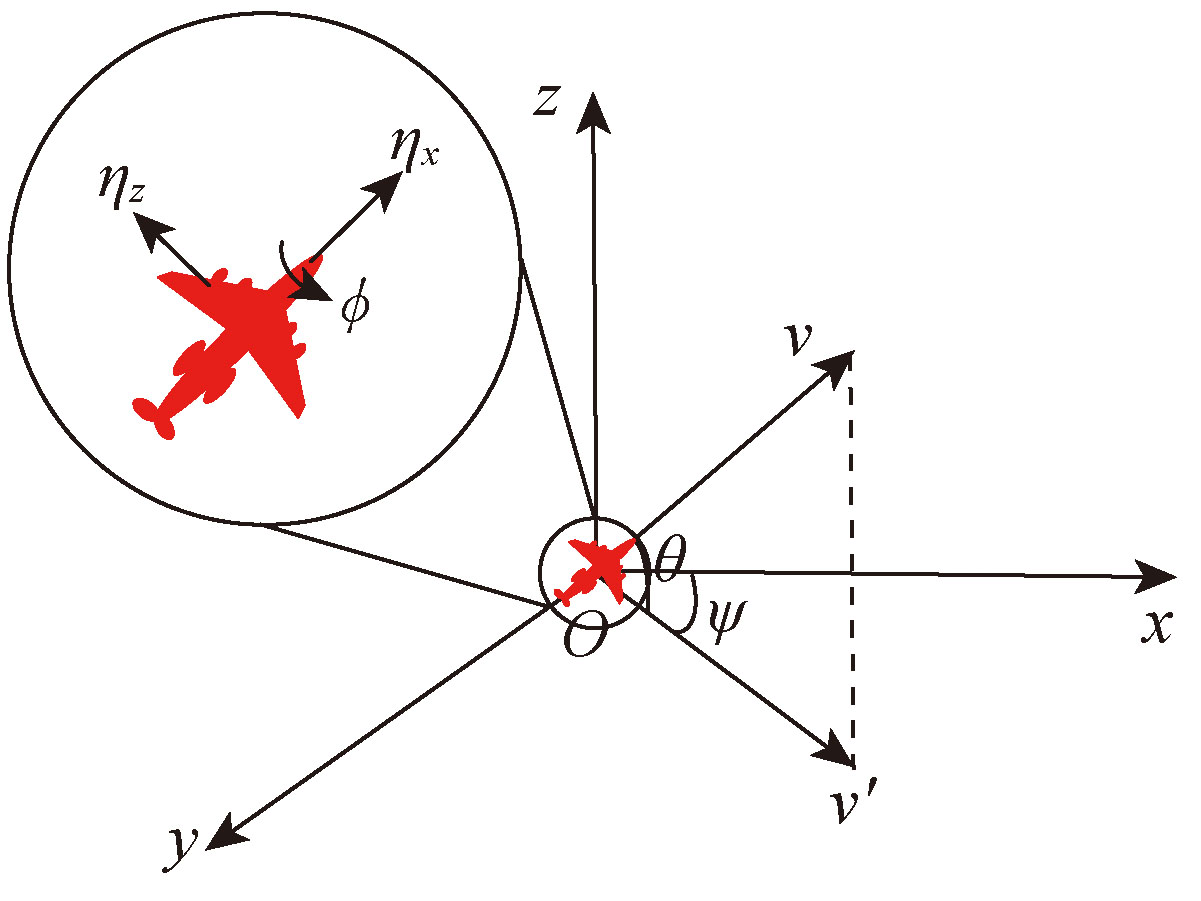
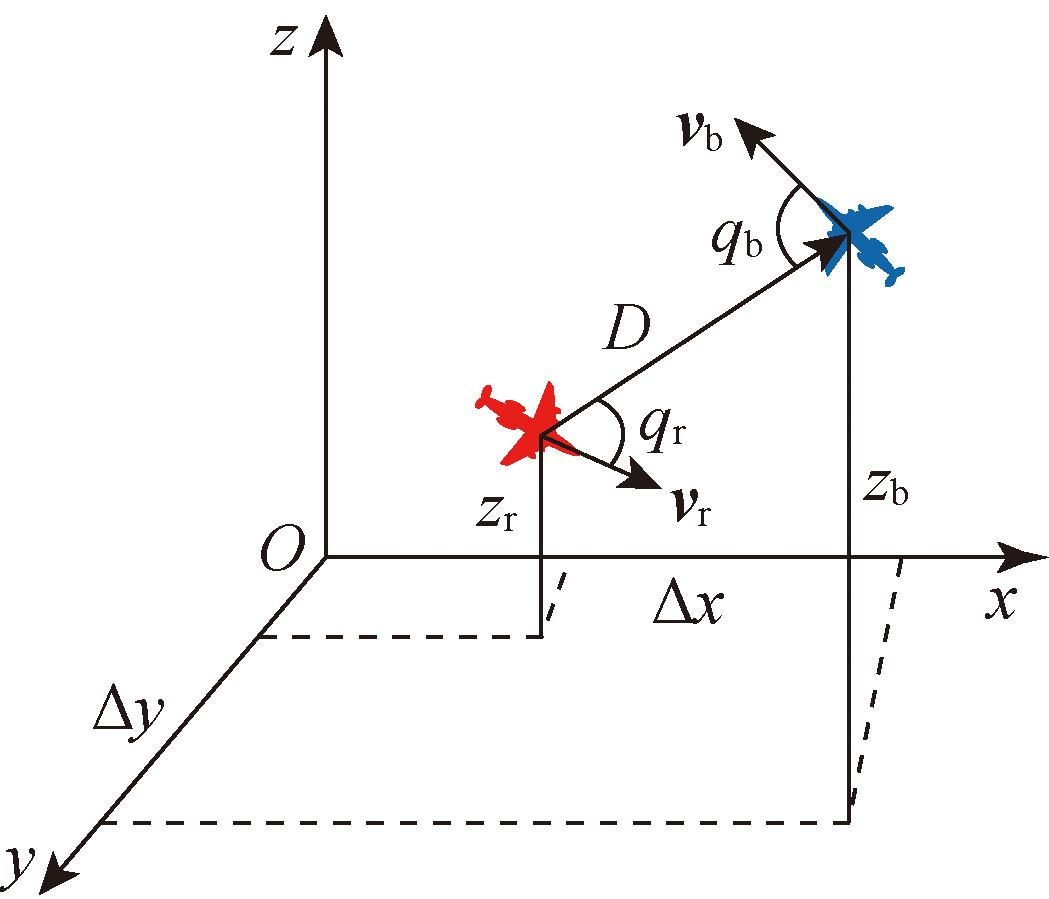
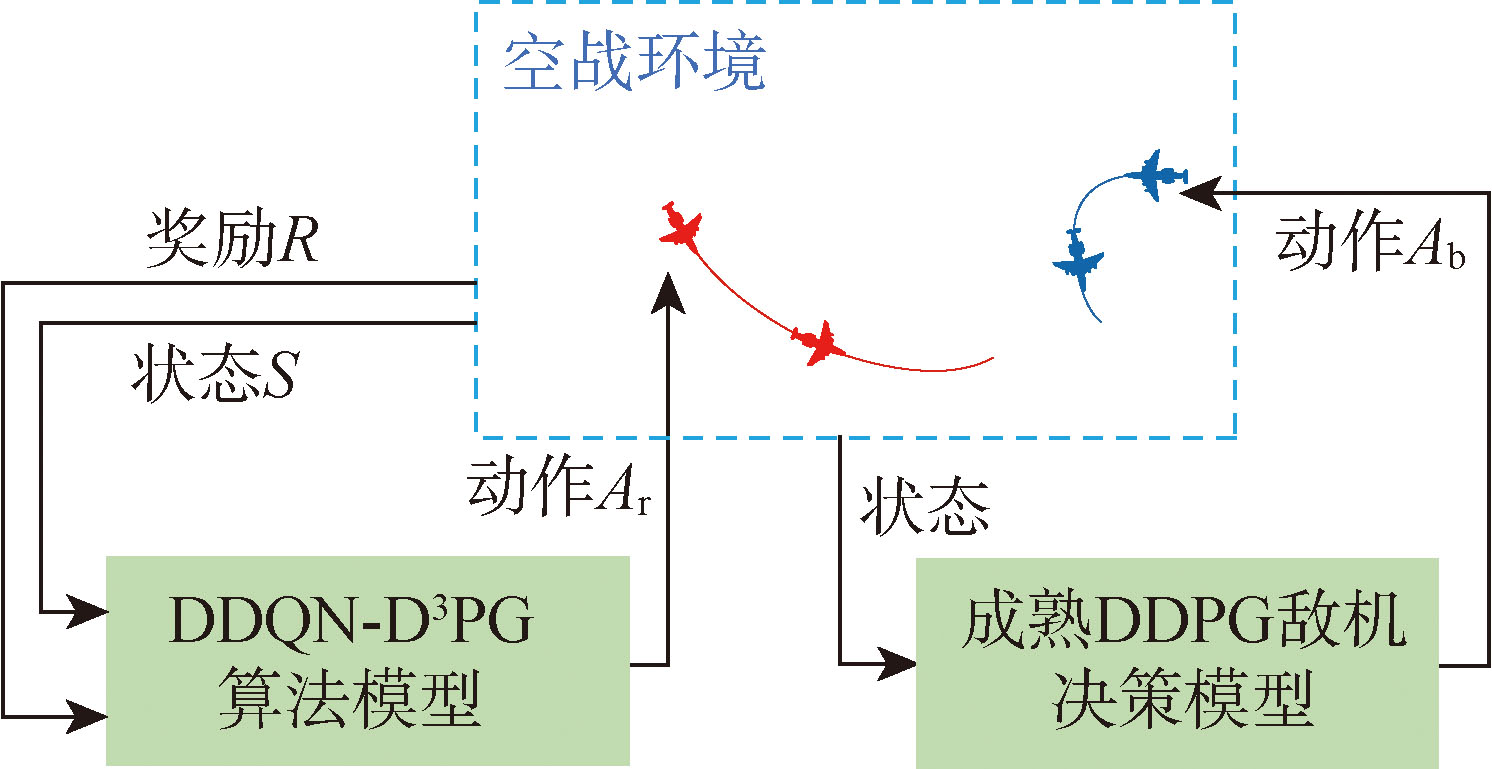
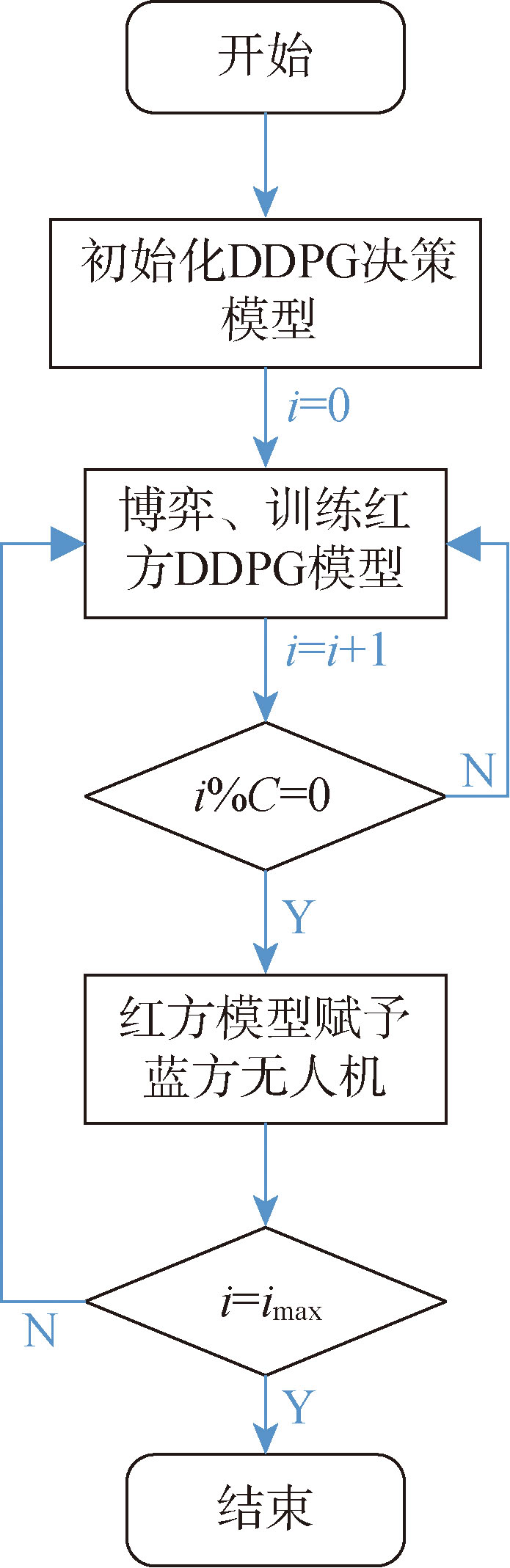
| [1] |
於志文, 孙卓, 程岳, 等. 智能无人机集群协同感知计算研究综述[J]. 航空学报, 2024, 45(20):630912.
|
|
YU Z W, SUN Z, CHENG Y, et al. A review of intelligent UAV swarm collaborative perception and computation[J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(20):630912. (in Chinese)
|
| [2] |
周新民, 吴佳晖, 贾圣德, 等. 无人机空战决策技术研究进展[J]. 国防科技, 2021, 42(3):33-41.
|
|
ZHOU X M, WU J H, JIA S D, et al. Progress in research on combat decision-making technology in UAVs[J]. National Defense Technology, 2021, 42(3):33-41. (in Chinese)
|
| [3] |
董一群, 艾剑良. 自主空战技术中的机动决策:进展与展望[J]. 航空学报, 2020, 41(增刊2):724264.
|
|
DONG Y Q, AI J L. Decision making in autonomous air combat:review and prospects[J]. Acta Aeronautica et Astronautica Sinica, 2020, 41(S2):724264. (in Chinese)
|
| [4] |
GARCIA E, CASBEER D W, PACHTER M. Active target defense differential game with a fast defender[C]// Proceedings of 2015 American Control Conference. Chicago,IL,US: IEEE, 2015:3752-3757.
|
| [5] |
ALKAHER D, MOSHAIOV A. Game-based safe aircraft navigation in the presence of energy-bleeding coasting missile[J]. Journal of Guidance,Control,and Dynamics, 2016, 39(7):1539-1550.
|
| [6] |
车竞, 钱炜祺, 和争春. 基于矩阵博弈的两机攻防对抗空战仿真[J]. 飞行力学, 2015, 33(2):173-177.
|
|
CHE J, QIAN W Q, HE Z C. Attack-defence confrontation simulation of air combat based on game-matrix approach[J]. Flight Dynamics, 2015, 33(2):173-177. (in Chinese)
|
| [7] |
ZHANG T, LI C C, MA D Y, et al. An optimal task management and control scheme for military operations with dynamic game strategy[J]. Aerospace Science and Technology, 2021, 115:106815.
|
| [8] |
BOTVINICK M, WANG J X, DABNEY W, et al. Deep reinforcement learning and its neuroscientific impli-cations[J]. Neuron, 2020, 107(4):603-616.
|
| [9] |
TENG T H, TAN A H, TAN Y S, et al. Self-organizing neural networks for learning air combat maneuvers[C]// Proceedings of the 2012 International Joint Conference on Neural Networks. Brisbane,QLD,Australia: IEEE, 2012:1-8.
|
| [10] |
吴傲, 杨任农, 梁晓龙, 等. 基于模糊推理的无人战斗机视距空战机动决策[J]. 南京航空航天大学学报, 2021, 53(6):898-908.
|
|
WU A, YANG R N, LIANG X L, et al. Maneuver decision on visual range air combats of unmanned combat aerial vehicles based on fuzzy inference[J]. Journal of Nanjing University of Aeronautics & Astronautics, 2021, 53(6):898-908. (in Chinese).
|
| [11] |
YANG Q M, ZHU Y, ZHANG J D, et al. UAV air combat autonomous maneuver decision based on DDPG algorithm[C]// Proceedings of the 2019 IEEE 15th International Conference on Control and Automation. Edinburgh,UK: IEEE, 2019:37-42.
|
| [12] |
何子琦, 李博宸, 王成罡, 等. 针对区域防御的多无人机序列捕捉策略[J]. 兵工学报, 2025, 46(4):240343.
doi: 10.12382/bgxb.2024.0343
|
|
HE Z Q, LI B C, WANG C G, Multi UAV sequential capture strategy for area defense[J]. Acta Armamentarii, 2025, 46(4):240343. (in Chinese)
|
| [13] |
张耀中, 吴卓然, 张建东, 等. 基于ME-DDPG算法的无人机多对一追逃博弈[J/OL]. 系统工程与电子技术, 2024(2024-10-10)[2024-12-24]. http://kns.cnki.net/kcms/detail/11.2422.tn.20241009.1739.012.html.
|
|
ZHANG Y Z, WU Z R, ZHANG J D, et al. UAV many-to-one pursuit-evasion game based on ME-DDPG algorithm[J/OL]. Systems Engineering and Electronics, 2024(2024-10-10) [2024-12-24]. http://kns.cnki.net/kcms/detail/11.2422.tn.20241009.1739.012.html. (in Chinese)
|
| [14] |
ZHANG L J, PENG J B, YI W G, et al. A state-decomposition DDPG algorithm for UAV autonomous navigation in 3-D complex environments[J]. IEEE Internet of Things Journal, 2024, 11(6):10778-10790.
|
| [15] |
LI Y F, LÜ Y X, SHI J P, et al. Autonomous maneuver decision of air combat based on simulated operation command and FRV-DDPG algorithm[J]. Aerospace, 2022, 9:658-676.
|
| [16] |
BAI S X, SONG S M, LIANG S Y, et al. UAV maneuvering decision-making algorithm based on twin delayed deep deterministic policy gradient algorithm[J]. Journal of Artificial Intelligence and Technology, 2022, 2:16-22.
|
| [17] |
钟皓俊, 王振雷. 基于双经验回放池TD3算法的PID参数优化[J/OL]. 控制理论与应用, 2024(2024-10-25)[2024-12-24].
|
|
ZHONG H J, WANG Z L. PID parameter optimization based on TD3 algorithm of double replay buffer[J/OL]. Control Theory & Applications, 2024(2024-10-25) [2024-12-24]. (in Chinese)
|
| [18] |
周攀, 黄江涛, 章胜, 等. 基于深度强化学习的智能空战决策与仿真[J]. 航空学报, 2023, 44(4):126731.
doi: 10.7527/S1000-6893.2022.26731
|
|
ZHOU P, HUANG J T, ZHANG S, et al.、 Intelligent air combat decision making and simulation based on deep reinforcement learning[J]. Acta Aeronautica et Astronautica Sinica, 2023, 44(4):126731. (in Chinese)
doi: 10.7527/S1000-6893.2022.26731
|
| [19] |
李永丰, 吕永玺, 史静平, 等. 深度确定性策略梯度和预测相结合的无人机空战决策研究[J]. 西北工业大学学报, 2023, 41(1):56-64.
|
|
LI Y F, LÜ Y X, SHI J P, et al. UAV's air combat decision-making based on deep deterministic policy gradient and prediction[J]. Journal of Northwestern Polytechnical University, 2023, 41(1):56-64. (in Chinese)
|
| [20] |
李曾琳, 李波, 白双霞, 等. 基于AM-SAC的无人机自主-空战决策[J]. 兵工学报, 2023, 44(9):2849-2858.
doi: 10.12382/bgxb.2022.0669
|
|
LI Z L, LI B, BAI S X, et al. UAV autonomous air combat decision-making based on AM-SAC[J]. Acta Armamentarii, 2023, 44(9):2849-2858. (in Chinese)
doi: 10.12382/bgxb.2022.0669
|
| [21] |
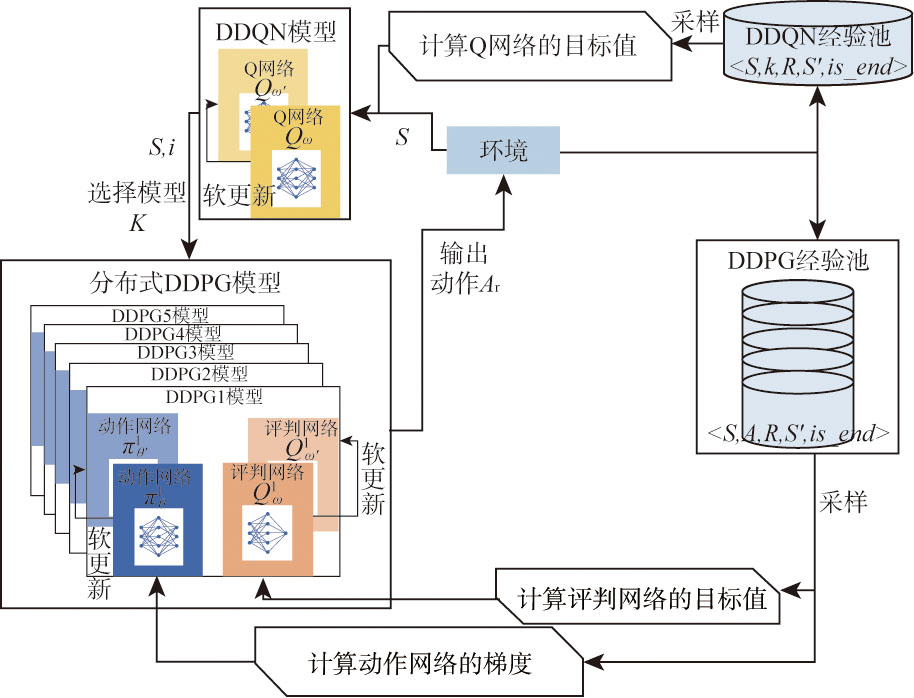
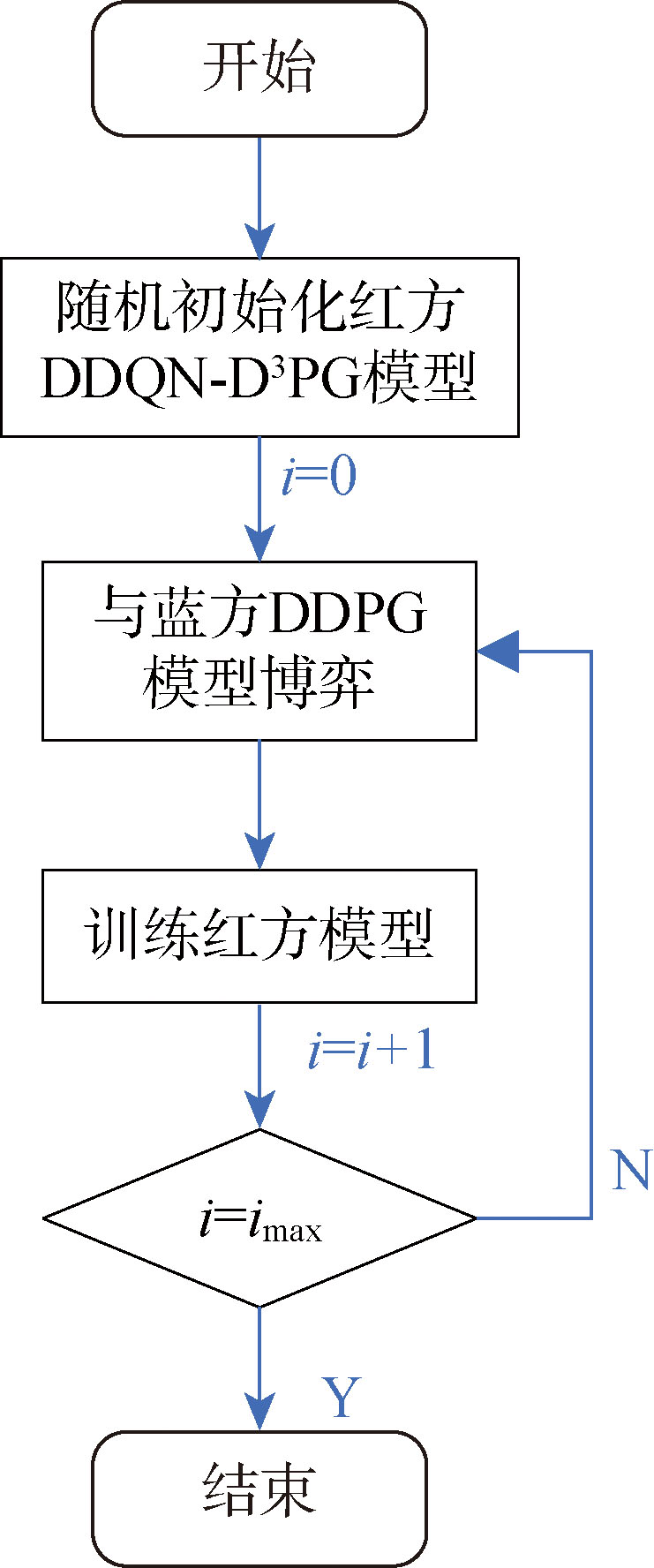
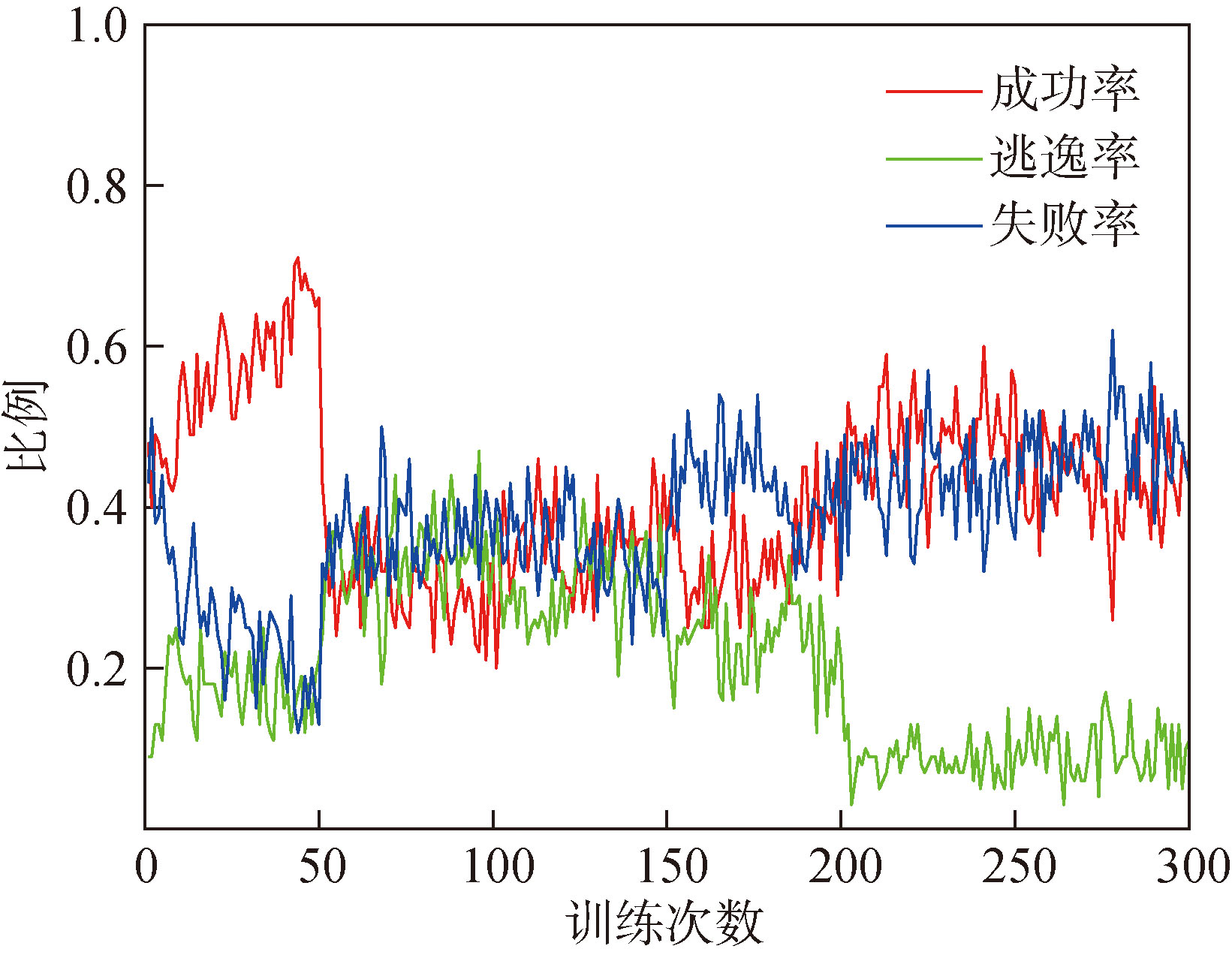
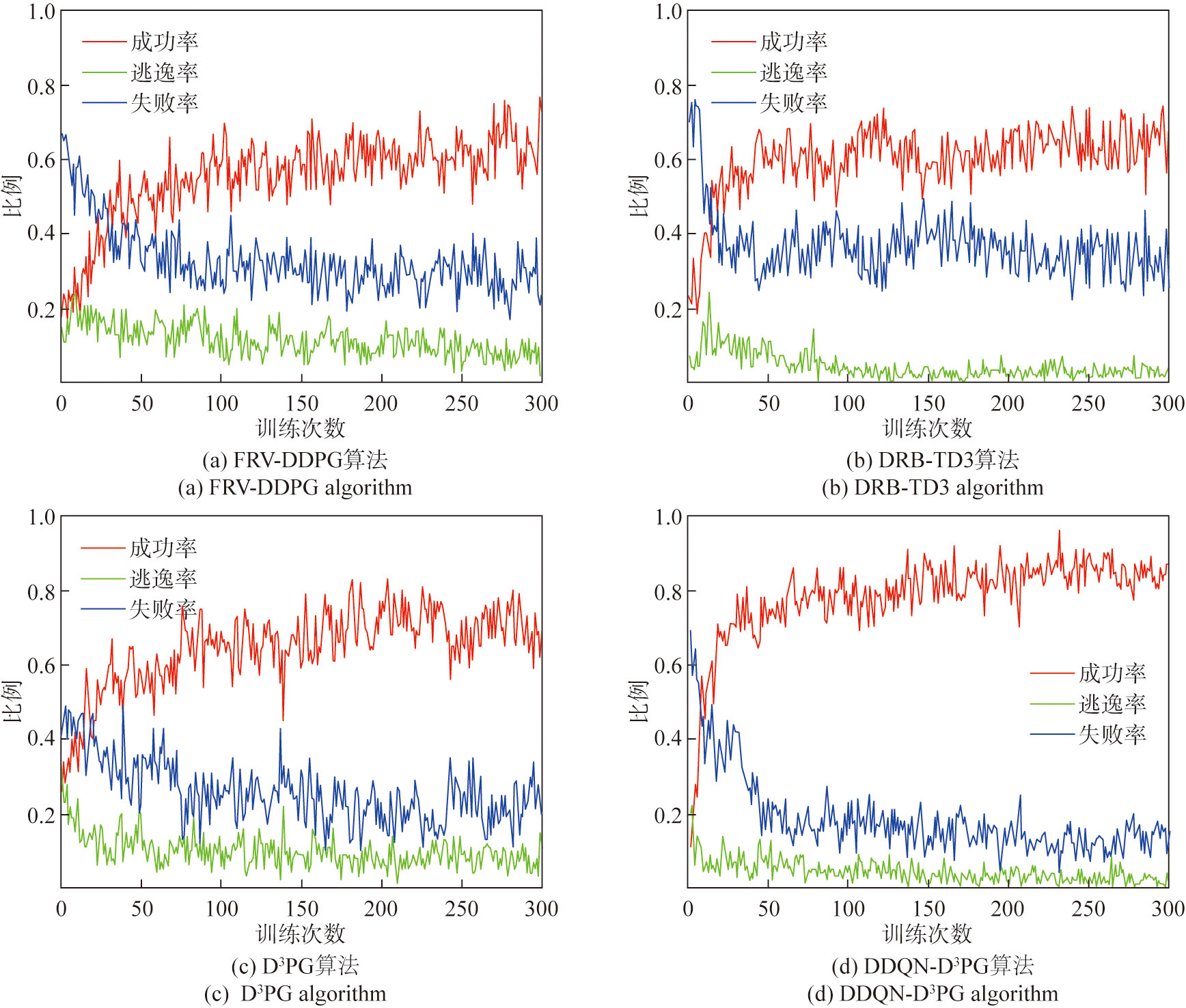
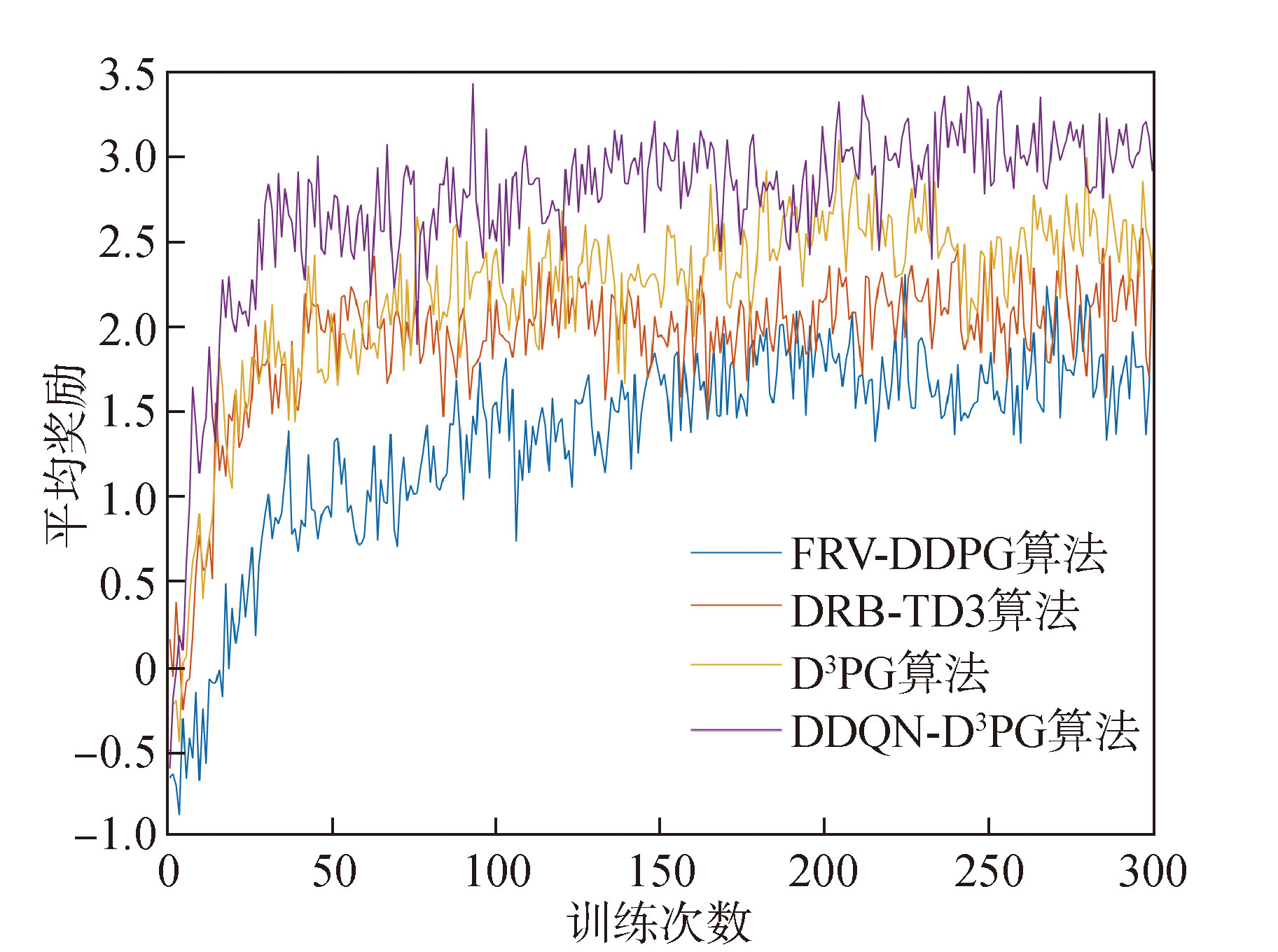
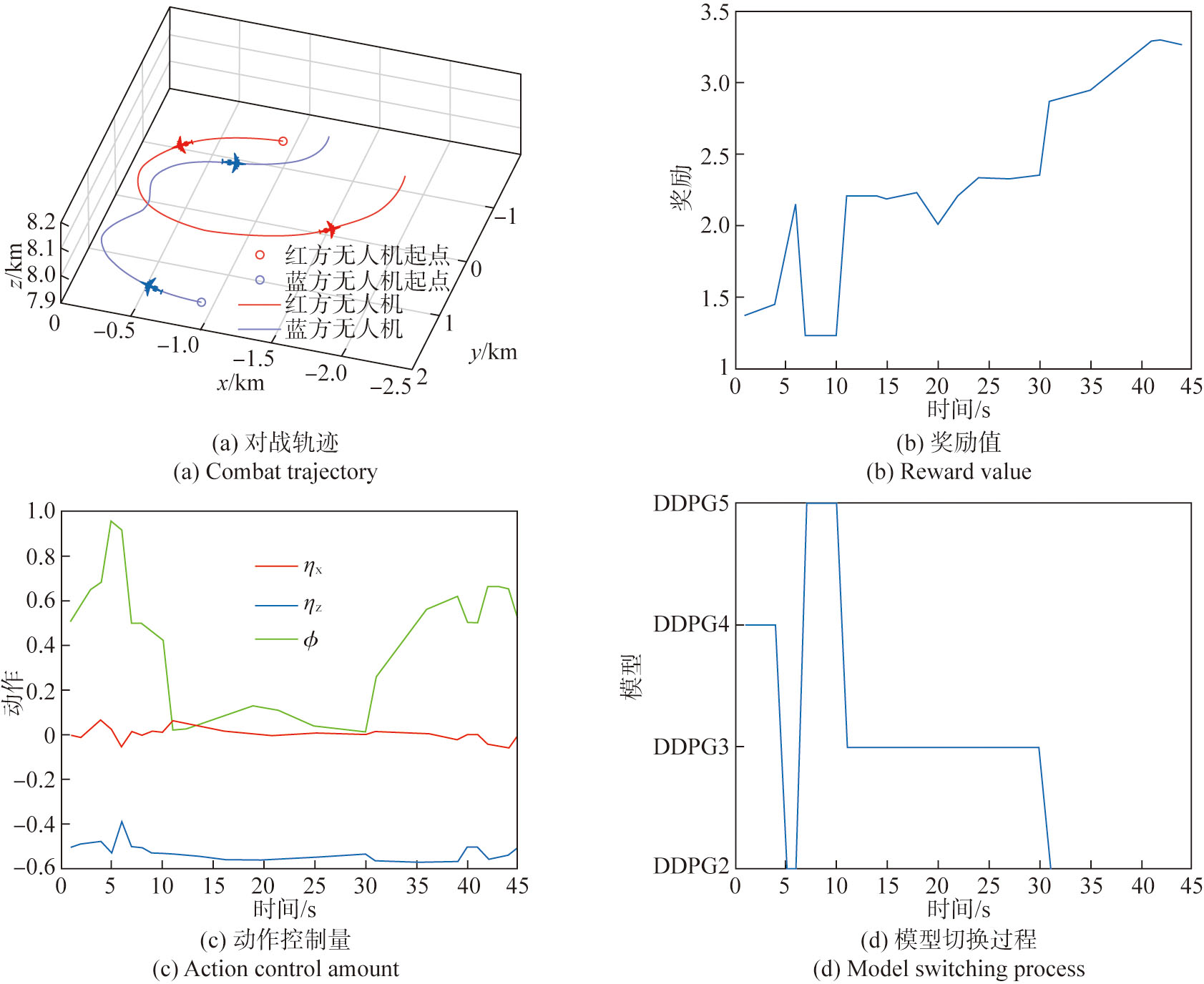
王昱, 任田君, 范子琳, 等. 基于角度特征的分布式DDPG无人机追击决策[J]. 控制理论与应用, 2025, 42(7):1356-1366.
|
|
WANG Y, REN T J, FAN Z L, et al. Distributed DDPG UAV pursuit decision based on angle features[J]. Control Theory & Applications, 2025, 42(7):1356-1366. (in Chinese)
|
| [22] |
王昱, 任田君, 范子琳. 基于引导Minimax-DDQN的无人机空战机动决策[J]. 计算机应用, 2023, 43(8):2636-2643.
doi: 10.11772/j.issn.1001-9081.2022071069
|
|
WANG Y, REN T J, FAN Z L. Air combat maneuver decision of unmanned aerial vehicle based on guided minimax-DDQN[J]. Journal of Computer Applications, 2023, 43(8):2636-2643. (in Chinese)
doi: 10.11772/j.issn.1001-9081.2022071069
|

 ), 李远鹏1, 郭中宇1, 李硕1, 任田君2
), 李远鹏1, 郭中宇1, 李硕1, 任田君2
 京公网安备11010802024360号 京ICP备05059581号-4
京公网安备11010802024360号 京ICP备05059581号-4