
主管单位:中国科学技术协会
主办单位:中国兵工学会
ISSN 1000-1093 CN 11-2176/TJ
主办单位:中国兵工学会
ISSN 1000-1093 CN 11-2176/TJ
兵工学报 ›› 2025, Vol. 46 ›› Issue (7): 240568-.doi: 10.12382/bgxb.2024.0568
王存灿, 王晓芳*( ), 林海
), 林海
收稿日期:2024-07-10
上线日期:2025-08-12
通讯作者:
WANG Cuncan, WANG Xiaofang*(), LIN Hai
Received:2024-07-10
Online:2025-08-12
摘要:
针对高超声速再入滑翔飞行器在复杂环境中以指定角度同时命中目标的协同制导问题,提出一种基于元学习和强化学习算法的协同制导律。考虑复杂作战环境的干扰,建立协同制导问题的马尔可夫决策模型,以飞行器运动状态和比例导引系数作为状态空间和动作空间,综合考虑多飞行器攻击目标的相对距离、剩余飞行时间差以及过载情况设计奖励函数。基于元学习理论和强化学习算法将近端策略优化算法与门控循环单元相结合,通过学习相似协同制导任务的共同特征,提高协同制导策略在复杂干扰环境下的命中精度,实现攻击角度和攻击时间约束,同时提升协同制导策略对不同作战场景的适应性。仿真结果表明:该协同制导律能够在复杂战场环境下实现多飞行器以指定攻击角度对目标的同时攻击,并快速适应新的协同制导任务,在协同作战场景发生变化时仍能保持良好性能。
中图分类号:
王存灿, 王晓芳, 林海. 一种元学习和强化学习结合的多飞行器协同制导律[J]. 兵工学报, 2025, 46(7): 240568-.
WANG Cuncan, WANG Xiaofang, LIN Hai. A Cooperative Guidance Law Based on Meta-learning and Reinforcement Learning for Multiple Aerial Vehicles[J]. Acta Armamentarii, 2025, 46(7): 240568-.
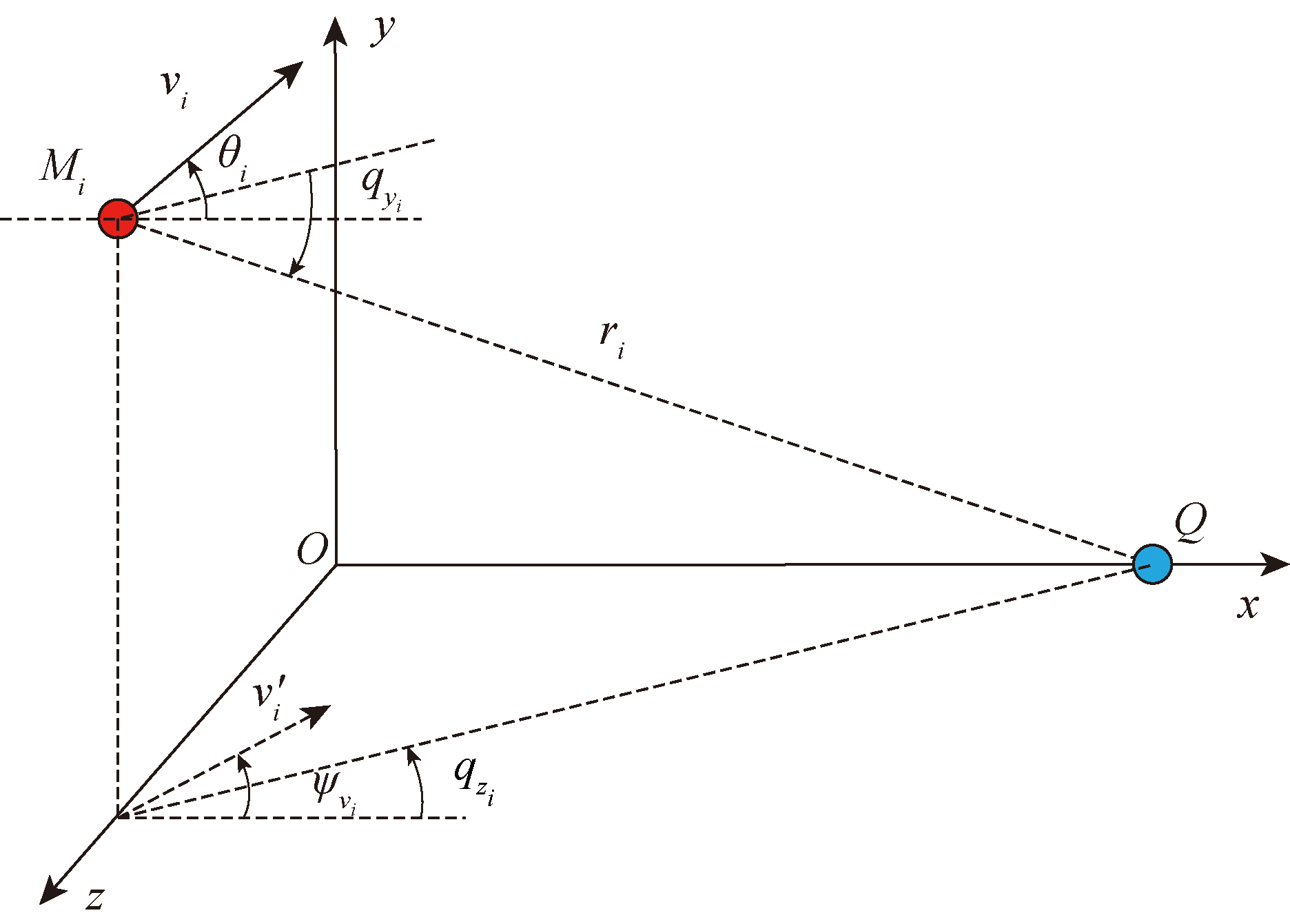
图1 弹目相对运动关系图
Fig.1 Missile-target relative motion diagram
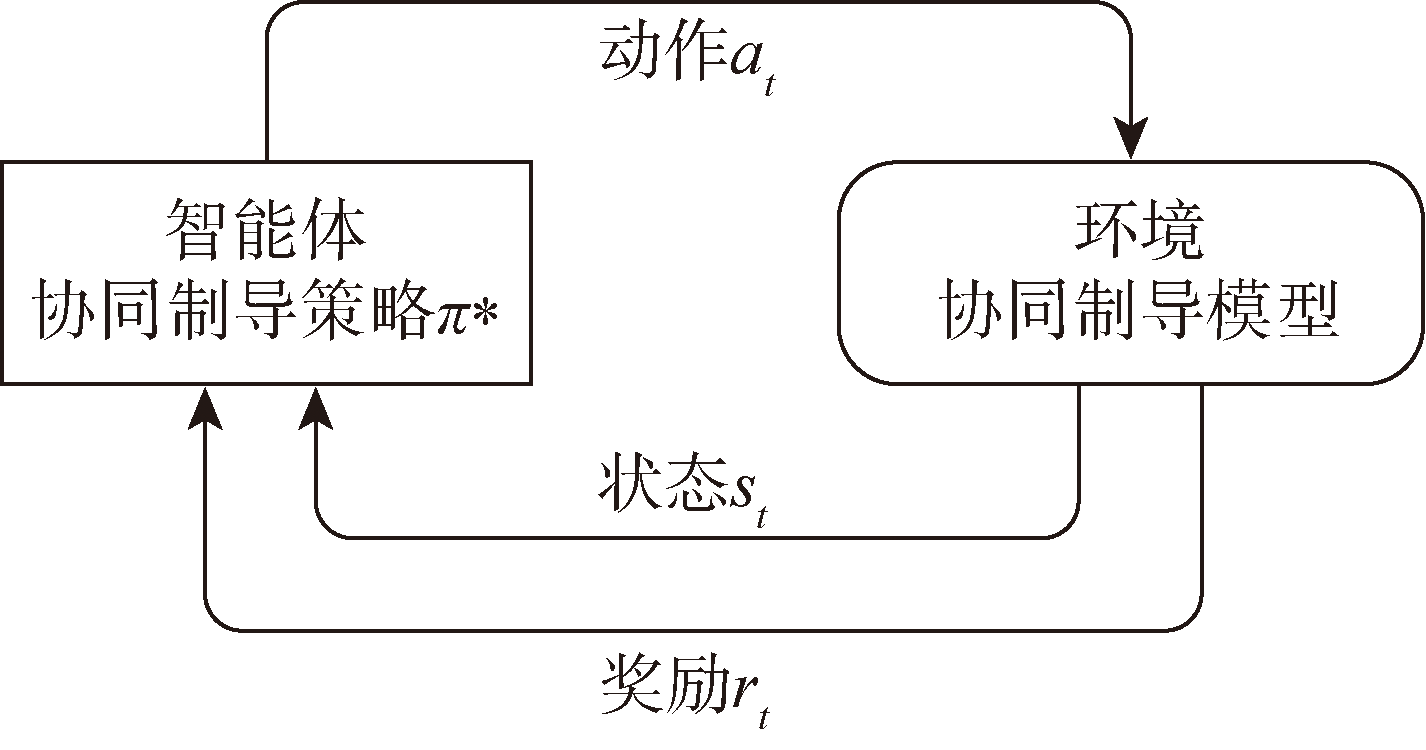
图2 协同制导交互过程
Fig.2 Cooperative guidance interaction process
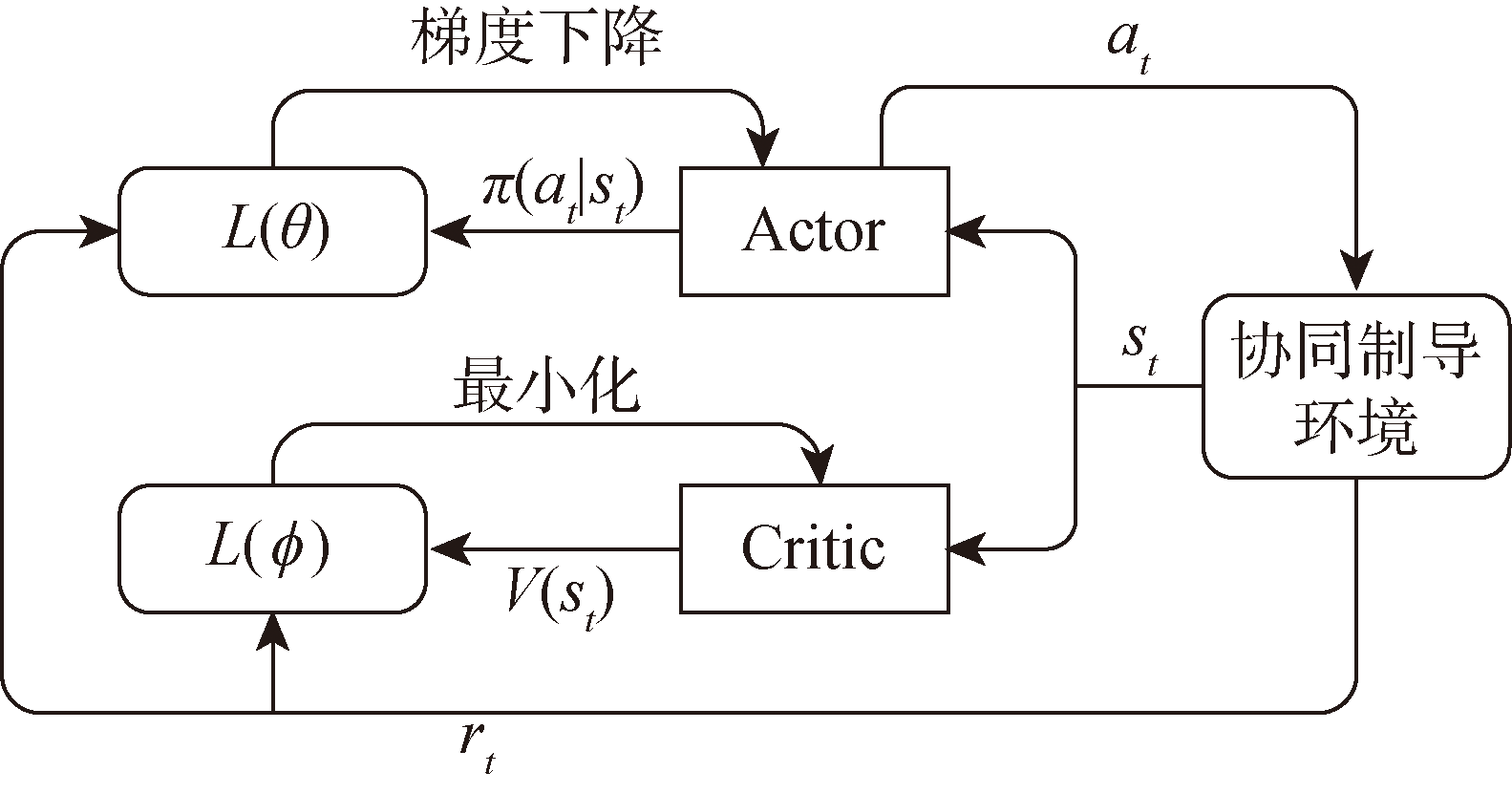
图3 PPO算法网络结构框图
Fig.3 Structural diagram of PPO algorithm network

图4 GRU网络的基本结构
Fig.4 Basic structure of GRU network
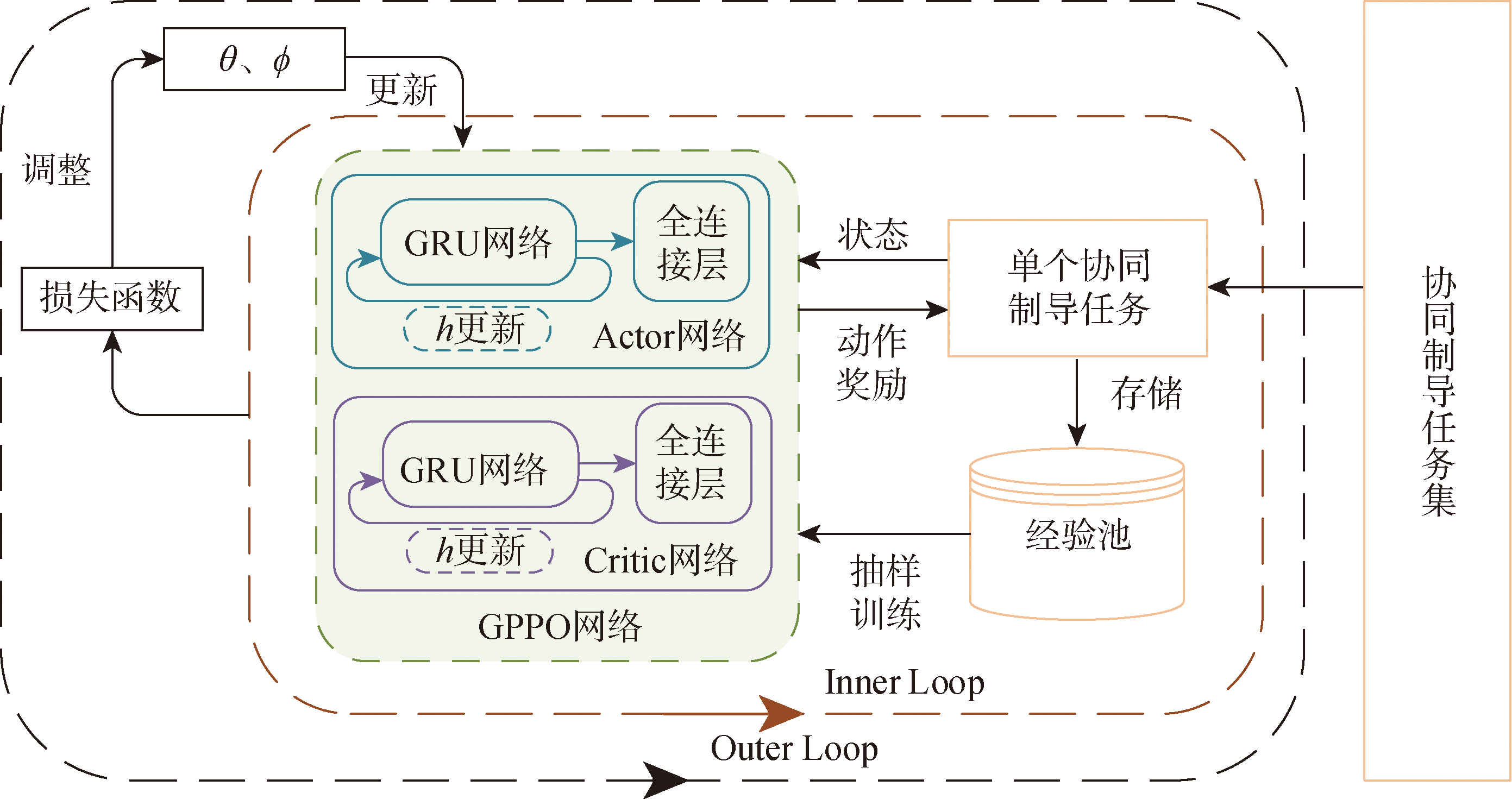
图5 GPPO算法结构框图
Fig.5 Structural diagram of GPPO algorithm
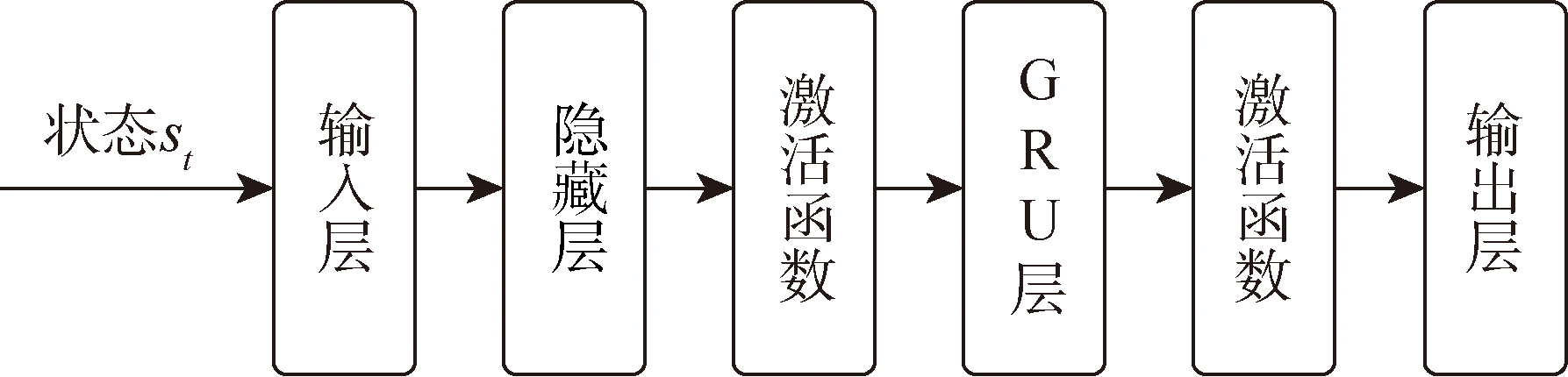
图6 Actor和Critic网络的基本结构
Fig.6 Basic structure of Actor and Critic networks
| 参数 | 初始值 |
|---|---|
| 目标初始位置/m | (45000,0,0) |
| M1初始位置/m | (0,30000,0) |
| M1速度/(m·s-1) | 1200 |
| M1初始弹道倾角/(°) | 0 |
| M1初始弹道偏角/(°) | -5 |
| M2初始位置/m | (0,30000,1000) |
| M2速度/(m·s-1) | 1200 |
| M2初始弹道倾角/(°) | 0 |
| M2初始弹道偏角/(°) | -20 |
| M3初始位置/m | (0,30000,-1000) |
| M3速度/(m·s-1) | 1200 |
| M3初始弹道倾角/(°) | 0 |
| M3初始弹道偏角/(°) | 15 |
表1 3枚导弹和目标的初始参数
Table 1 Initial parameters of 3 missiles and the target
| 参数 | 初始值 |
|---|---|
| 目标初始位置/m | (45000,0,0) |
| M1初始位置/m | (0,30000,0) |
| M1速度/(m·s-1) | 1200 |
| M1初始弹道倾角/(°) | 0 |
| M1初始弹道偏角/(°) | -5 |
| M2初始位置/m | (0,30000,1000) |
| M2速度/(m·s-1) | 1200 |
| M2初始弹道倾角/(°) | 0 |
| M2初始弹道偏角/(°) | -20 |
| M3初始位置/m | (0,30000,-1000) |
| M3速度/(m·s-1) | 1200 |
| M3初始弹道倾角/(°) | 0 |
| M3初始弹道偏角/(°) | 15 |
| 参数 | 数值 | 参数 | 数值 |
|---|---|---|---|
| a | 100 | b4 | -10 |
| b1 | -0.5 | b5 | -50 |
| b2 | 30 | c1 | 0.1 |
| b3 | 10 | c2 | -0.1 |
表2 奖励函数参数
Table 2 Reward function parameters
| 参数 | 数值 | 参数 | 数值 |
|---|---|---|---|
| a | 100 | b4 | -10 |
| b1 | -0.5 | b5 | -50 |
| b2 | 30 | c1 | 0.1 |
| b3 | 10 | c2 | -0.1 |
| 参数 | Actor网络 | Critic网络 |
|---|---|---|
| 输入层 | 10 | 10 |
| 隐藏层 | 64 | 64 |
| 激活函数 | Tanh | Tanh |
| GRU层 | 64 | 64 |
| 激活函数 | Tanh | Tanh |
| 输出层 | 3 | 1 |
| 激活函数 | Tanh | - |
表3 网络结构参数
Table 3 Network structure parameters
| 参数 | Actor网络 | Critic网络 |
|---|---|---|
| 输入层 | 10 | 10 |
| 隐藏层 | 64 | 64 |
| 激活函数 | Tanh | Tanh |
| GRU层 | 64 | 64 |
| 激活函数 | Tanh | Tanh |
| 输出层 | 3 | 1 |
| 激活函数 | Tanh | - |
| 参数 | 数值 |
|---|---|
| 学习率 | 0.0003 |
| 奖励折扣系数γ | 0.99 |
| GAE系数λ | 0.95 |
| 裁剪因子ε | 0.2 |
表4 算法训练超参数
Table 4 Algorithm training hyperparameters
| 参数 | 数值 |
|---|---|
| 学习率 | 0.0003 |
| 奖励折扣系数γ | 0.99 |
| GAE系数λ | 0.95 |
| 裁剪因子ε | 0.2 |
| 干扰 | 大小 |
|---|---|
| (i=1,2,3)/((°)·s-1) | 0.1N(0,1) |
| (i=1,2,3)/((°)·s-1) | 0.1N(0,1) |
表5 导弹所受的干扰
Table 5 Interference experienced by the missile
| 干扰 | 大小 |
|---|---|
| (i=1,2,3)/((°)·s-1) | 0.1N(0,1) |
| (i=1,2,3)/((°)·s-1) | 0.1N(0,1) |
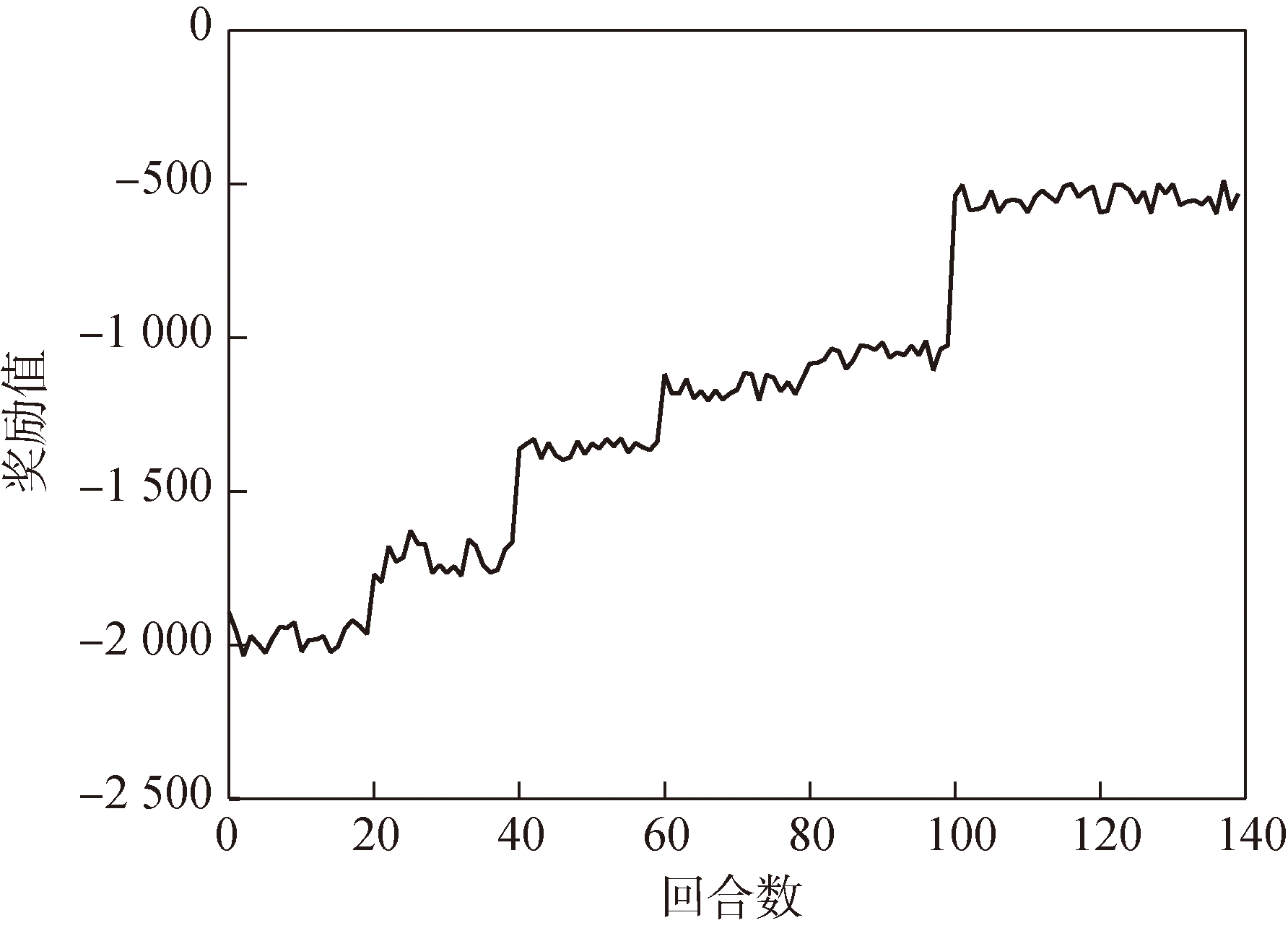
图7 PPO制导律网络奖励函数曲线
Fig.7 Reward function curve of PPO guidance network

图8 导弹运动轨迹
Fig.8 Missile trajectory
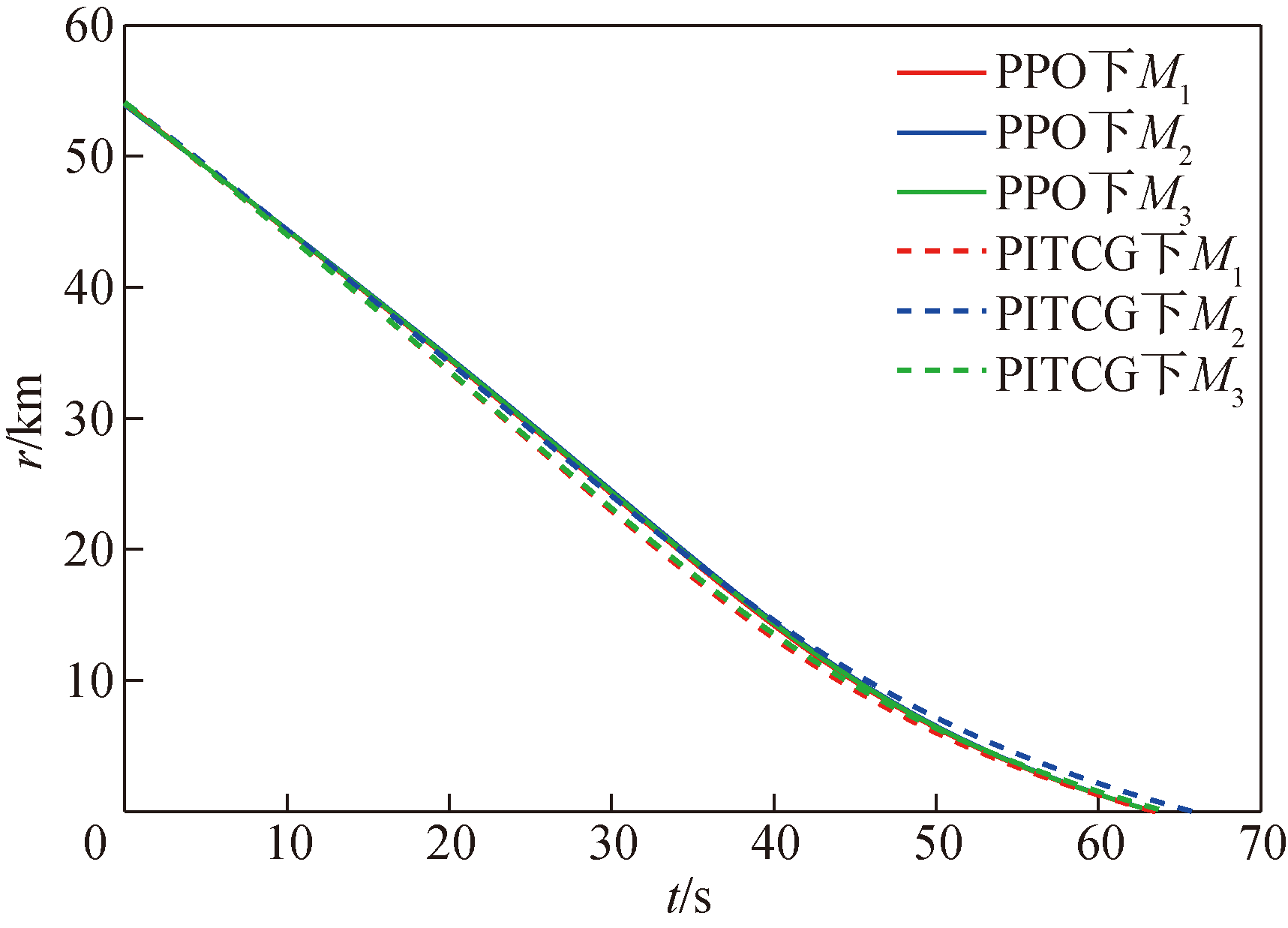
图9 弹目相对距离随时间变化曲线
Fig.9 Missile-target relative distance over time
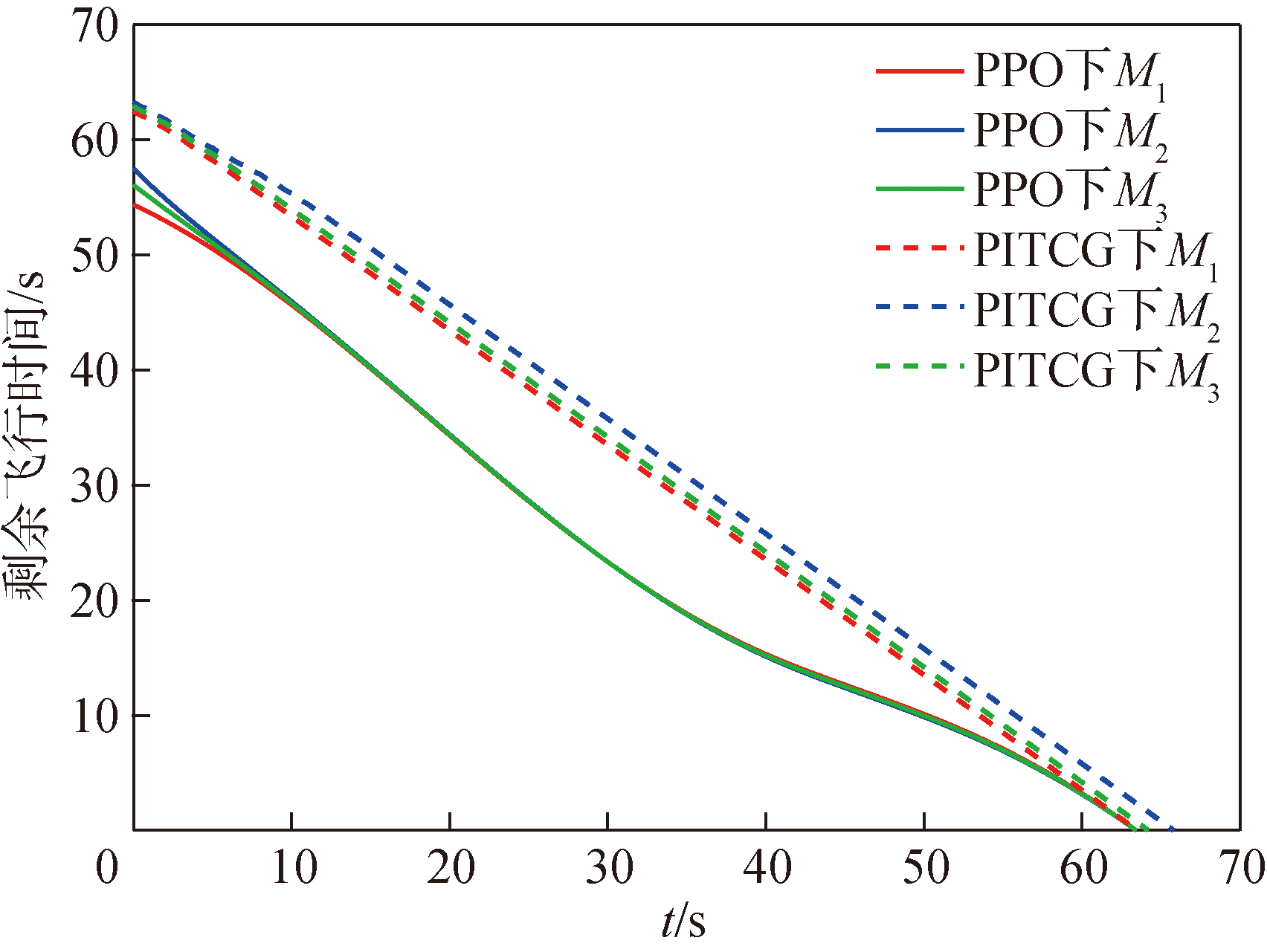
图10 剩余飞行时间tgo随时间变化曲线
Fig.10 Remaining flight time tgo over time
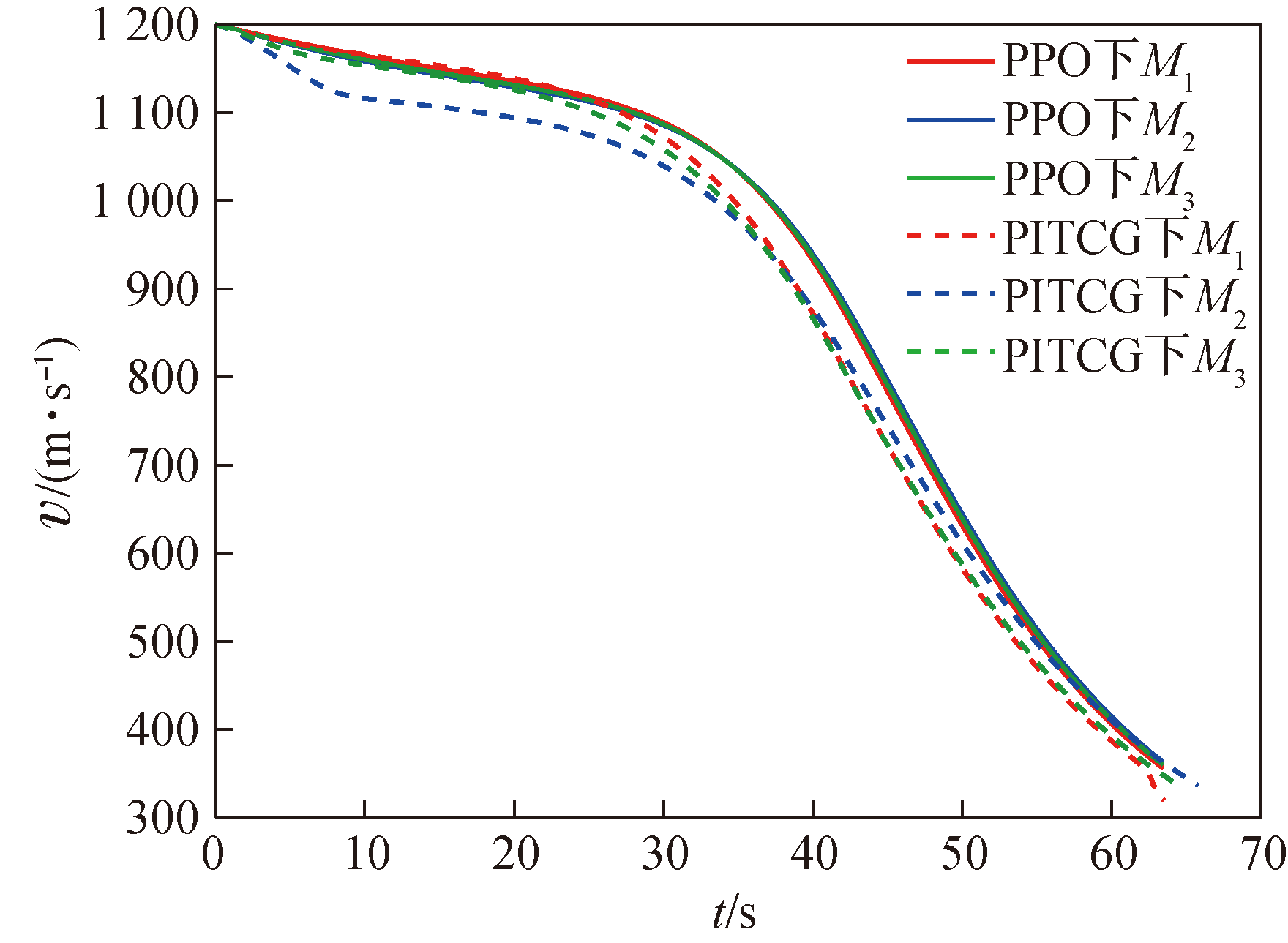
图11 导弹速度V随时间变化曲线
Fig.11 Missile velocity V over time
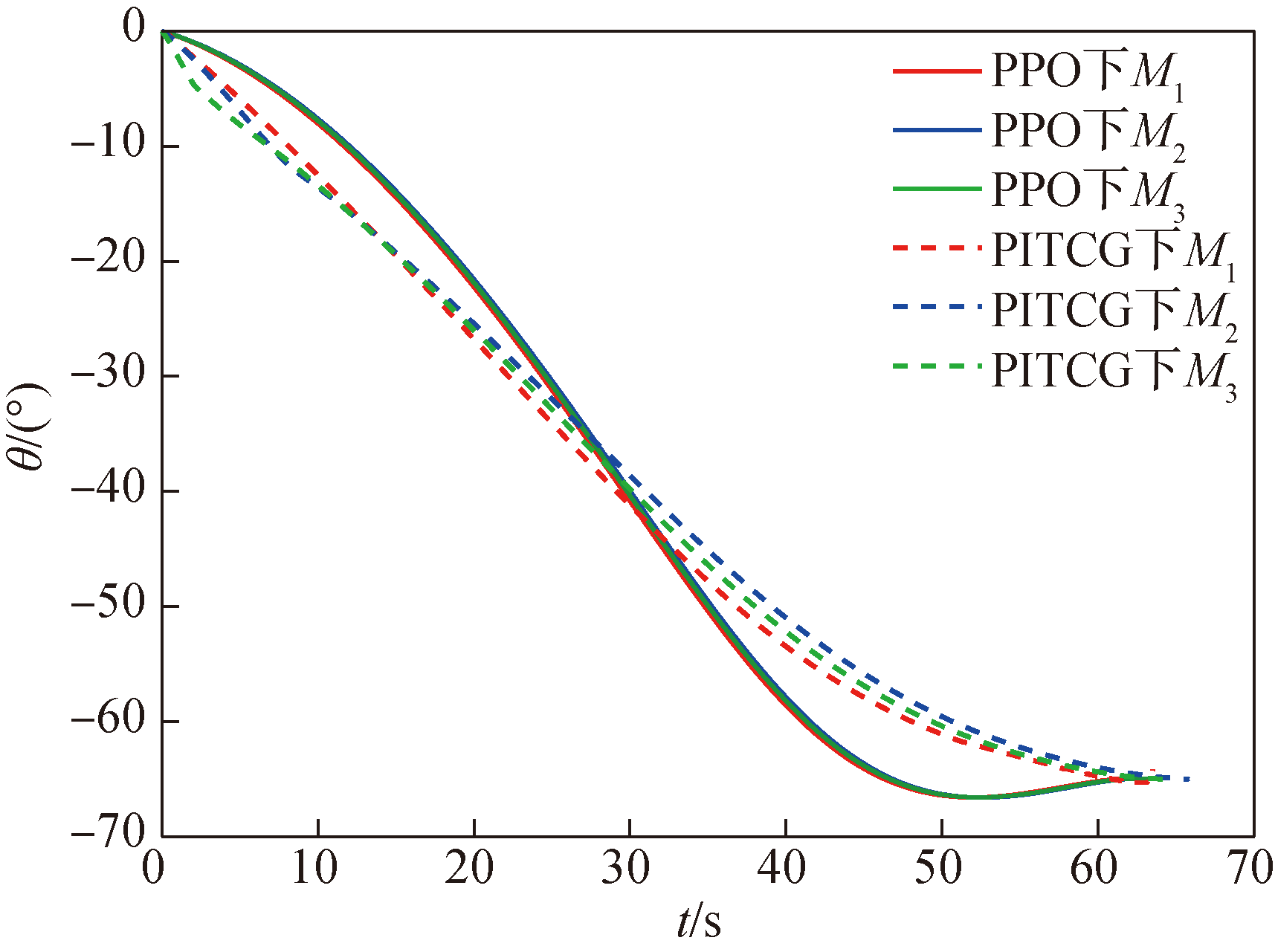
图12 导弹弹道倾角θ随时间变化曲线
Fig.12 Missile trajectory inclination angle θ over time
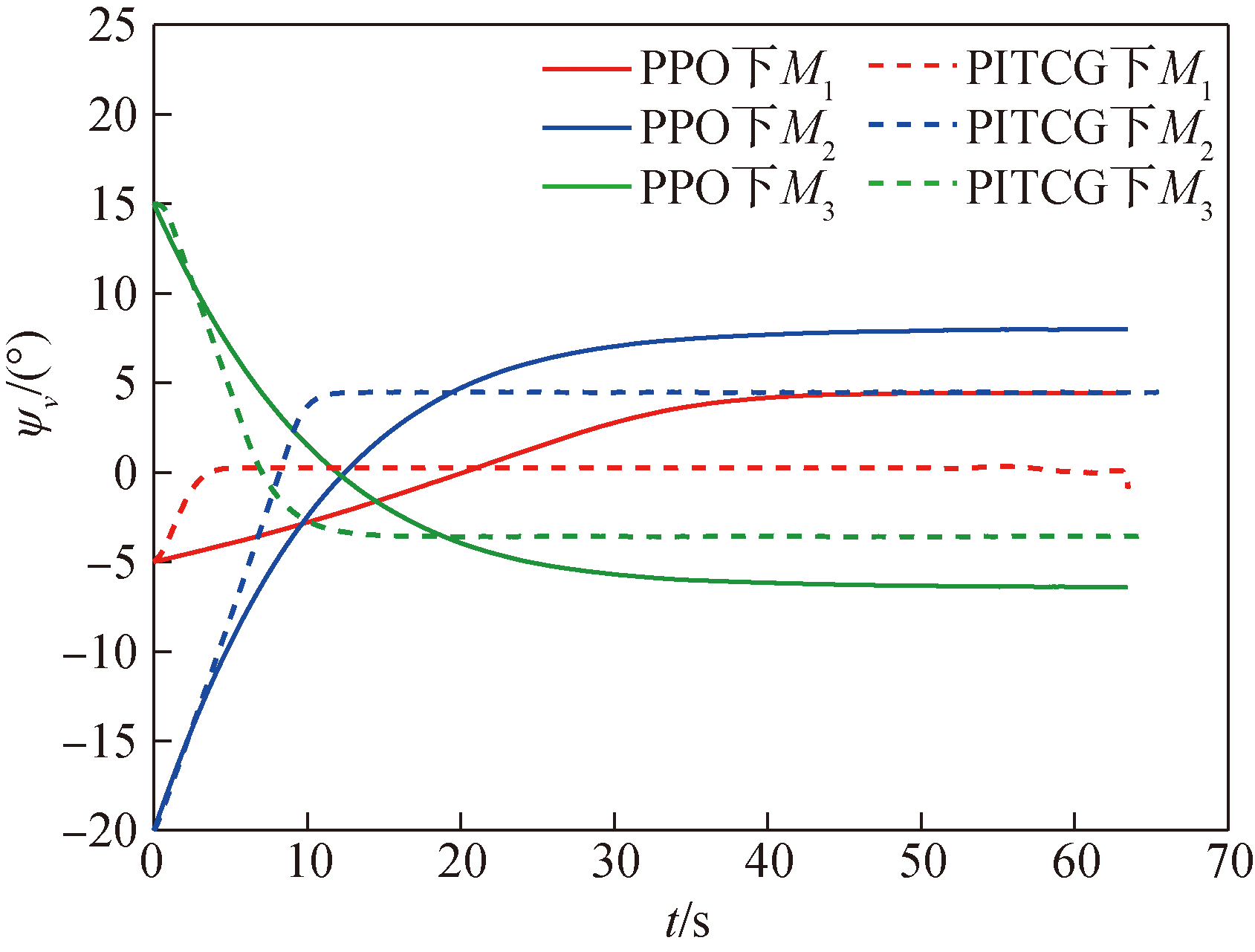
图13 导弹弹道偏角ψV随时间变化曲线
Fig.13 Missile trajectory deviation angle ψV over time
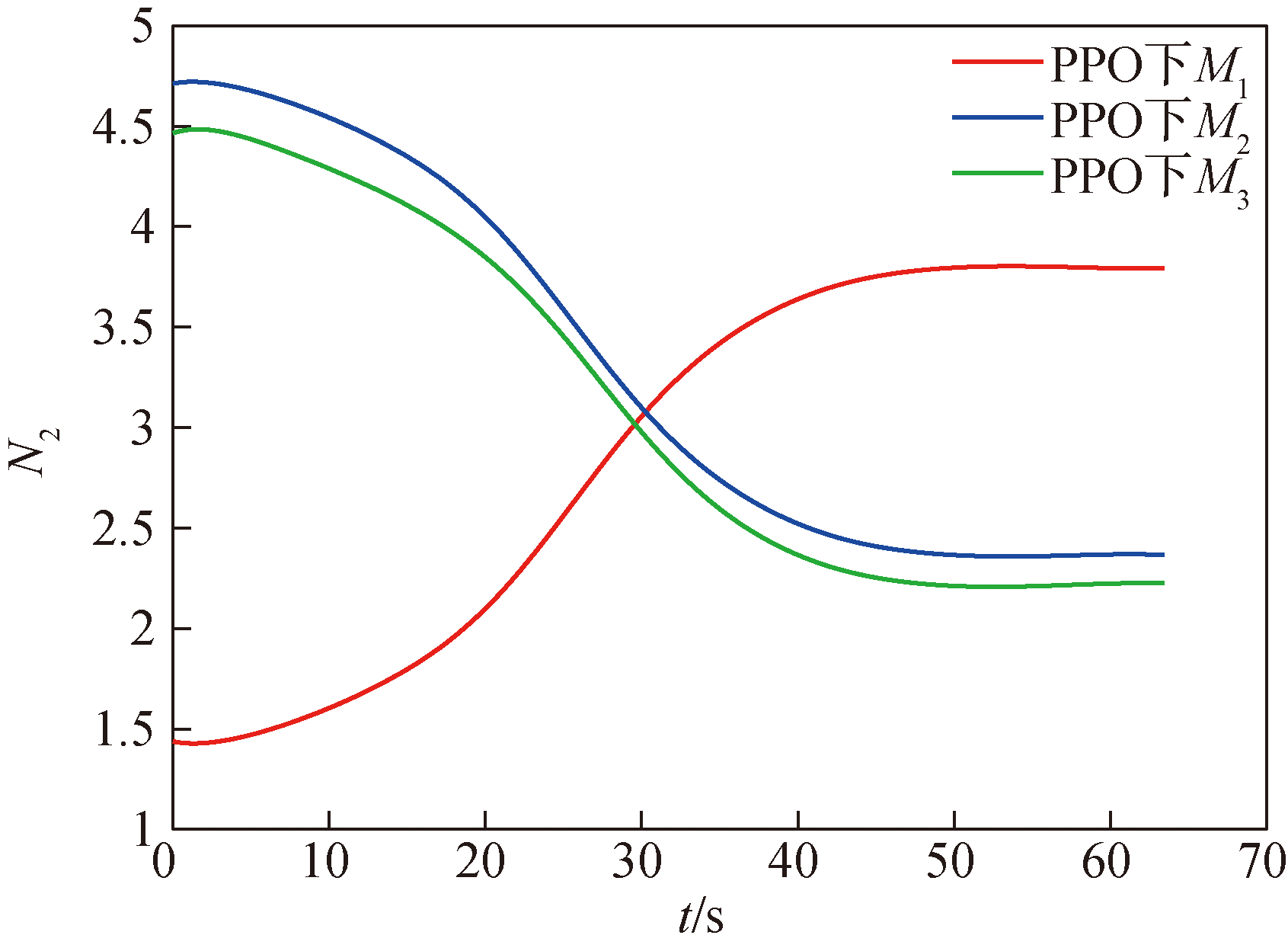
图14 PPO下导引系数变化曲线
Fig.14 The curve of guidance coefficient variation under PPO
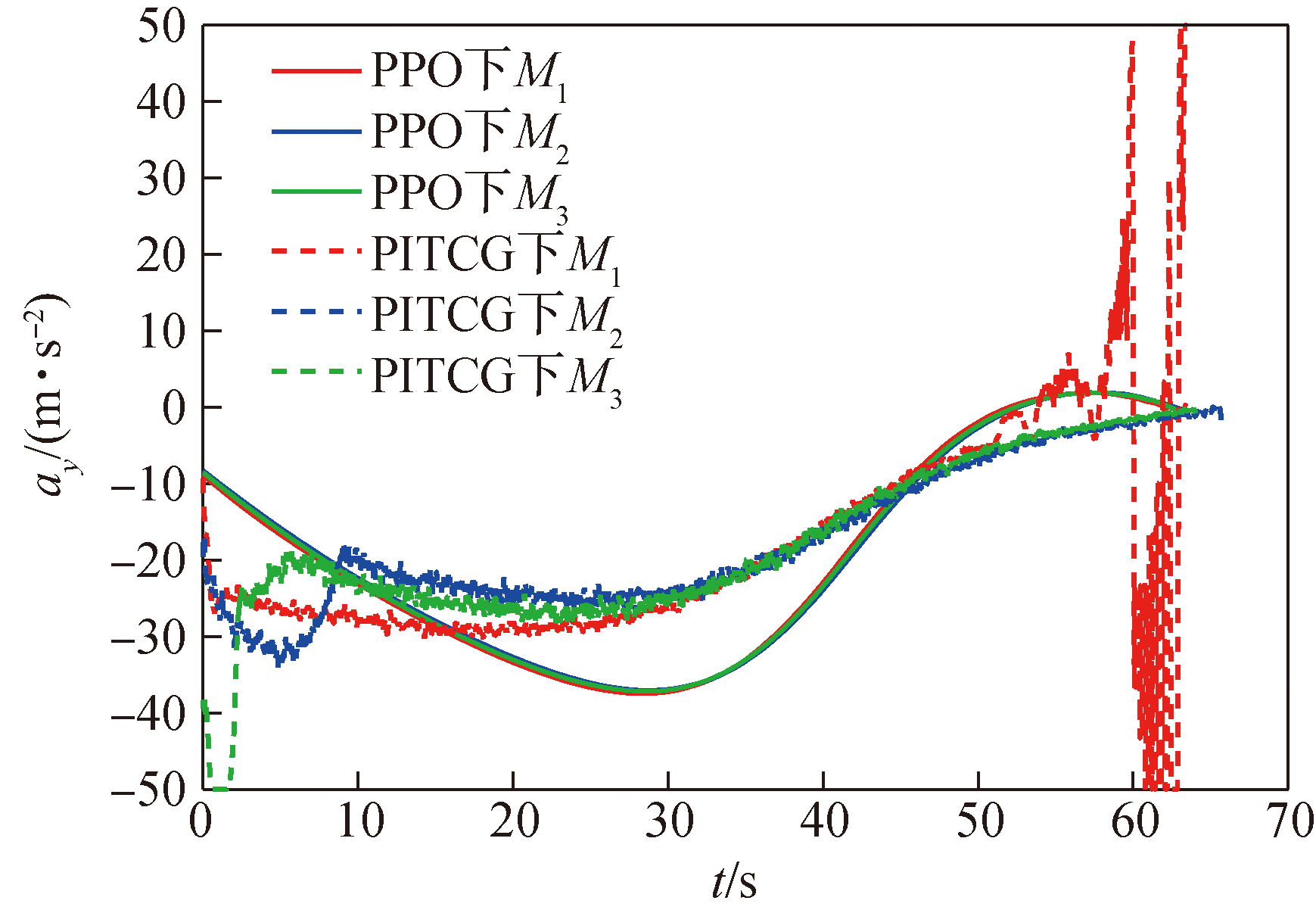
图15 导弹纵向加速度曲线
Fig.15 Missile longitudinal acceleration curve
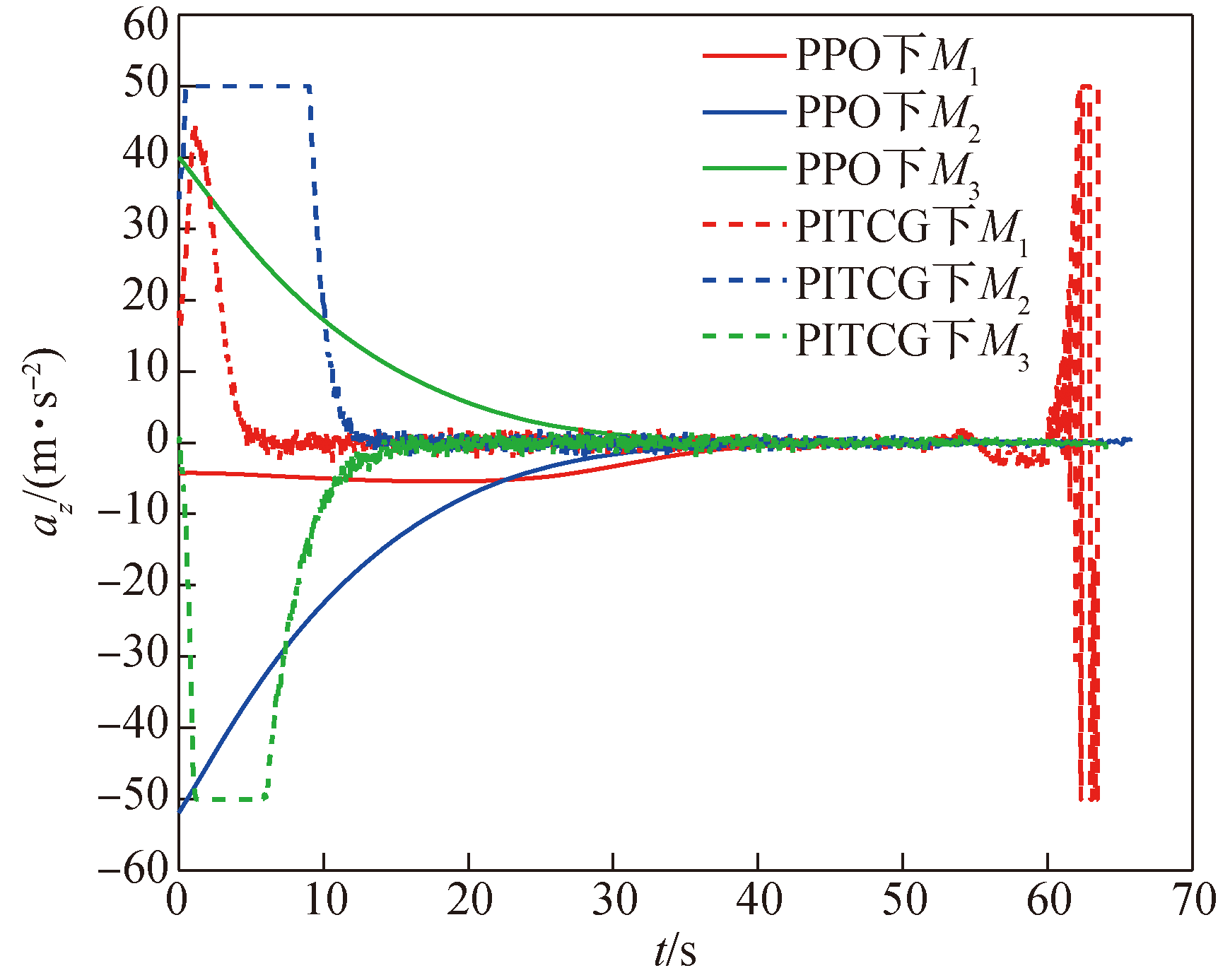
图16 导弹侧向加速度曲线
Fig.16 Missile lateral acceleration curve
| 制导律 | 导弹 | 脱靶量/m | 攻击时间/s | 攻击角度/(°) |
|---|---|---|---|---|
| PPO策略 | M1 | 0.74 | 63.45 | -65.00 |
| M2 | 3.42 | 63.46 | -64.98 | |
| M3 | 2.69 | 63.45 | -65.00 | |
| PITCG | M1 | 20.85 | 63.47 | -64.98 |
| M2 | 30.21 | 65.74 | -65.05 | |
| M3 | 23.57 | 64.17 | -65.04 |
表6 导弹脱靶量、攻击时间和攻击角度
Table 6 Missile miss distance,attack time,and angle of attack
| 制导律 | 导弹 | 脱靶量/m | 攻击时间/s | 攻击角度/(°) |
|---|---|---|---|---|
| PPO策略 | M1 | 0.74 | 63.45 | -65.00 |
| M2 | 3.42 | 63.46 | -64.98 | |
| M3 | 2.69 | 63.45 | -65.00 | |
| PITCG | M1 | 20.85 | 63.47 | -64.98 |
| M2 | 30.21 | 65.74 | -65.05 | |
| M3 | 23.57 | 64.17 | -65.04 |
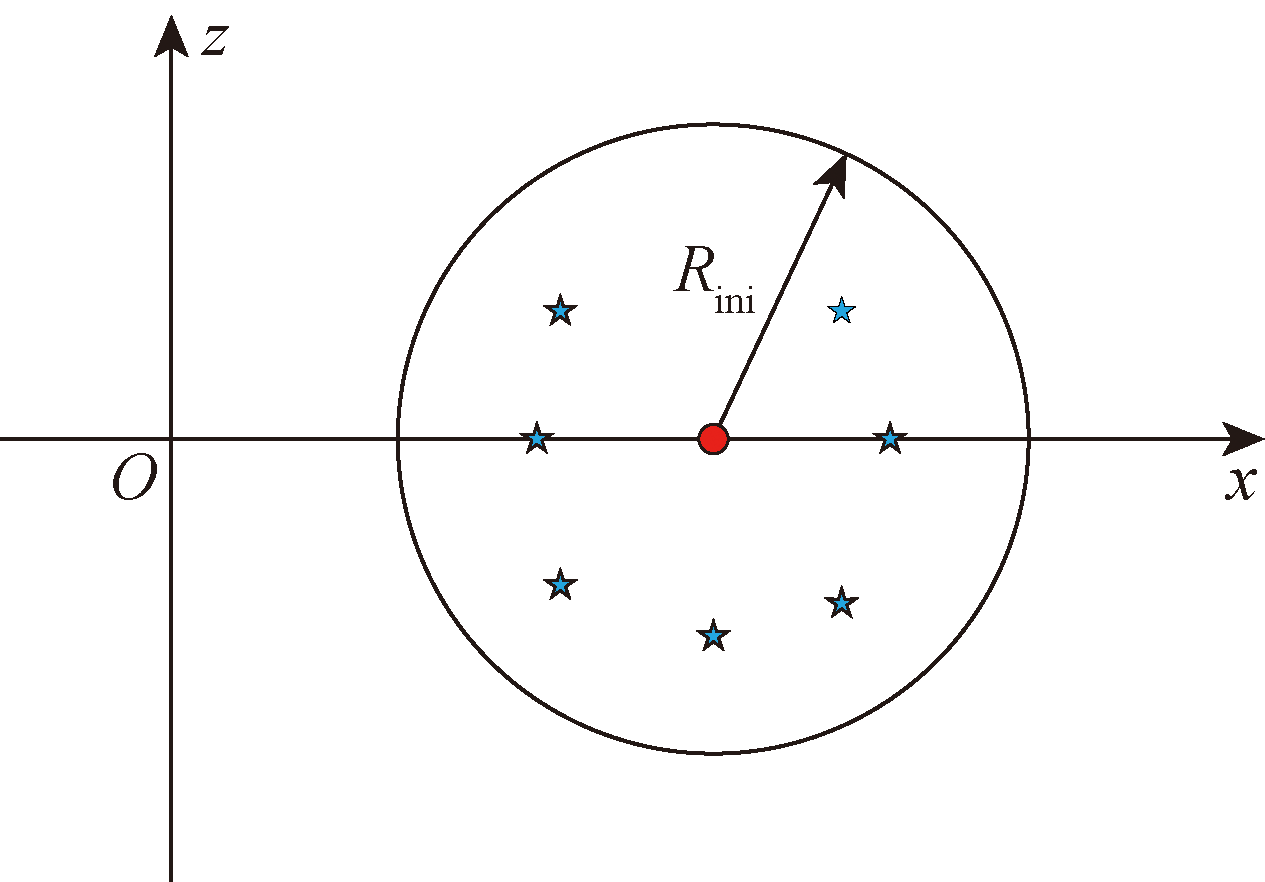
图17 目标位置示意图
Fig.17 Schematic diagram of target position
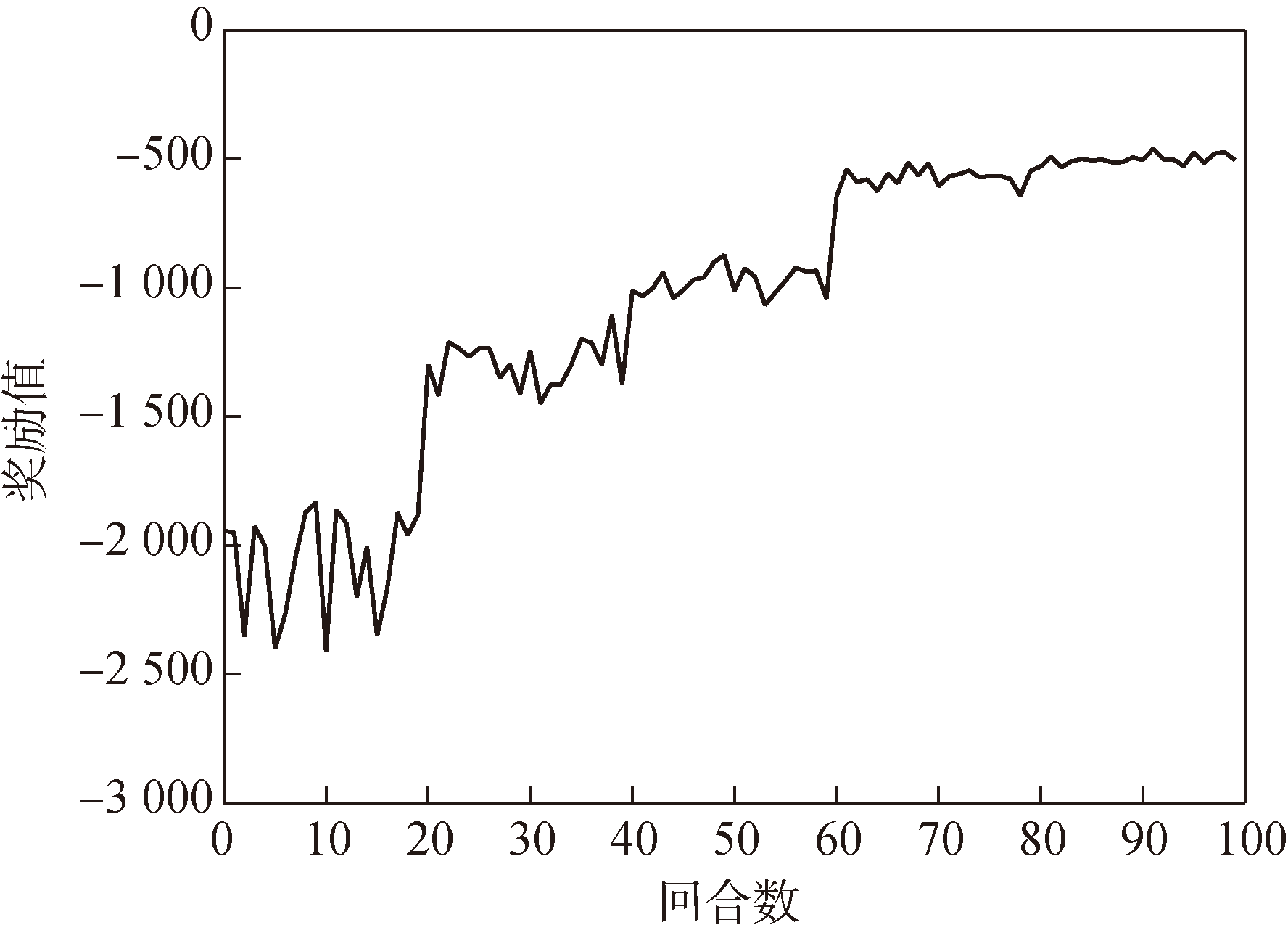
图18 GPPO制导律网络奖励函数曲线
Fig.18 Reward function curve of GPPO guidance network
| 制导律 | 脱靶量/m | 攻击时间误差/s | 攻击角度误差/(°) | |||
|---|---|---|---|---|---|---|
| 平均值 | 标准差 | 平均值 | 标准差 | 平均值 | 标准差 | |
| PPO | 6.79 | 1.88 | 0.42 | 0.76 | 0.07 | 0.17 |
| GPPO | 5.46 | 0.49 | 0.17 | 0.18 | 0.03 | 0.08 |
表7 在线应用情况1下制导律性能对比
Table 7 Online performance comparison of guidance laws under case 1
| 制导律 | 脱靶量/m | 攻击时间误差/s | 攻击角度误差/(°) | |||
|---|---|---|---|---|---|---|
| 平均值 | 标准差 | 平均值 | 标准差 | 平均值 | 标准差 | |
| PPO | 6.79 | 1.88 | 0.42 | 0.76 | 0.07 | 0.17 |
| GPPO | 5.46 | 0.49 | 0.17 | 0.18 | 0.03 | 0.08 |
| 制导律 | 脱靶量/m | 攻击时间误差/s | 攻击角度 误差/(°) | 平均训练 回合数 | |||
|---|---|---|---|---|---|---|---|
| 平均值 | 标准差 | 平均值 | 标准差 | 平均值 | 标准差 | ||
| PPO | 4.89 | 0.89 | 0.07 | 0.04 | 0.03 | 0.06 | 85 |
| GPPO | 2.57 | 0.61 | 0.02 | 0.02 | 0.01 | 0.02 | 40 |
表8 在线应用情况2下制导律性能对比
Table 8 Online performance comparison of guidance laws under case 2
| 制导律 | 脱靶量/m | 攻击时间误差/s | 攻击角度 误差/(°) | 平均训练 回合数 | |||
|---|---|---|---|---|---|---|---|
| 平均值 | 标准差 | 平均值 | 标准差 | 平均值 | 标准差 | ||
| PPO | 4.89 | 0.89 | 0.07 | 0.04 | 0.03 | 0.06 | 85 |
| GPPO | 2.57 | 0.61 | 0.02 | 0.02 | 0.01 | 0.02 | 40 |
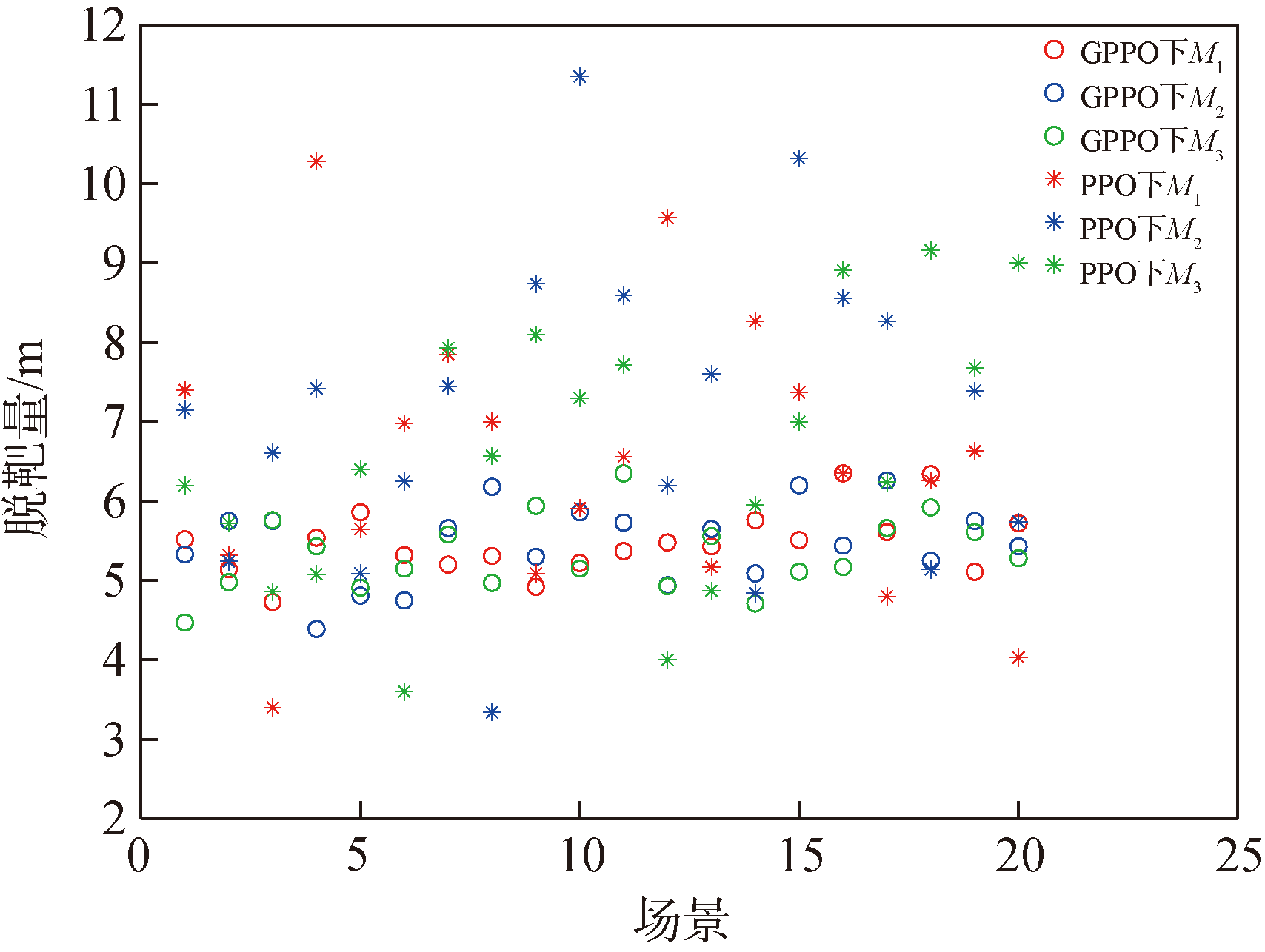
图19 情况1脱靶量结果图
Fig.19 Miss distance in Case 1
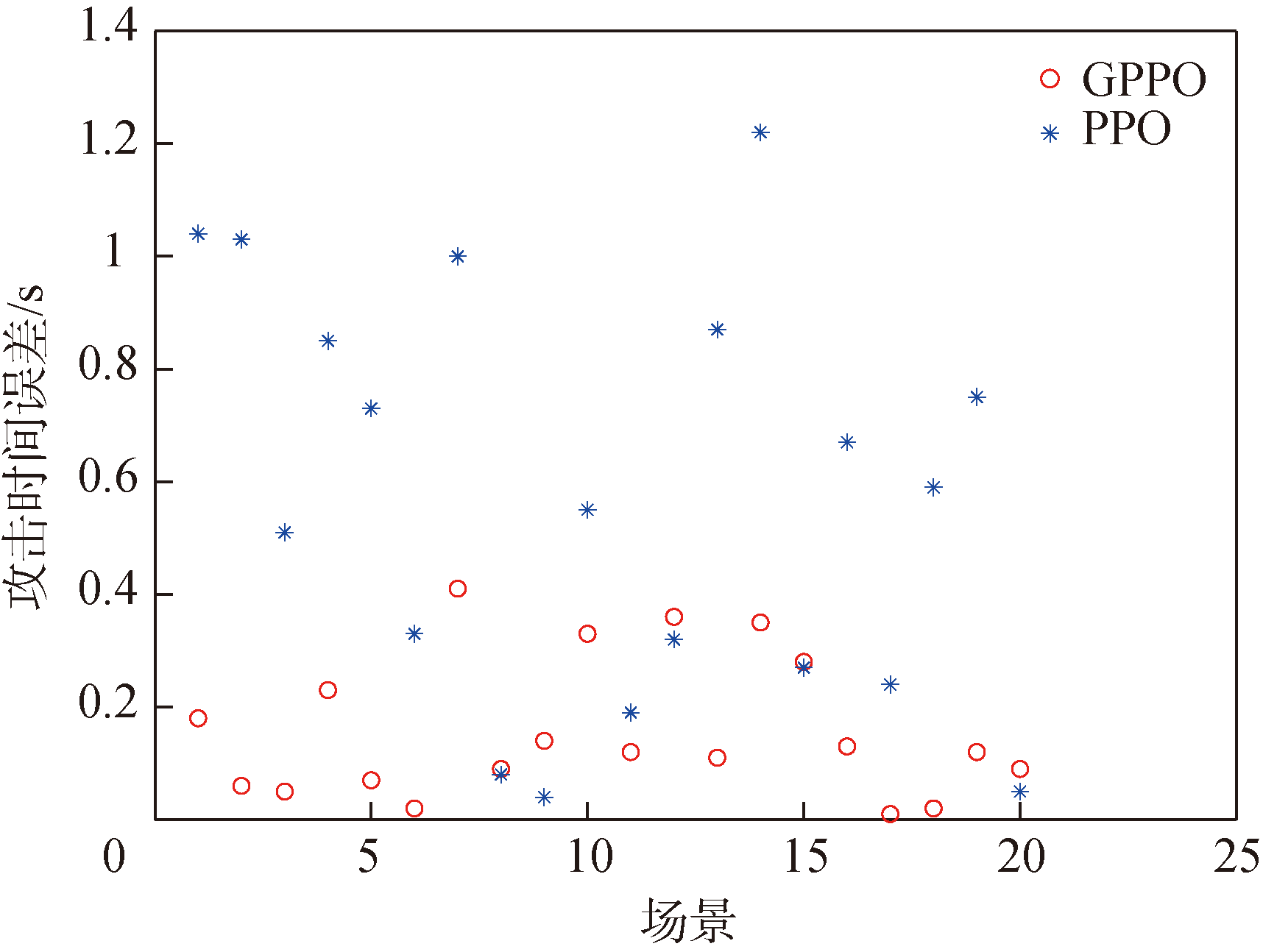
图20 情况1攻击时间误差结果图
Fig.20 Attack time error in Case 1
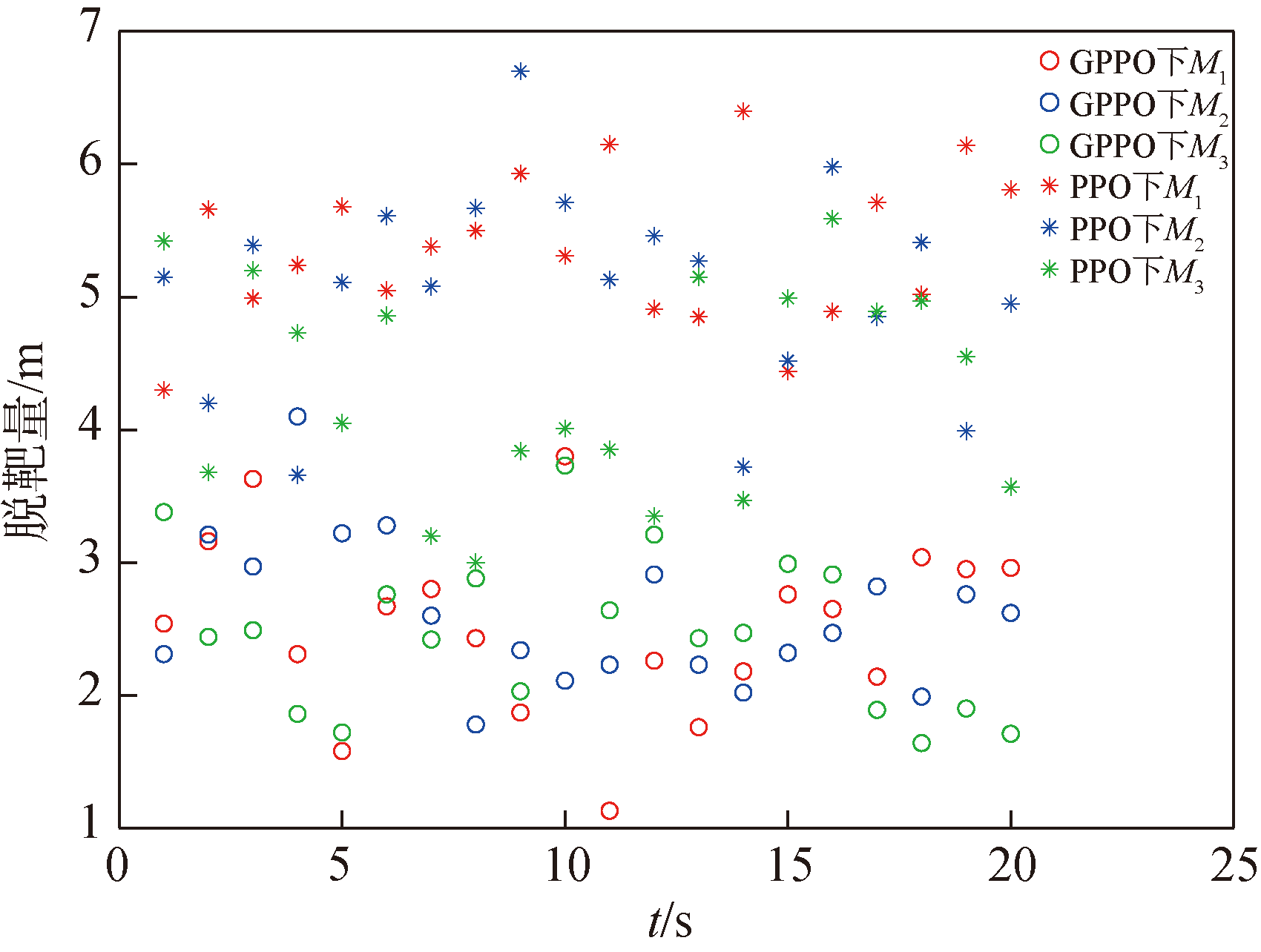
图21 情况2脱靶量结果图
Fig.21 Miss distance in Case 2
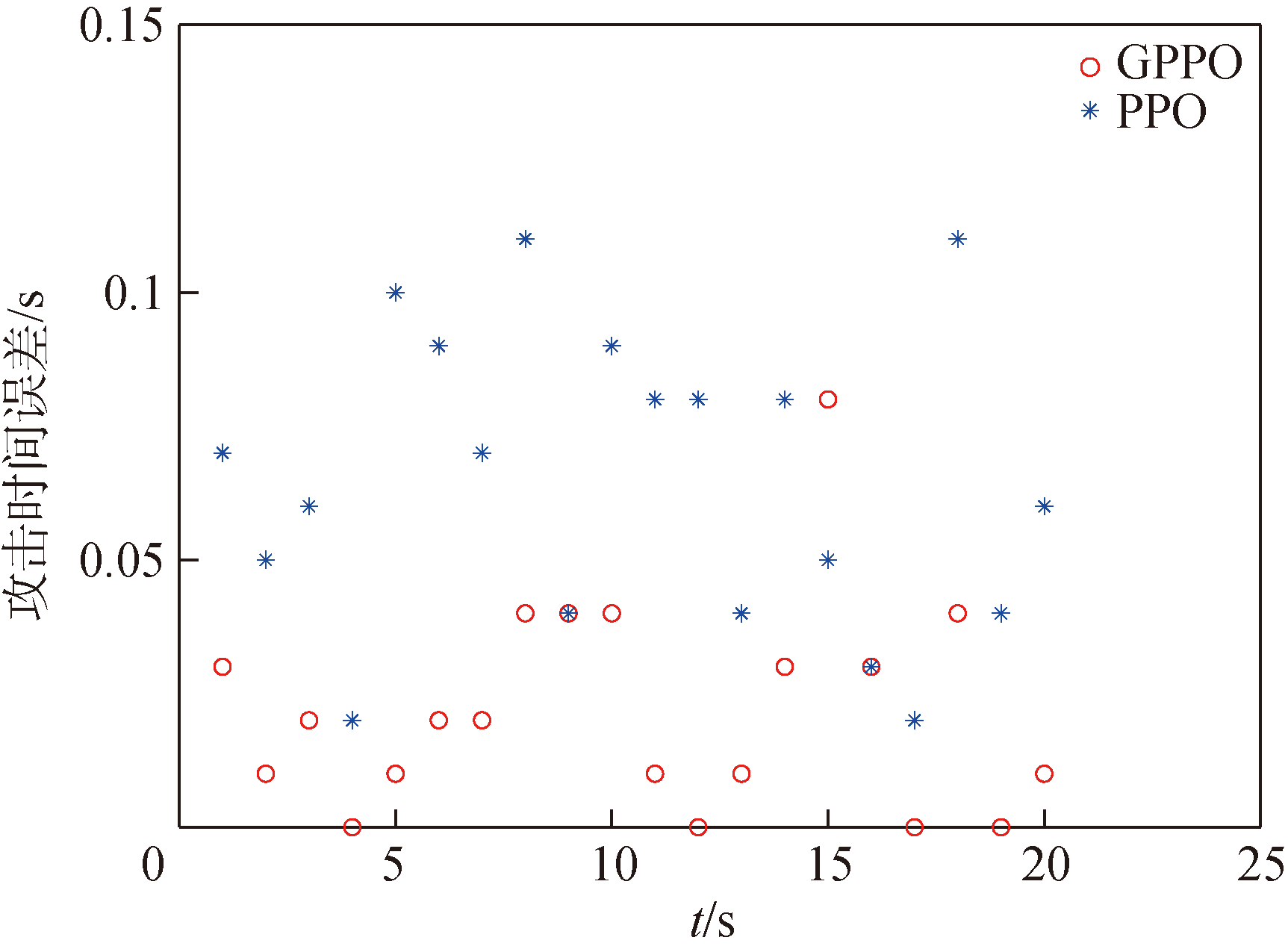
图22 情况2攻击时间误差结果图
Fig.22 Attack time error in Case 2
| 参数 | 数值 |
|---|---|
| 目标位置/m | (42064,0,3535) |
| 弹1弹道偏角/(°) | 2 |
| 弹2弹道偏角/(°) | -17 |
| 弹3弹道偏角/(°) | 5 |
| 期望攻击角度/(°) | -65 |
表9 场景一参数
Table 9 The parameters table of Scenario 1
| 参数 | 数值 |
|---|---|
| 目标位置/m | (42064,0,3535) |
| 弹1弹道偏角/(°) | 2 |
| 弹2弹道偏角/(°) | -17 |
| 弹3弹道偏角/(°) | 5 |
| 期望攻击角度/(°) | -65 |
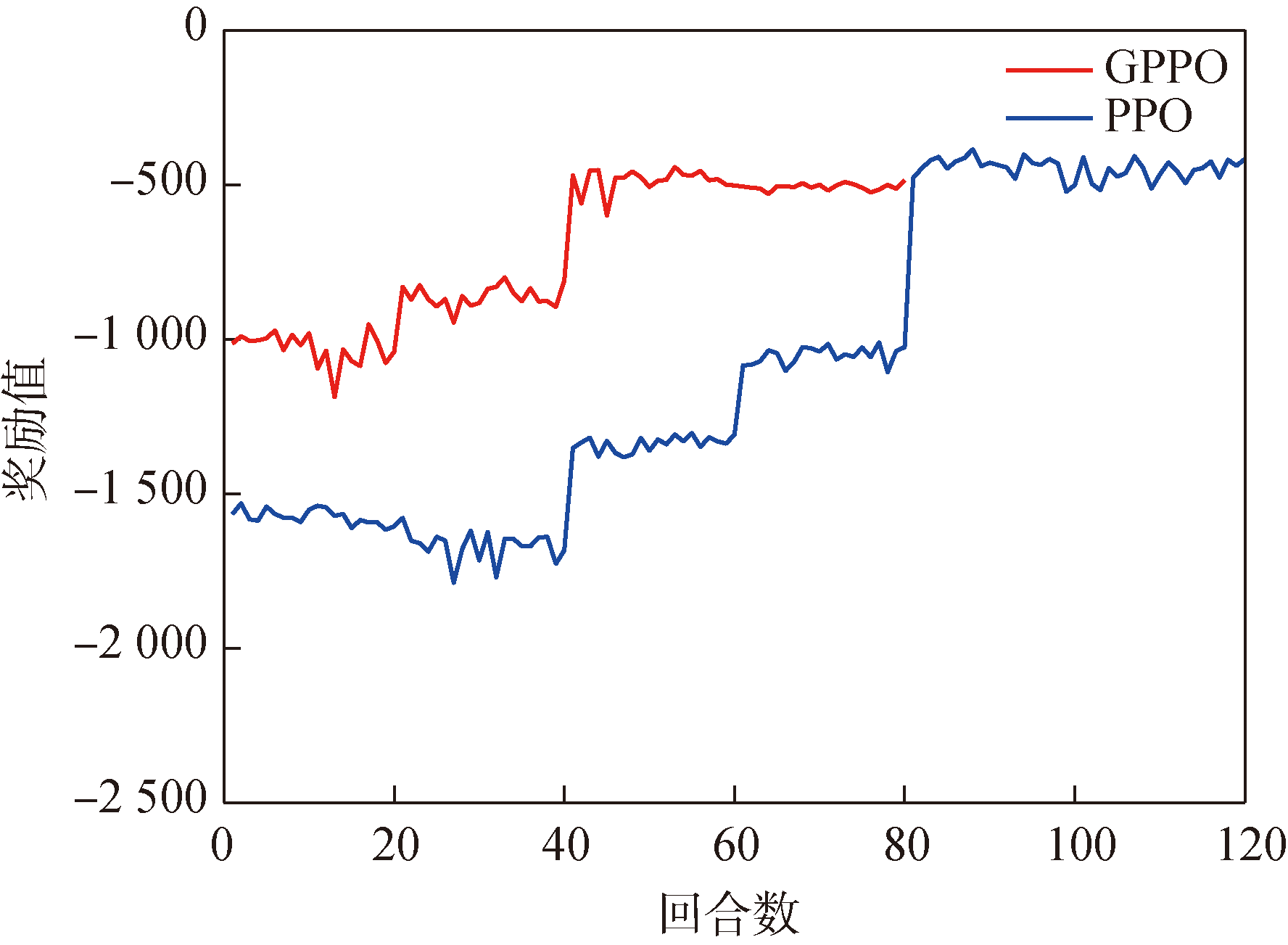
图23 场景一协同制导网络奖励曲线
Fig.23 Cooperative guidance network reward in Scenario 1

图24 场景一导弹运动轨迹
Fig.24 Missile trajectory in Scenario 1
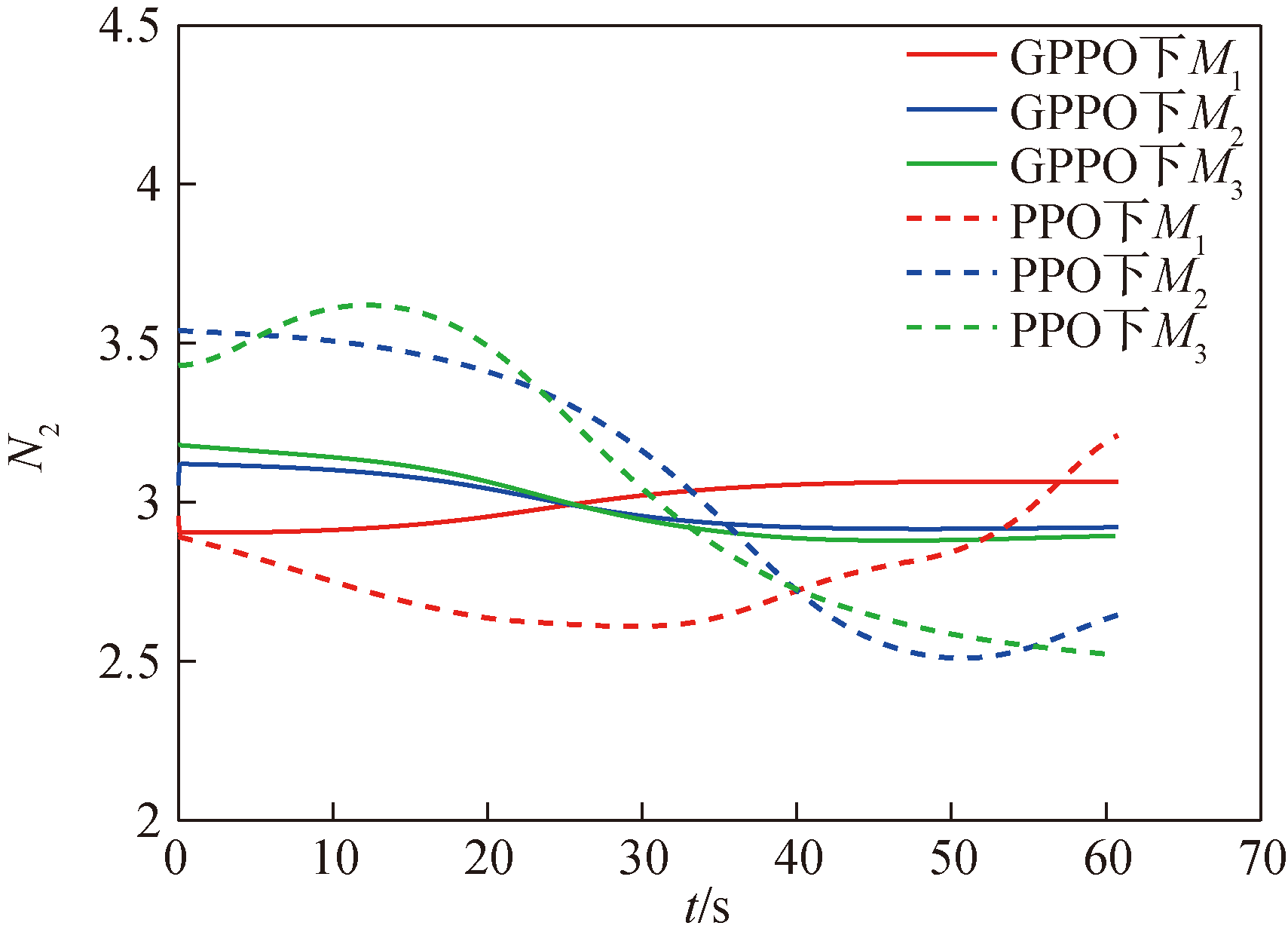
图25 场景一导弹的导引系数变化曲线
Fig.25 Variation curves of missile guidance coefficients in Scenario 1
| 参数 | 平均值 | 标准差 |
|---|---|---|
| 脱靶量/m | 4.28 | 0.78 |
| 攻击时间误差/s | 0.05 | 0.03 |
| 攻击角度/(°) | -65.02 | 0.07 |
| 训练回合数 | 59 | - |
表10 PPO2制导律性能参数
Table 10 Performance parameters of PPO2 guidance law
| 参数 | 平均值 | 标准差 |
|---|---|---|
| 脱靶量/m | 4.28 | 0.78 |
| 攻击时间误差/s | 0.05 | 0.03 |
| 攻击角度/(°) | -65.02 | 0.07 |
| 训练回合数 | 59 | - |
| 参数 | 数值 |
|---|---|
| 目标位置/m | (42000,0,3500) |
| 弹1弹道偏角/(°) | 2 |
| 弹2弹道偏角/(°) | -15 |
| 弹3弹道偏角/(°) | 10 |
| 期望攻击角度/(°) | -70 |
表11 场景二参数
Table 11 The parameters table of Scenario 2
| 参数 | 数值 |
|---|---|
| 目标位置/m | (42000,0,3500) |
| 弹1弹道偏角/(°) | 2 |
| 弹2弹道偏角/(°) | -15 |
| 弹3弹道偏角/(°) | 10 |
| 期望攻击角度/(°) | -70 |

图26 场景二导弹运动轨迹
Fig.26 Missile trajectory in Scenario 2
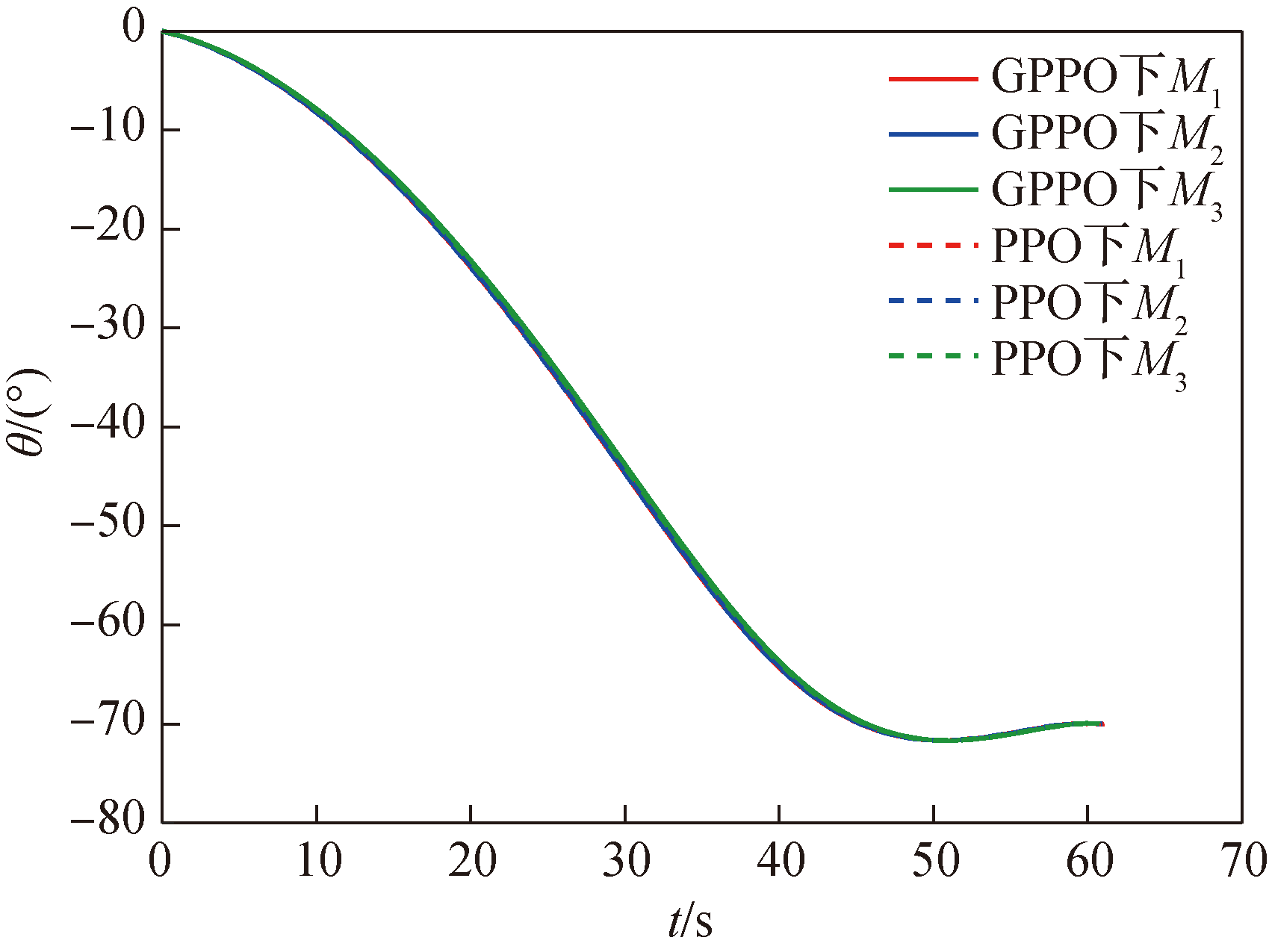
图27 场景二导弹弹道倾角θ随时间变化曲线
Fig.27 Missile trajectory inclination angle θ over time in Scenario 2
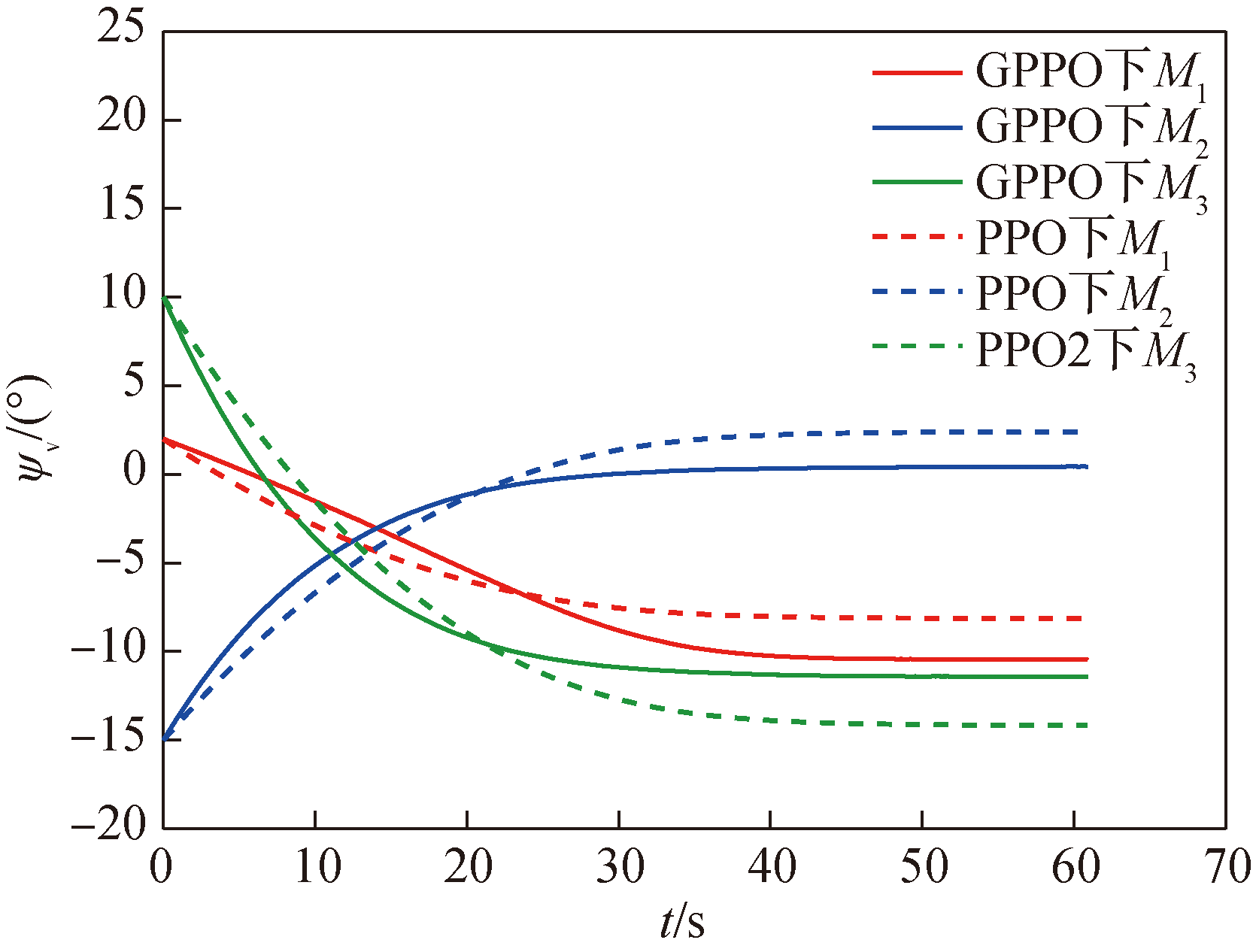
图28 场景二导弹弹道偏角ψV随时间变化曲线
Fig.28 Missile trajectory deviation angle ψV over time in Scenario 2
| [1] |
|
| [2] |
|
| [3] |
黎克波, 廖选平, 梁彦刚, 等. 基于纯比例导引的拦截碰撞角约束制导策略[J]. 航空学报, 2020, 41(增刊2):724277.
|
|
|
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
李国飞, 汤清璞, 吴云洁. 从飞行器无导引头的主-从式多飞行器协同制导方法[J]. 兵工学报, 2023, 44(11):3436-3446.
doi: 10.12382/bgxb.2023.0678 |
|
doi: 10.12382/bgxb.2023.0678 |
|
| [12] |
|
| [13] |
|
| [14] |
doi: 10.23919/JSEE.2021.000038 |
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
陈中原, 韦文书, 陈万春. 基于强化学习的多发导弹协同攻击智能制导律[J]. 兵工学报, 2021, 42(8):1638-1647.
|
|
|
|
| [20] |
李博皓, 安旭曼, 杨晓飞, 等. 攻击角度约束下的分布式强化学习制导方法[J]. 宇航学报, 2022, 43(8):1061-1069.
|
|
|
|
| [21] |
|
| [22] |
刘旭, 李响, 王晓鹏. 高超声速滑翔飞行器解析协同再入制导[J]. 宇航学报, 2023, 44(5):731-742.
|
|
|
|
| [23] |
高峰, 唐胜景, 师娇, 等. 一种基于落角约束的偏置比例导引律[J]. 北京理工大学学报, 2014, 34(3):277-282.
|
|
|
|
| [24] |
李东旭, 王晓芳, 林海. 多高超声速导弹协同末制导律及可行初始位置域研究[J]. 弹道学报, 2019, 31(4):1-7.
doi: 10.12115/j.issn.1004-499X(2019)04-001 |
|
doi: 10.12115/j.issn.1004-499X(2019)04-001 |
| [1] | 路潇然, 邹渊, 张旭东, 孙巍, 孟逸豪, 张彬. 基于Munchausen-PER算法优化的混合动力履带车辆能量管理策略[J]. 兵工学报, 2025, 46(6): 240498-. |
| [2] | 王江, 朱梓杨, 李虹言, 王鹏. 基于分布式凸优化的能量最优多向协同制导方法[J]. 兵工学报, 2025, 46(6): 240739-. |
| [3] | 周桢林, 龙腾, 刘大卫, 孙景亮, 钟建鑫, 李俊志. 基于强化学习冲突消解的大规模无人机集群航迹规划方法[J]. 兵工学报, 2025, 46(5): 241146-. |
| [4] | 先苏杰, 王康, 曾鑫, 宋杰, 吴志林. 基于深度强化学习的落角和视场角约束制导律[J]. 兵工学报, 2025, 46(4): 240435-. |
| [5] | 潘云伟, 李敏, 曾祥光, 黄傲, 张加衡, 任文哲, 彭倍. 基于人工势场和改进强化学习的自主式水下潜航器避障和航迹规划[J]. 兵工学报, 2025, 46(4): 240300-. |
| [6] | 李传浩, 明振军, 王国新, 阎艳, 丁伟, 万斯来, 丁涛. 基于多智能体深度强化学习的无人平台箔条干扰末端防御动态决策方法[J]. 兵工学报, 2025, 46(3): 240251-. |
| [7] | 张旺, 邵学辉, 唐慧龙, 魏建林, 王伟. 一种探索率自适应设置的强化学习雷达干扰决策方法[J]. 兵工学报, 2025, 46(3): 240357-. |
| [8] | 肖柳骏, 李雅轩, 刘新福. 基于强化学习的高超声速滑翔飞行器自适应末制导[J]. 兵工学报, 2025, 46(2): 240222-. |
| [9] | 胡砚洋, 何凡, 白成超. 高超声速飞行器末制导段协同避障决策方法[J]. 兵工学报, 2024, 45(9): 3147-3160. |
| [10] | 孙浩, 黎海青, 梁彦, 马超雄, 吴翰. 基于知识辅助深度强化学习的巡飞弹组动态突防决策[J]. 兵工学报, 2024, 45(9): 3161-3176. |
| [11] | 陈文杰, 崔小红, 王斌锐. 安全最优跟踪控制算法与机械手仿真[J]. 兵工学报, 2024, 45(8): 2688-2697. |
| [12] | 于航, 李清玉, 戴可人, 李豪杰, 邹尧, 张合. 三维自适应固定时间多导弹协同制导律[J]. 兵工学报, 2024, 45(8): 2646-2657. |
| [13] | 张堃, 华帅, 袁斌林, 李阳. 多平台网络化制导交接技术[J]. 兵工学报, 2024, 45(7): 2171-2181. |
| [14] | 王霄龙, 陈洋, 胡棉, 李旭东. 基于改进深度Q网络的机器人持续监测路径规划[J]. 兵工学报, 2024, 45(6): 1813-1823. |
| [15] | 罗雨雨, 丁伟, 明振军, 李传浩, 王国新, 阎艳, 王玉茜. 面向OODA作战流程的防空火力网端对端智能构建算法[J]. 兵工学报, 2024, 45(12): 4231-4245. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
 京公网安备11010802024360号 京ICP备05059581号-4
京公网安备11010802024360号 京ICP备05059581号-4