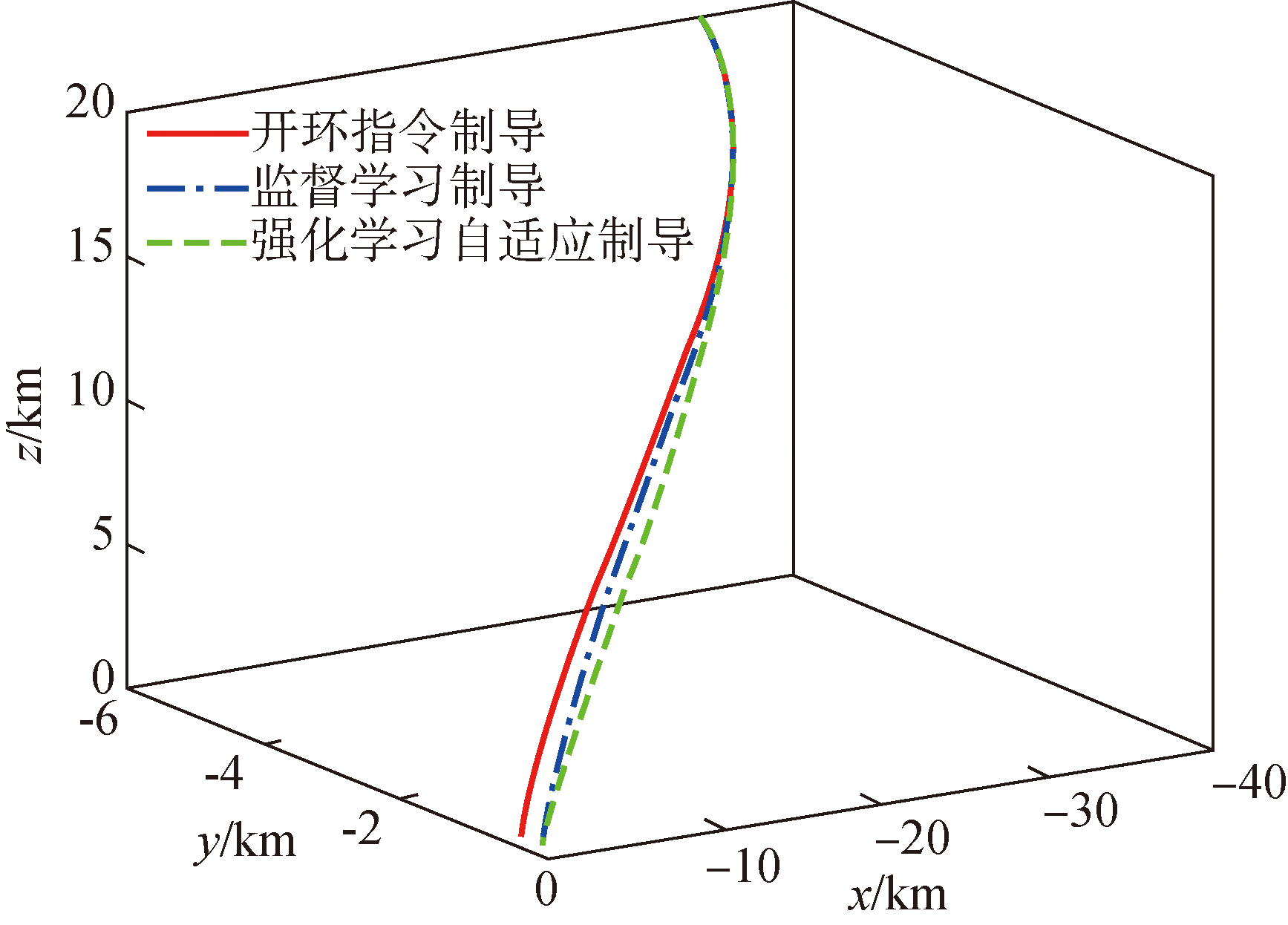
Fig.5 Comparison of trajectories in Case 3
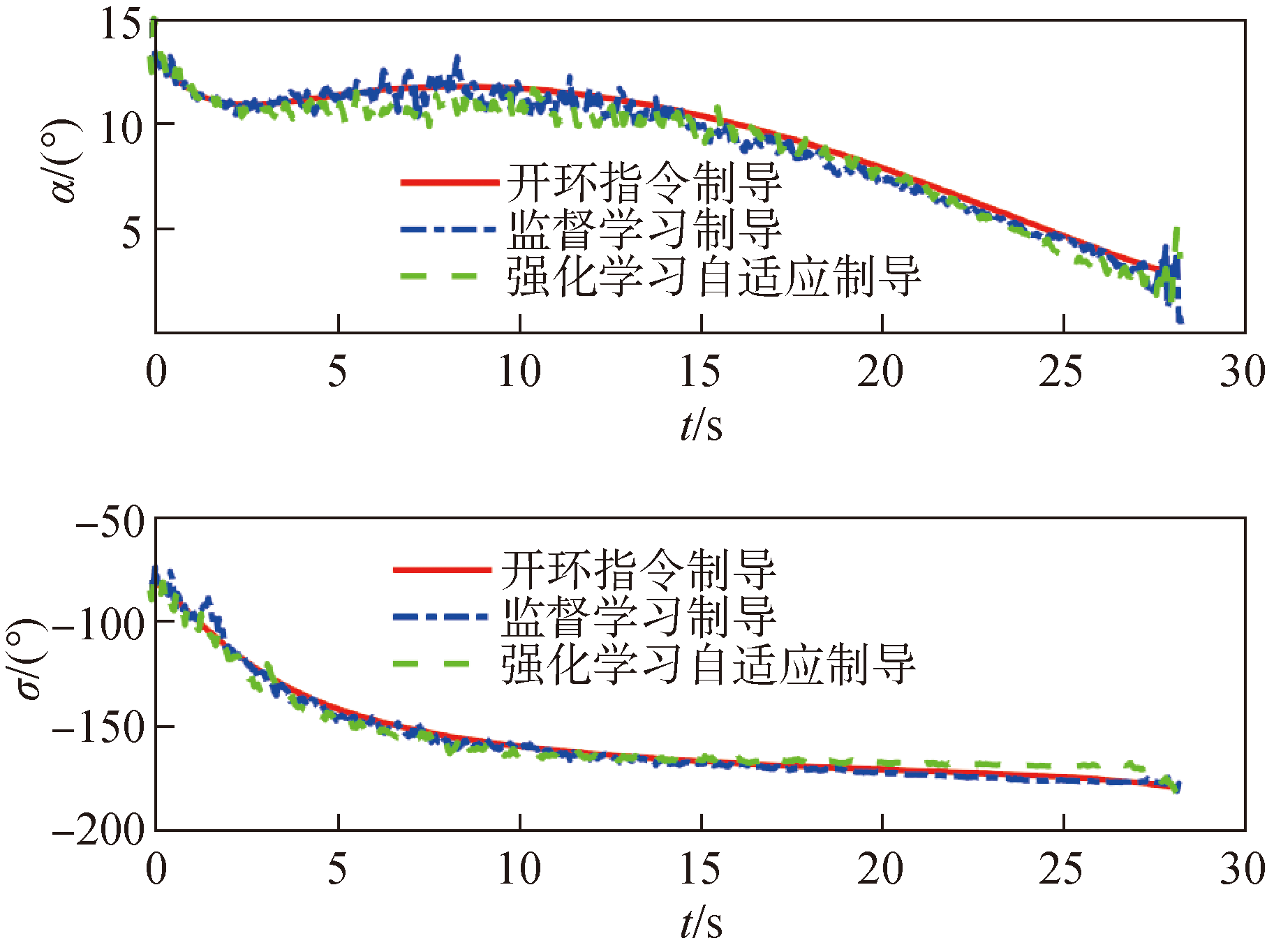
Fig.6 Comparison of angle of attack and bank angle in Case 3
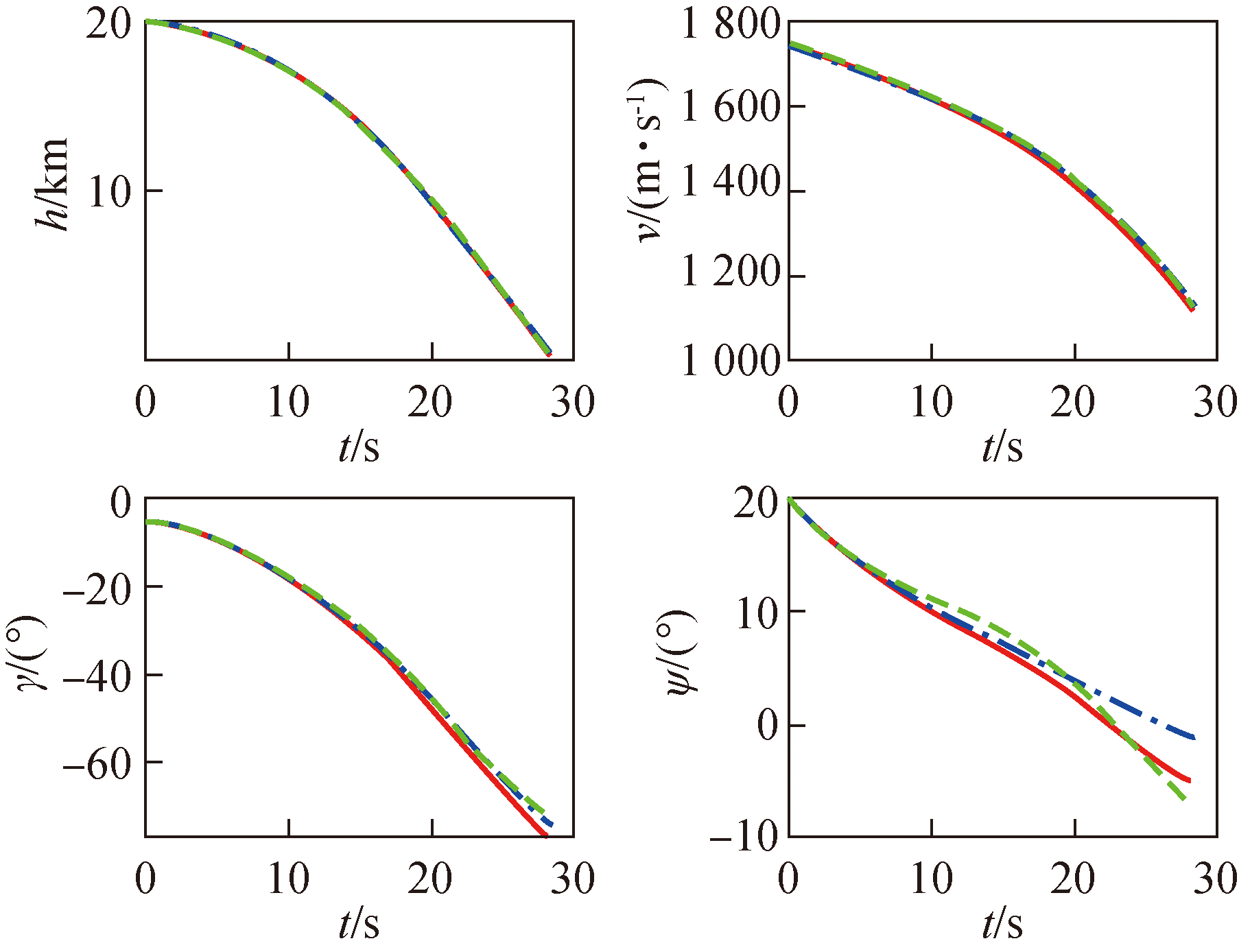
Fig.7 Comparison of altitude, velocity, flight path angle and flight heading angle in Case 3
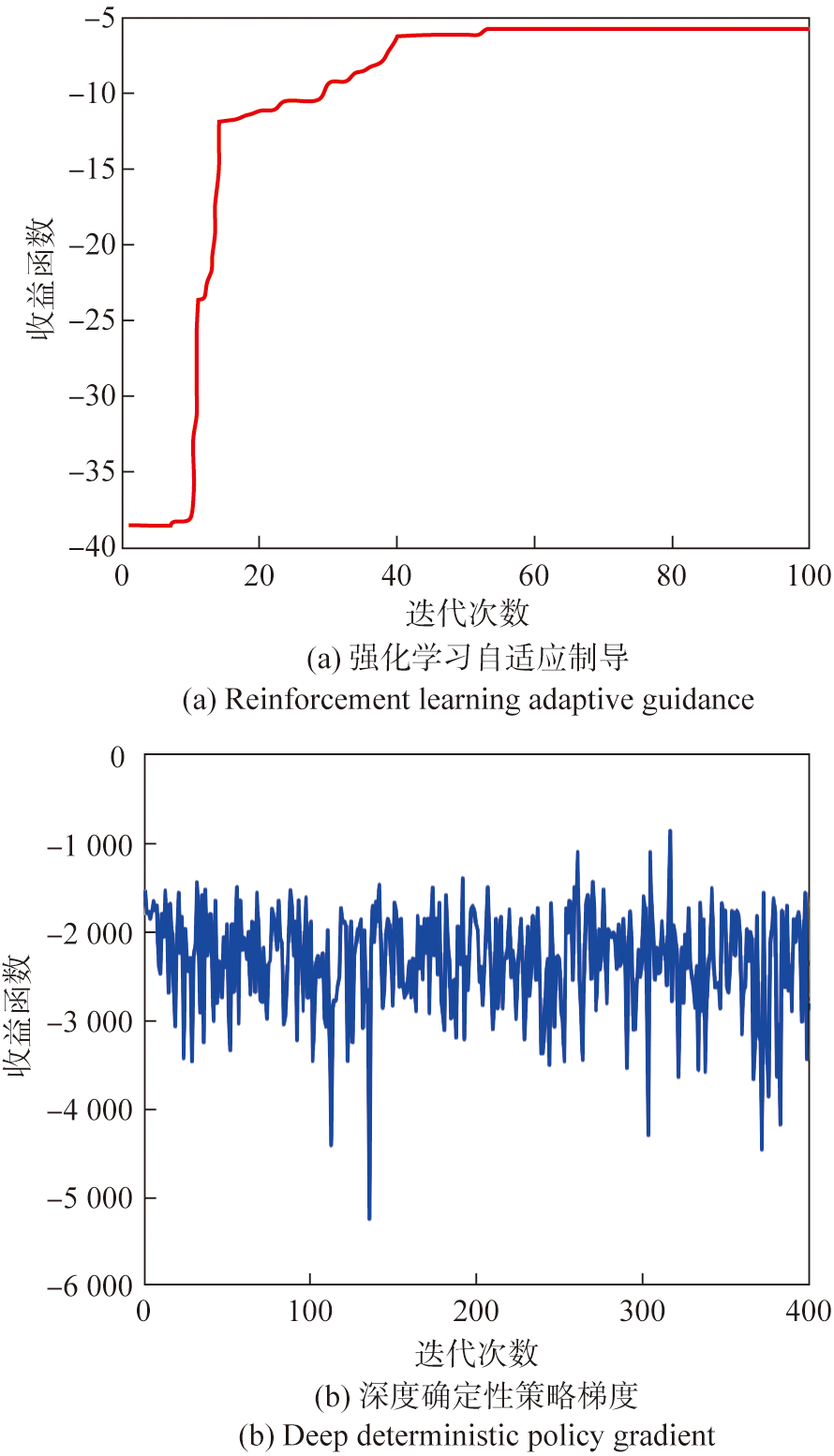
Fig.8 Comparison of reward functions
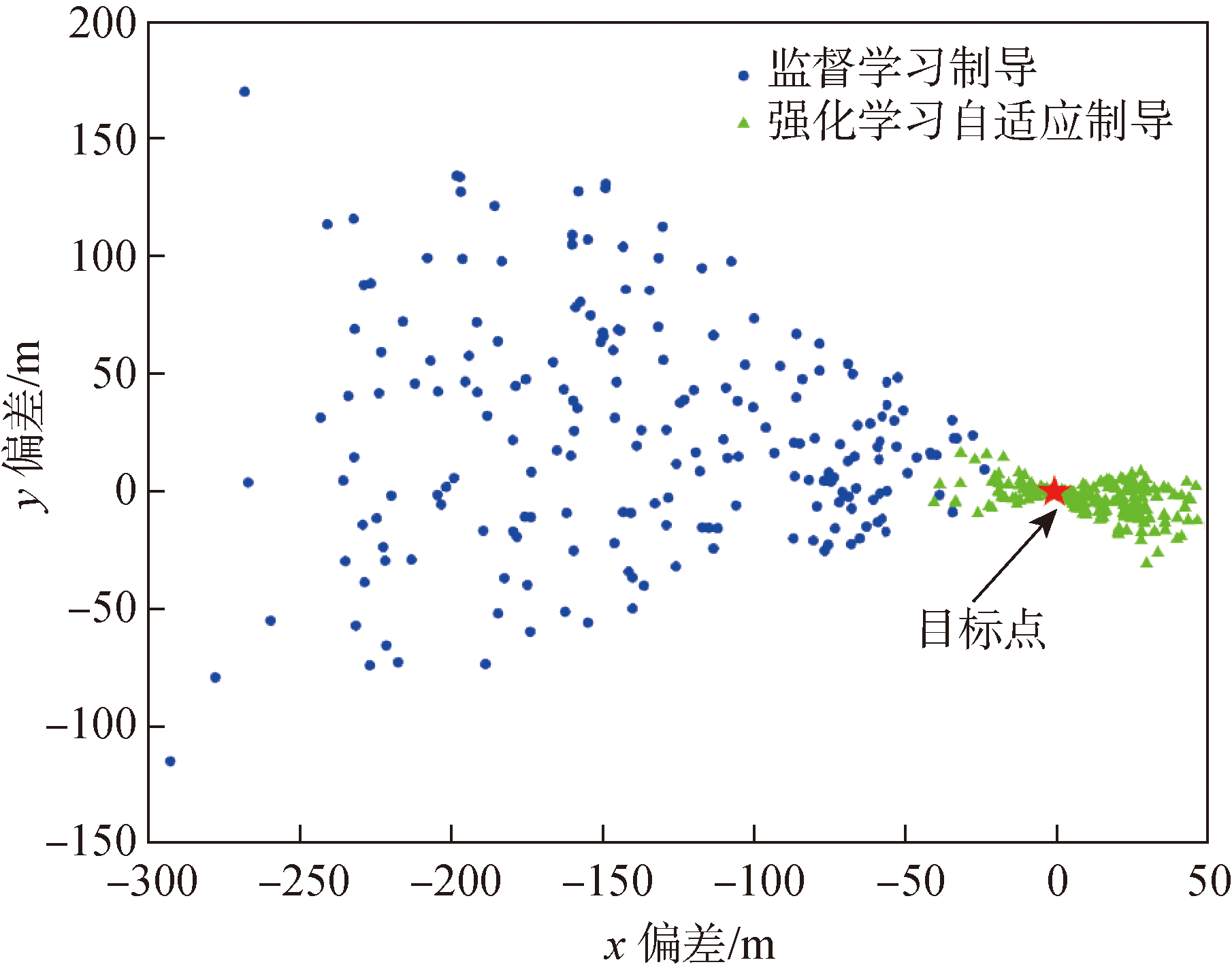
Fig.9 Impact point distributions of two guidance methods without considering the deviation of aerodynamic parameters
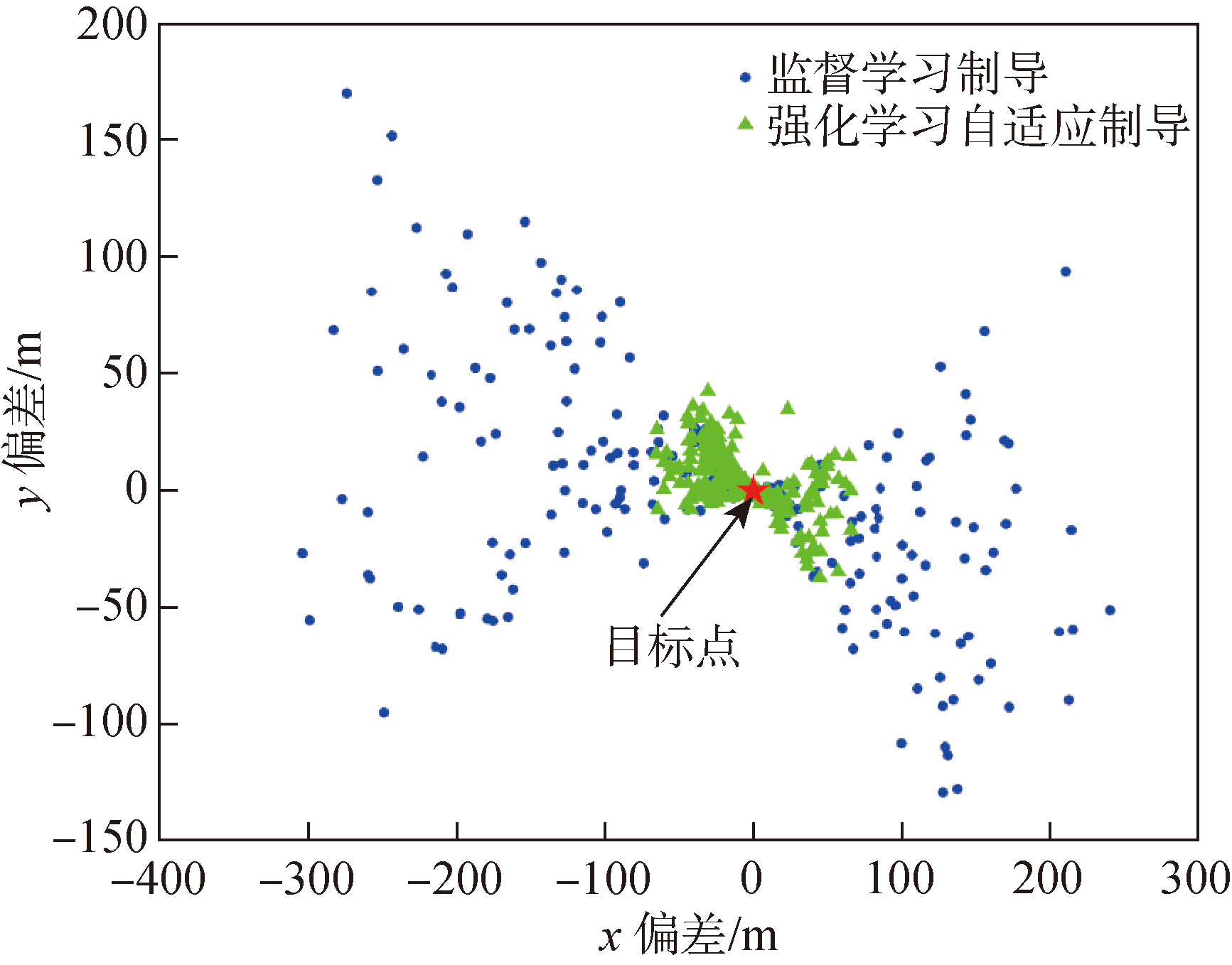
Fig.10 Impact point distributions of two guidance methods considering the deviation of aerodynamic parameters
| [1] |
董金鲁, 马悦萌, 周荻, 等. 临近空间高超声速飞行器的直接力与襟翼复合滑模控制[J]. 兵工学报, 2023, 44(2):496-506.
doi: 10.12382/bgxb.2021.0690 |
|
doi: 10.12382/bgxb.2021.0690 |
|
| [2] |
|
| [3] |
刘畅, 王江, 范世鹏, 等. 基于BP神经网络的自适应偏置比例导引[J]. 兵工学报, 2022, 43(11):2798-2809.
|
|
doi: 10.12382/bgxb.2021.0594 |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
李庆波, 李芳, 董瑞星, 等. 利用强化学习开展比例导引律的导航比设计[J]. 兵工学报, 2022, 43(12):3040-3047.
|
|
doi: 10.12382/bgxb.2021.0631 |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [1] | SUN Hao, LI Haiqing, LIANG Yan, MA Chaoxiong, WU Han. Dynamic Penetration Decision of Loitering Munition Group Based on Knowledge-assisted Reinforcement Learning [J]. Acta Armamentarii, 2024, 45(9): 3161-3176. |
| [2] | HU Yanyang, HE Fan, BAI Chengchao. Cooperative Obstacle Avoidance Decision Method for the Terminal Guidance Phase of Hypersonic Vehicles [J]. Acta Armamentarii, 2024, 45(9): 3147-3160. |
| [3] | CHEN Wenjie, CUI Xiaohong, WANG Binrui. Safety Optimal Tracking Control Algorithm and Robot Arm Simulation [J]. Acta Armamentarii, 2024, 45(8): 2688-2697. |
| [4] | WANG Xiaolong, CHEN Yang, HU Mian, LI Xudong. Robot Path Planning for Persistent Monitoring Based on Improved Deep Q Networks [J]. Acta Armamentarii, 2024, 45(6): 1813-1823. |
| [5] | LOU Shuhan, WANG Chongchong, GONG Wei, DENG Liyuan, LI Li. Collaborative Regional Information Collection Strategy Based on MLAT-DRL Algorithm [J]. Acta Armamentarii, 2024, 45(12): 4423-4434. |
| [6] | DONG Mingze, WEN Zhuanglei, CHEN Xiai, YANG Jiongkun, ZENG Tao. Research on Robot Navigation Method Integrating Safe Convex Space and Deep Reinforcement Learning [J]. Acta Armamentarii, 2024, 45(12): 4372-4382. |
| [7] | LI Jiashen, WANG Xiaofang, LIN Hai. Intelligent Penetration Policy for Hypersonic Cruise Missiles Based on Virtual Targets [J]. Acta Armamentarii, 2024, 45(11): 3856-3867. |
| [8] | FU Yanfang, LEI Kailin, WEI Jianing, CAO Zijian, YANG Bo, WANG Wei, SUN Zelong, LI Qinjie. A Hierarchical Multi-Agent Collaborative Decision-making Method Based on the Actor-critic Framework [J]. Acta Armamentarii, 2024, 45(10): 3385-3396. |
| [9] | CAO Zijian, SUN Zelong, YAN Guochuang, FU Yanfang, YANG Bo, LI Qinjie, LEI Kailin, GAO Linghang. Simulation of Reinforcement Learning-based UAV Swarm Adversarial Strategy Deduction [J]. Acta Armamentarii, 2023, 44(S2): 126-134. |
| [10] | LI Song, MA Zhuangzhuang, ZHANG Yunlin, SHAO Jinliang. Multi-agent Coverage Path Planning Based on Security Reinforcement Learning [J]. Acta Armamentarii, 2023, 44(S2): 101-113. |
| [11] | YANG Jiaxiu, LI Xinkai, ZHANG Hongli, WANG Hao. Robust Tracking of Quadrotor UAVs Based on Integral Reinforcement Learning [J]. Acta Armamentarii, 2023, 44(9): 2802-2813. |
| [12] | ZHANG Jiandong, WANG Dinghan, YANG Qiming, SHI Guoqing, LU Yi, ZHANG Yaozhong. Multi-Dimensional Decision-Making for UAV Air Combat Based on Hierarchical Reinforcement Learning [J]. Acta Armamentarii, 2023, 44(6): 1547-1563. |
| [13] | LI Chao, WANG Ruixing, HUANG Jianzhong, JIANG Feilong, WEI Xuemei, SUN Yanxin. Autonomous Decision-making and Intelligent Collaboration of UAV Swarms Based on Reinforcement Learning with Sparse Rewards [J]. Acta Armamentarii, 2023, 44(6): 1537-1546. |
| [14] | ZHENG Zexin, LI Wei, ZOU Kun, LI Yanfu. Anti-jamming Waveform Design of Ground-based Air Surveillance Radar Based on Reinforcement Learning [J]. Acta Armamentarii, 2023, 44(5): 1422-1430. |
| [15] | LI Jiajian, SHI Yanjun, YANG Yu, LI Bo, ZHAO Xijun. Multi-agent Reinforcement Learning-based Offloading Decision for UAV Cluster Combat Tasks [J]. Acta Armamentarii, 2023, 44(11): 3295-3309. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||