
Responsible Institution: China Association for Science and Technology
Sponsor: China Ordnance Society
ISSN 1000-1093 CN 11-2176/TJ
Sponsor: China Ordnance Society
ISSN 1000-1093 CN 11-2176/TJ
Acta Armamentarii ›› 2023, Vol. 44 ›› Issue (S2): 101-113.doi: 10.12382/bgxb.2023.0881
Special Issue: 群体协同与自主技术
Previous Articles Next Articles
LI Song1, MA Zhuangzhuang1, ZHANG Yunlin1, SHAO Jinliang1,2,3,*( )
)
Received:2023-09-06
Online:2024-01-10
Contact:
SHAO Jinliang
CLC Number:
LI Song, MA Zhuangzhuang, ZHANG Yunlin, SHAO Jinliang. Multi-agent Coverage Path Planning Based on Security Reinforcement Learning[J]. Acta Armamentarii, 2023, 44(S2): 101-113.
Add to citation manager EndNote|Ris|BibTeX
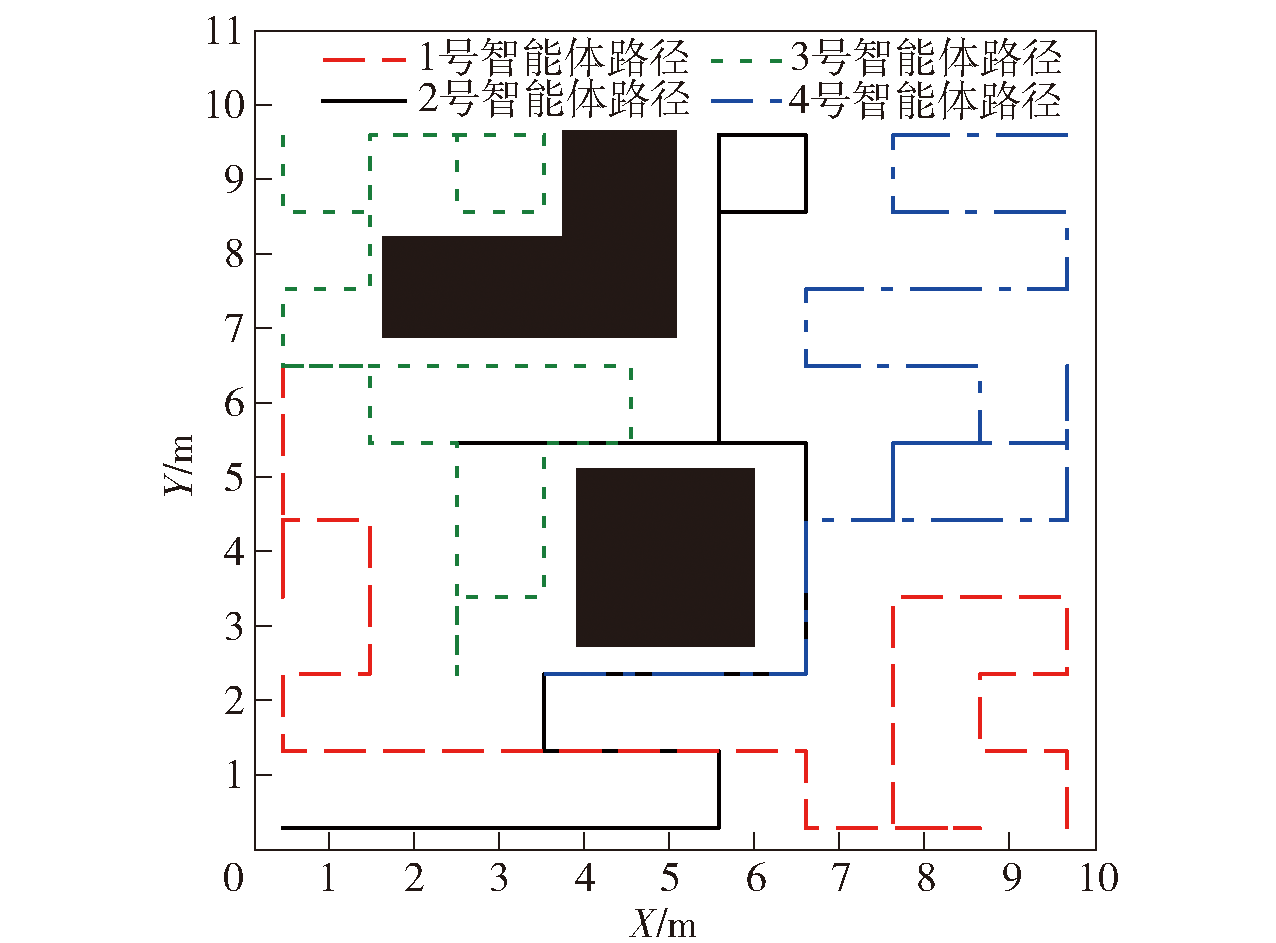
Fig.1 Schematic diagram of multi-agent coverage path

Fig.2 Schematic diagram of rasterization

Fig.3 Framework of VDN algorithm
| 算法1 安全约束模块 |
| 1:收集t时刻智能体i的状态 和预执行动作 2:预测t+1时刻智能体状态 3:if 出界or碰撞do 4: =stop, =-c,c∈R+ 5:else 6: = 7: 执行动作 ,观测奖励 和 8:end if |
| 算法1 安全约束模块 |
| 1:收集t时刻智能体i的状态 和预执行动作 2:预测t+1时刻智能体状态 3:if 出界or碰撞do 4: =stop, =-c,c∈R+ 5:else 6: = 7: 执行动作 ,观测奖励 和 8:end if |

Fig.4 Recurrent neural network structure
| 算法2 ε-贪婪法方法 |
| 1:获取当前轮数episode,随机数rand 2:ε= ×episode+εmin 3:if rand≥ε do 4: =random(A) 5:else 6: =arg ( (st), ) 7:end if |
| 算法2 ε-贪婪法方法 |
| 1:获取当前轮数episode,随机数rand 2:ε= ×episode+εmin 3:if rand≥ε do 4: =random(A) 5:else 6: =arg ( (st), ) 7:end if |
| 算法3 策略网络训练 |
| 1:随机初始化网络 … 参数θ1…θn 2:for episode=1,2,…,episodemax do 3: reset环境, ←0 4: for step=1,2,…,stepmax do 5: for i=1,2,…,N do 6: 根据算法2获取预执行动作 7: 收集 ,根据算法1获取有效样本 8: 更新网络 参数θi 9: end for 10: end for 11: if mean( )≥goalth do 12: break 13: end if 14:end for |
| 算法3 策略网络训练 |
| 1:随机初始化网络 … 参数θ1…θn 2:for episode=1,2,…,episodemax do 3: reset环境, ←0 4: for step=1,2,…,stepmax do 5: for i=1,2,…,N do 6: 根据算法2获取预执行动作 7: 收集 ,根据算法1获取有效样本 8: 更新网络 参数θi 9: end for 10: end for 11: if mean( )≥goalth do 12: break 13: end if 14:end for |
| 超参数 | 值 |
|---|---|
| 网络学习率 | 0.001 |
| 单隐藏层神经元数 | 64 |
| 折扣因子 | 0.99 |
| 网络更新间隔/轮 | 20 |
| 最小贪婪系数 | 0.05 |
| 最大贪婪系数 | 0.95 |
| 到达最大贪婪系数轮数 | 2000 |
| 最大运行轮数 | 2000 |
| 奖励阈值 | 4500 |
| 地图尺寸 | 10 |
| 平均分栈容量 | 100 |
| 最大运行步数 | 30/120 |
| 智能体数量 | 4/1 |
Table 1 Hyperparameters used in experiments
| 超参数 | 值 |
|---|---|
| 网络学习率 | 0.001 |
| 单隐藏层神经元数 | 64 |
| 折扣因子 | 0.99 |
| 网络更新间隔/轮 | 20 |
| 最小贪婪系数 | 0.05 |
| 最大贪婪系数 | 0.95 |
| 到达最大贪婪系数轮数 | 2000 |
| 最大运行轮数 | 2000 |
| 奖励阈值 | 4500 |
| 地图尺寸 | 10 |
| 平均分栈容量 | 100 |
| 最大运行步数 | 30/120 |
| 智能体数量 | 4/1 |

Fig.5 Comparison chart of reward curves
| 算法 | 覆盖率/% | 重复率/% |
|---|---|---|
| VDN_safe | 100.0 | 28.1 |
| center_safe | 93.8 | 35.4 |
| singal_safe | 99.0 | 24.0 |
| VDN_unsafe | 99.0 | 30.2 |
| center_unsafe | 89.5 | 39.5 |
| singal_unsafe | 95.8 | 29.1 |
Table 2 Comparison of algorithm overlay performances
| 算法 | 覆盖率/% | 重复率/% |
|---|---|---|
| VDN_safe | 100.0 | 28.1 |
| center_safe | 93.8 | 35.4 |
| singal_safe | 99.0 | 24.0 |
| VDN_unsafe | 99.0 | 30.2 |
| center_unsafe | 89.5 | 39.5 |
| singal_unsafe | 95.8 | 29.1 |

Fig.6 Coverage path curves for each algorithm
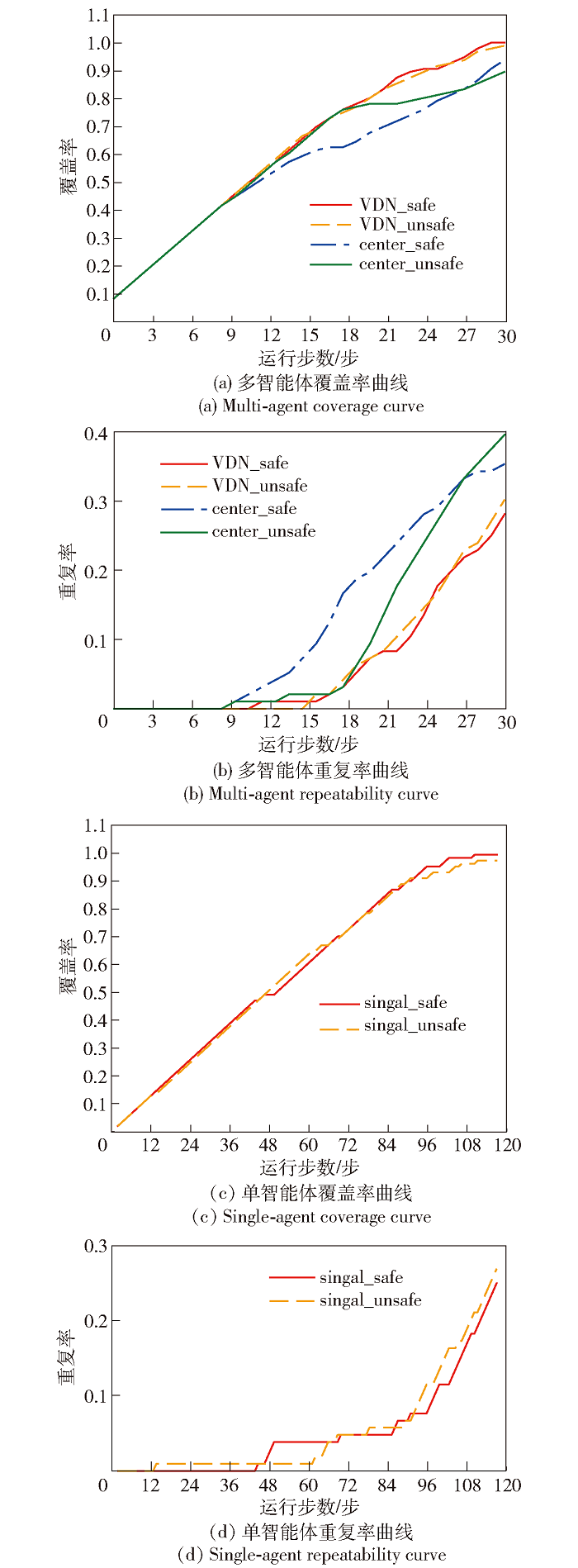
Fig.7 Coverage efficiency comparison chart

Fig.8 Comparison chart of reward curves with and without security constraints

Fig.9 Comparison of coverage paths with and without safety constraints in a map with tight spaces

Fig.10 Coverage path curve after changing the number and position of obstacles

Fig.11 Coverage path curve after expanding the area

Fig.12 Coverage path curve after expanding the area and increasing the obstacle
| 实验 | 覆盖率/% | 重复率/% |
|---|---|---|
| 10×10单障碍物 | 100.0 | 28.1 |
| 10×10多障碍物 | 100.0 | 32.6 |
| 20×20单障碍物 | 99.5 | 22.0 |
| 20×20多障碍物 | 98.9 | 22.9 |
Table 3 Results of the comparative experiments
| 实验 | 覆盖率/% | 重复率/% |
|---|---|---|
| 10×10单障碍物 | 100.0 | 28.1 |
| 10×10多障碍物 | 100.0 | 32.6 |
| 20×20单障碍物 | 99.5 | 22.0 |
| 20×20多障碍物 | 98.9 | 22.9 |
| 智能体个数 | 覆盖率/% | 重复率/% |
|---|---|---|
| 3 | 97.9 | 26.5 |
| 4 | 98.9 | 22.9 |
| 5 | 98.9 | 24.2 |
| 6 | 99.2 | 25.5 |
Table 4 Coverage performances of different number of agents
| 智能体个数 | 覆盖率/% | 重复率/% |
|---|---|---|
| 3 | 97.9 | 26.5 |
| 4 | 98.9 | 22.9 |
| 5 | 98.9 | 24.2 |
| 6 | 99.2 | 25.5 |

Fig.13 Schematic diagram of semi-physical platform frame

Fig.14 Controller structure

Fig.15 Schematic diagram of semi-physical simulation

Fig.16 Comparison chart of planning path and actual path of unmanned ground vehicle
| [1] |
doi: 10.1109/ACCESS.2021.3108177 URL |
| [2] |
李波, 杨志鹏, 贾卓然, 等. 一种无监督学习型神经网络的无人机全区域侦察路径规划[J]. 西北工业大学学报, 2021, 39(1):77-84.
|
|
doi: 10.1051/jnwpu/20213910077 URL |
|
| [3] |
吴文超, 黄长强, 宋磊, 等. 不确定环境下的多无人机协同搜索航路规划[J]. 兵工学报, 2011, 32(11): 1337-1342.
|
|
|
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
李御驰, 闫军涛, 宋志华, 等. 基于遗传算法的无人机监视覆盖航路规划算法研究[J]. 计算机科学与应用, 2019, 9(6): 1208-1215.
|
|
doi: 10.12677/CSA.2019.96135 URL |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
张伟, 王乃新, 魏世琳, 等. 水下无人潜航器集群发展现状及关键技术综述[J]. 哈尔滨工程大学学报, 2020, 41(2): 289-297.
|
|
|
|
| [17] |
罗志远, 刘小峰, 陈俊风, 等. 一种基于分步遗传算法的多无人清洁车区域覆盖路径规划方法[J]. 电子测量与仪器学报, 2020, 34(8):43-50.
|
|
|
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
王雪松, 王荣荣, 程玉虎. 安全强化学习综述[J]. 自动化学报, 2023, 49(9): 1813-1835.
|
|
|
|
| [22] |
doi: 10.1017/S0269888912000057 URL |
| [23] |
|
| [24] |
|
| [1] | ZHANG Jixiong, LI Zonggang, NING Xiaogang, CHEN Yinjuan. Fully Distributed Consensus Control of General Linear Multi-agent System Based on Dynamic Event-trigger [J]. Acta Armamentarii, 2023, 44(S2): 223-234. |
| [2] | YU Di, WANG Yajie, ZHAO Bo, LIU Qiong. Fixed-Time Tracking Control of Multi-agent Systems under Dynamic Event-Triggering Mechanism [J]. Acta Armamentarii, 2023, 44(5): 1403-1413. |
| [3] | KONG Guojie, FENG Shi, YU Huilong, JU Zhiyang, GONG Jianwei. A Review on Cooperative Motion Planning of Unmanned Vehicles [J]. Acta Armamentarii, 2023, 44(1): 11-26. |
| [4] | CAO Hao-zhe, WU Yan-xuan, ZHOU Feng, WANG Zheng-jie. Research on Containment Control of Second-order Nonlinear Multi-agent with Collision Avoidance Mechanism [J]. Acta Armamentarii, 2016, 37(9): 1646-1654. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||