
主管单位:中国科学技术协会
主办单位:中国兵工学会
ISSN 1000-1093 CN 11-2176/TJ
主办单位:中国兵工学会
ISSN 1000-1093 CN 11-2176/TJ
兵工学报 ›› 2025, Vol. 46 ›› Issue (4): 240435-.doi: 10.12382/bgxb.2024.0435
• • 上一篇
先苏杰, 王康, 曾鑫, 宋杰*( ), 吴志林**()
), 吴志林**()
收稿日期:2024-06-05
上线日期:2025-04-30
通讯作者:
XIAN Sujie, WANG Kang, ZENG Xin, SONG Jie*(), WU Zhilin**()
Received:2024-06-05
Online:2025-04-30
摘要:
为满足日益复杂的作战需求,提升微型制导弹药在近距离下的制导性能,基于深度强化学习(Deep Reinforcement Learning,DRL)提出一种考虑视场角极限的落角约束制导律。推导导弹相对移动目标的落角误差估计公式,以落角误差和视角为状态量并构造分段奖励函数,将制导问题建模为时间离散的马尔科夫决策过程。通过偏置比例导引获得所需制导指令,并由DRL的策略网络输出其偏置项,通过近端策略优化算法对网络进行训练,得到最优制导策略,实现在无弹目距离信息下对视角和落角的约束。在不同视场角限制、期望落角、目标速度、初始位置和导弹速度下进行数值模拟和蒙特卡洛仿真,并对导弹在不同速度下的捕获区域进行对比分析。研究结果表明,所提制导律在不同初始条件下均能保持良好的制导性能,在近距离打击中相比现有制导律具有更大的捕获区域,在干扰作用下具有更小的落角误差分布,从而验证了该制导律的有效性与优越性。
中图分类号:
先苏杰, 王康, 曾鑫, 宋杰, 吴志林. 基于深度强化学习的落角和视场角约束制导律[J]. 兵工学报, 2025, 46(4): 240435-.
XIAN Sujie, WANG Kang, ZENG Xin, SONG Jie, WU Zhilin. An Impact Angle and Field of View Constraints Guidance Law Based on Deep Reinforcement Learning[J]. Acta Armamentarii, 2025, 46(4): 240435-.
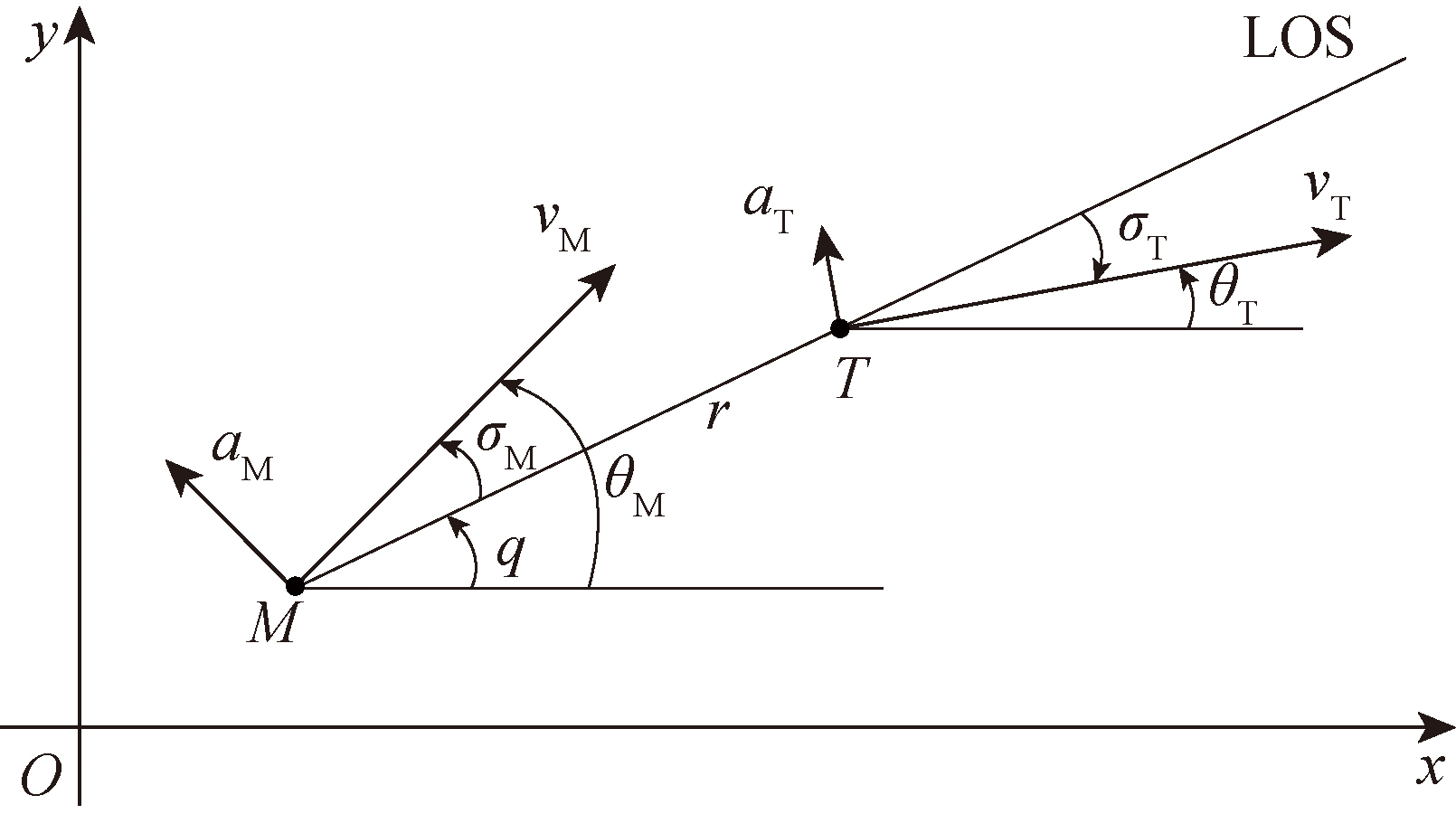
图1 交战几何
Fig.1 Engagement geometry
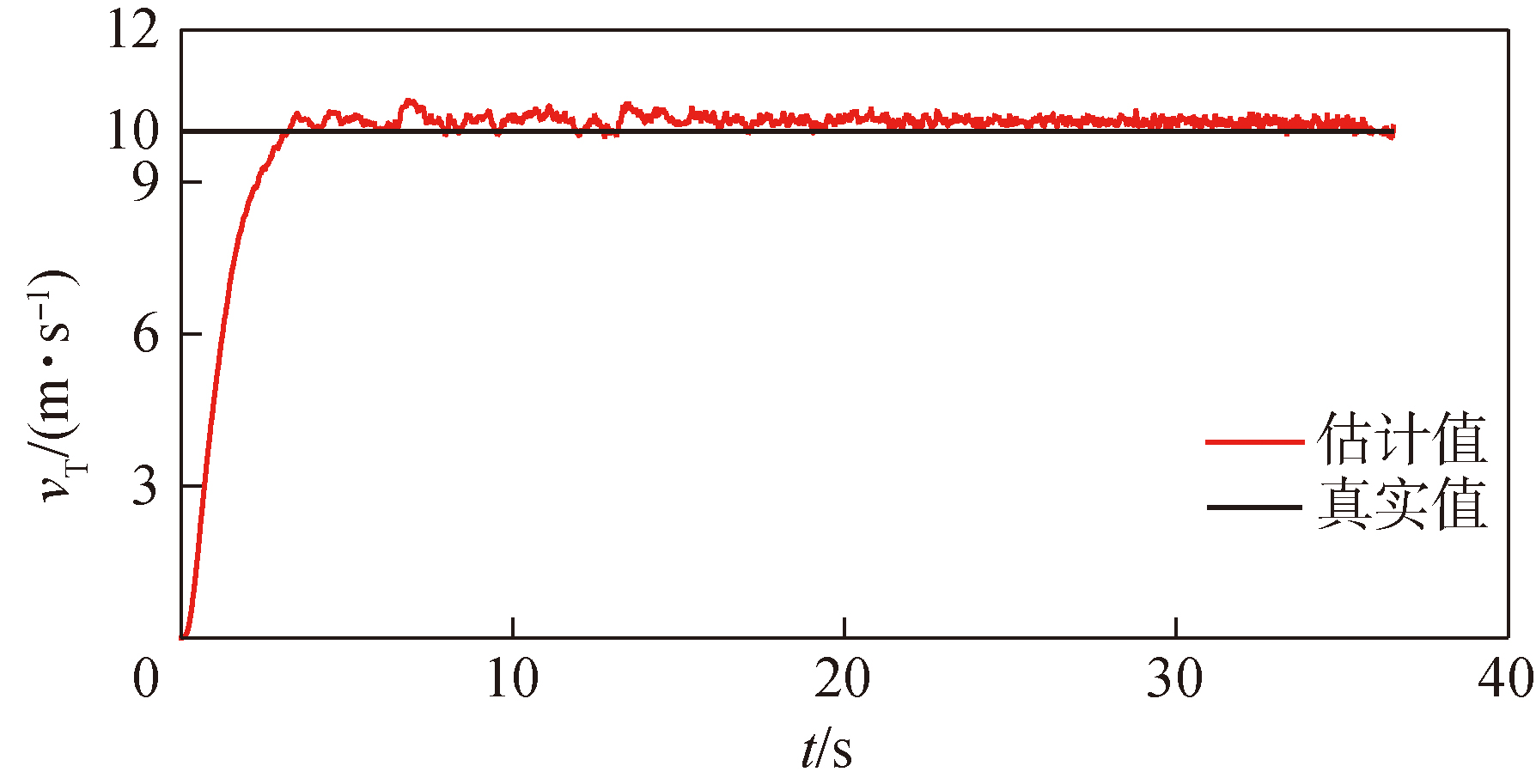
图2 vT估计的仿真结果
Fig.2 The estimated result of vT
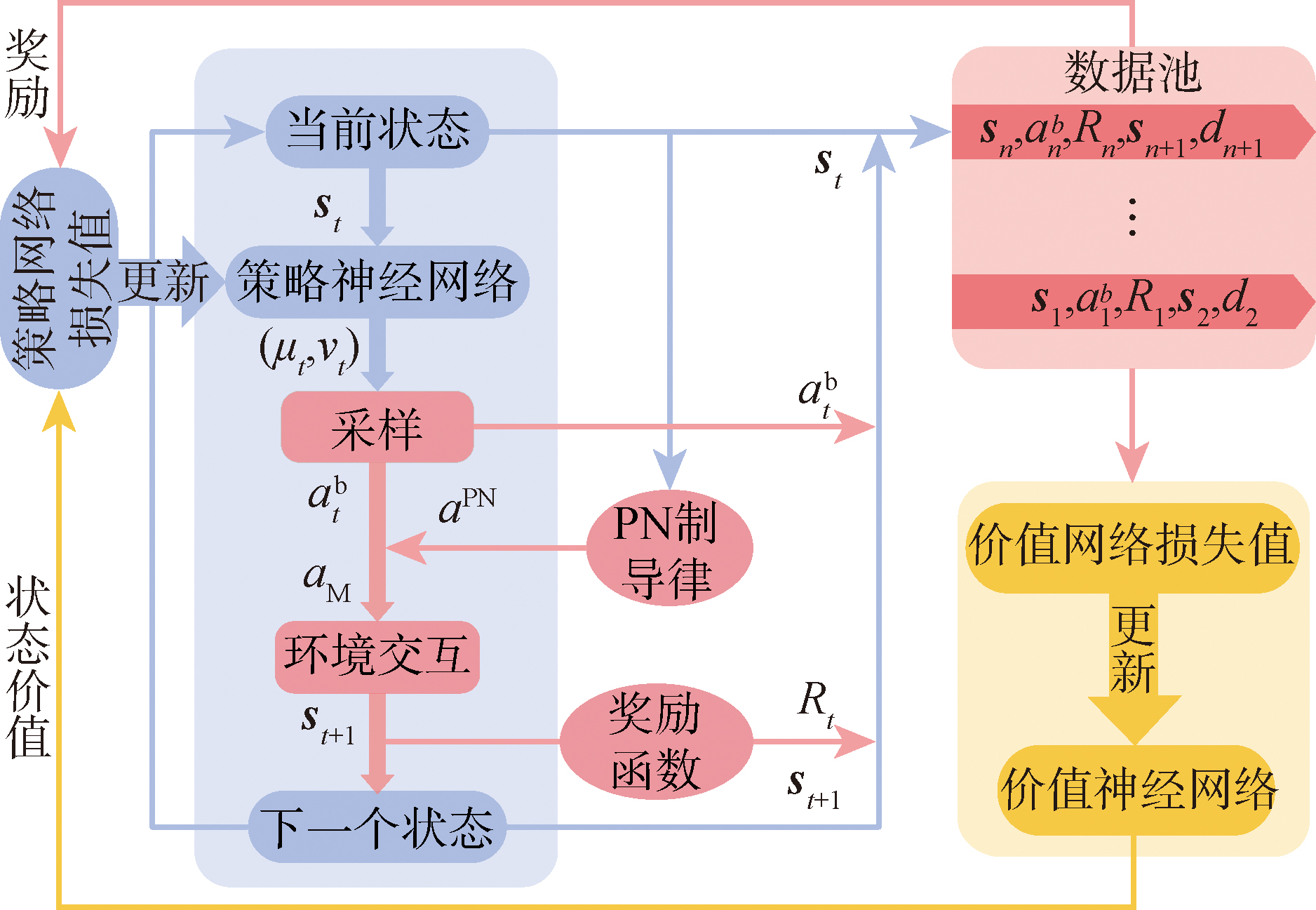
图3 制导律训练算法的结构示意图
Fig.3 Structural diagram of guidance law training algorithm

图4 视场角约束下基于PPO的落角控制制导律训练算法
Fig.4 PPO-based guidance law training algorithm for impact angle control with FOV angle constraints
| 神经网络 | 结构 | 激活函数 |
|---|---|---|
| Actor | (2,64) | ReLU |
| (64,128) | ReLU | |
| (128,64) | ReLU | |
| (64,1),(64,1) | Tanh,Sigmoid | |
| Critic | (2,64) | ReLU |
| (64,256) | ReLU | |
| (256,64) | ReLU | |
| (64,32) | ReLU | |
| (32,16) | ReLU | |
| (16,1) | Linner |
表1 神经网络架构
Table 1 Neural network architecture
| 神经网络 | 结构 | 激活函数 |
|---|---|---|
| Actor | (2,64) | ReLU |
| (64,128) | ReLU | |
| (128,64) | ReLU | |
| (64,1),(64,1) | Tanh,Sigmoid | |
| Critic | (2,64) | ReLU |
| (64,256) | ReLU | |
| (256,64) | ReLU | |
| (64,32) | ReLU | |
| (32,16) | ReLU | |
| (16,1) | Linner |
| 参数 | 取值 |
|---|---|
| N | 3 |
| vM/(m·s-1) | 100 |
| vT/(m·s-1) | 10 |
| abn/(m· ) | 30 |
| 0.5eθ0 | |
| /(°) | 10 |
| q0/(°) | 0 |
| σM0/(°) | 15 |
| θM0/(°) | 15 |
| n | 32 |
| αϑ | 0.00001 |
| αφ | 0.0001 |
| k1 | 0.25 |
| γ | 0.95 |
| λGAE | 0.95 |
| ε | 0.2 |
| K | 10 |
| dt/s | 0.01 |
| Δt/s | 0.02 |
| 训练回合总数 | 2000 |
表2 参数设置
Table 2 Parameter settings
| 参数 | 取值 |
|---|---|
| N | 3 |
| vM/(m·s-1) | 100 |
| vT/(m·s-1) | 10 |
| abn/(m· ) | 30 |
| 0.5eθ0 | |
| /(°) | 10 |
| q0/(°) | 0 |
| σM0/(°) | 15 |
| θM0/(°) | 15 |
| n | 32 |
| αϑ | 0.00001 |
| αφ | 0.0001 |
| k1 | 0.25 |
| γ | 0.95 |
| λGAE | 0.95 |
| ε | 0.2 |
| K | 10 |
| dt/s | 0.01 |
| Δt/s | 0.02 |
| 训练回合总数 | 2000 |
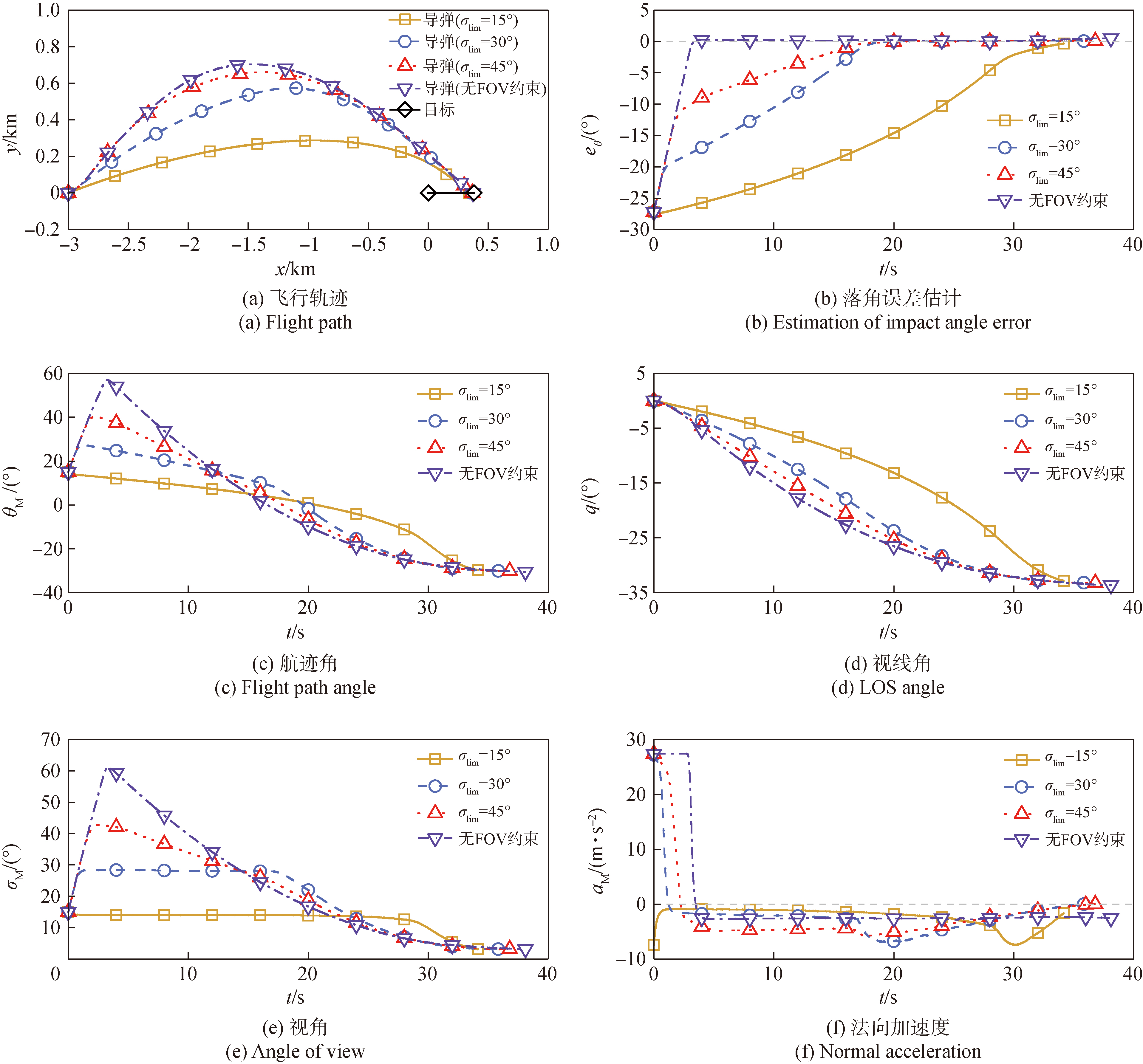
图5 不同σlim下的数值仿真
Fig.5 Numerically simulated results for variousσlim
| σlim/(°) | σsat/(°) | 终端θM/(°) | 最大σM/° | dt |
|---|---|---|---|---|
| 15 | 14.0 | -29.98 | 15.00 | 78.52 |
| 30 | 28.5 | -29.84 | 28.18 | 120.34 |
| 45 | 43.5 | -30.00 | 41.86 | 163.13 |
| 无限制 | -30.45 | 61.01 | 174.77 |
表3 不同σlim下的仿真结果
Table 3 Simulated results under differentσlimconditions
| σlim/(°) | σsat/(°) | 终端θM/(°) | 最大σM/° | dt |
|---|---|---|---|---|
| 15 | 14.0 | -29.98 | 15.00 | 78.52 |
| 30 | 28.5 | -29.84 | 28.18 | 120.34 |
| 45 | 43.5 | -30.00 | 41.86 | 163.13 |
| 无限制 | -30.45 | 61.01 | 174.77 |

图6 不同θexp下的数值仿真
Fig.6 Numerically simulated results for various θexp
| θexp/(°) | 终端θM/(°) | 最大σM/(°) | dt |
|---|---|---|---|
| -30 | -29.84 | 28.18 | 120.34 |
| -45 | -44.87 | 28.42 | 147.76 |
| -60 | -59.91 | 28.60 | 174.48 |
| -75 | -74.53 | 28.69 | 200.26 |
表4 不同θexp下的仿真结果
Table 4 Simulation results under different θexp
| θexp/(°) | 终端θM/(°) | 最大σM/(°) | dt |
|---|---|---|---|
| -30 | -29.84 | 28.18 | 120.34 |
| -45 | -44.87 | 28.42 | 147.76 |
| -60 | -59.91 | 28.60 | 174.48 |
| -75 | -74.53 | 28.69 | 200.26 |
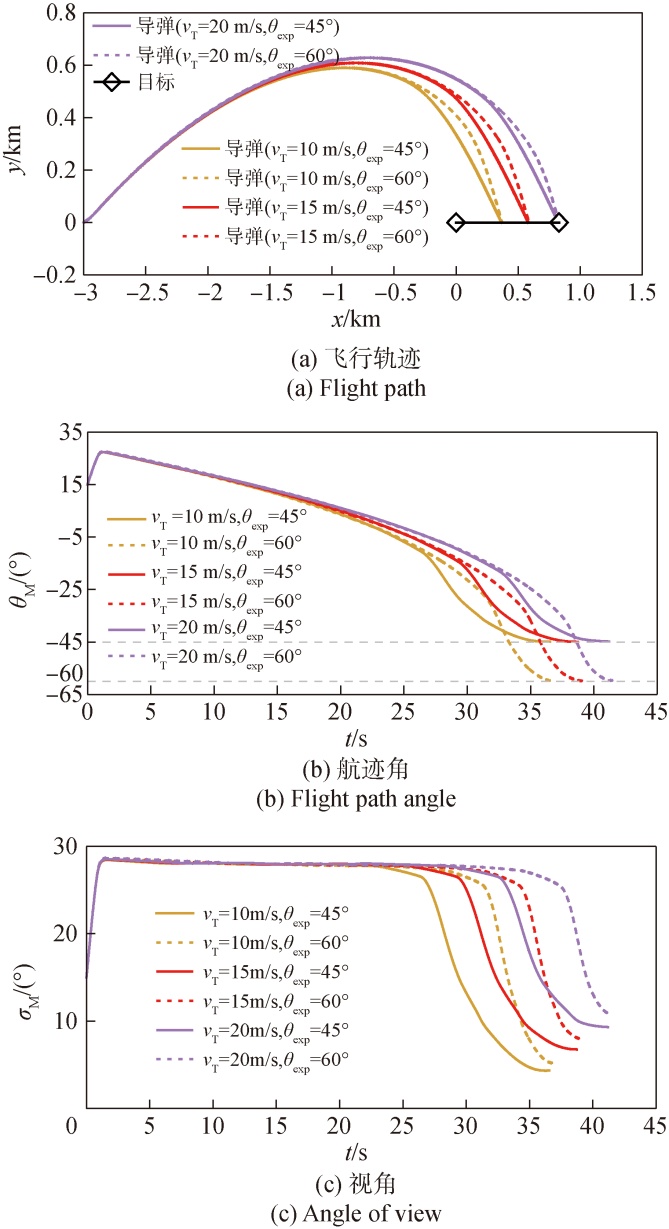
图7 不同vT下的数值仿真
Fig.7 Numerically simulated results for variousvT

图8 RLIACG、IACCG与D-RLIACG的捕获区域
Fig.8 The capture regions of RLIACG,IACCG and D-RLIACG
| vM/(m·s-1) | RLIACG | IACCG | D-RLIACG |
|---|---|---|---|
| 100 | 88.89 | 68.15 | 65.56 |
| 150 | 71.85 | 38.15 | 57.78 |
| 200 | 47.04 | 21.11 | 39.63 |
表5 不同vM下RLIACG与D-RLIACG、 IACCG的捕获率
Table 5 Capture rates of RLIACG,D-RLIACG and IACCG for variousvM %
| vM/(m·s-1) | RLIACG | IACCG | D-RLIACG |
|---|---|---|---|
| 100 | 88.89 | 68.15 | 65.56 |
| 150 | 71.85 | 38.15 | 57.78 |
| 200 | 47.04 | 21.11 | 39.63 |

图9 RLIACG与IACCG的蒙特卡洛仿真对比
Fig.9 Comparison of Monte Carlo simulations of RLIACG and IACCG
| 统计量 | 脱靶量/m | 落角误差/(°) | ||||
|---|---|---|---|---|---|---|
| RLIACG | IACCG | D-RLIACG | RLIACG | IACCG | D-RLIACG | |
| 均值 | 0.24 | 0.26 | 1.15 | 0.22 | 0.91 | 0.47 |
| 标准差 | 0.19 | 0.19 | 0.26 | 0.14 | 0.76 | 0.44 |
| 最大值 | 0.75 | 0.90 | 1.90 | 0.77 | 5.91 | 4.30 |
表6 RLIACG与IACCG、D-RLIACG的误差分布
Table 6 Error distributions of RLIACG,IACCG and D-RLIACG
| 统计量 | 脱靶量/m | 落角误差/(°) | ||||
|---|---|---|---|---|---|---|
| RLIACG | IACCG | D-RLIACG | RLIACG | IACCG | D-RLIACG | |
| 均值 | 0.24 | 0.26 | 1.15 | 0.22 | 0.91 | 0.47 |
| 标准差 | 0.19 | 0.19 | 0.26 | 0.14 | 0.76 | 0.44 |
| 最大值 | 0.75 | 0.90 | 1.90 | 0.77 | 5.91 | 4.30 |
| 参数 | 数值 |
|---|---|
| Mα/s-2 | -423.6 |
| Mφ/s-1 | -0.07 |
| Mδ/s-2 | 331 |
| Zα/(m·s-2·rad-1) | -705 |
| Zδ/(m·s-2·rad-1) | -165 |
| KA/(rad·s·m-1) | 4.5×10-4 |
| KDC | 21.05 |
| KR/s | 0.34 |
| ωi/(rad·s-1) | 16.36 |
| Cx0 | 0.18 |
| /(rad-2) | 7.65 |
| Sm/m2 | 0.013 |
| τδ/s | 0.04 |
表7 动力学模型与控制器的相关参数
Table 7 Related parameters of dynamic models and controllers
| 参数 | 数值 |
|---|---|
| Mα/s-2 | -423.6 |
| Mφ/s-1 | -0.07 |
| Mδ/s-2 | 331 |
| Zα/(m·s-2·rad-1) | -705 |
| Zδ/(m·s-2·rad-1) | -165 |
| KA/(rad·s·m-1) | 4.5×10-4 |
| KDC | 21.05 |
| KR/s | 0.34 |
| ωi/(rad·s-1) | 16.36 |
| Cx0 | 0.18 |
| /(rad-2) | 7.65 |
| Sm/m2 | 0.013 |
| τδ/s | 0.04 |

图10 动力学仿真结果
Fig.10 Dynamic simulated results
| [1] |
黄景帅, 张洪波, 汤国建, 等. 拦截大气层内机动目标的自适应积分滑模制导律[J]. 宇航学报, 2019, 40(1):51-60.
|
|
|
|
| [2] |
|
| [3] |
盛永智, 甘佳豪, 张成新. 弹道可调的落角约束分数阶滑模制导律设计[J]. 航空学报, 2023, 44(7):177-190.
|
|
|
|
| [4] |
|
| [5] |
马帅, 王旭刚, 王中原, 等. 带初始前置角和末端攻击角约束的偏置比例导引律设计以及剩余飞行时间估计[J]. 兵工学报, 2019, 40(1):68-78.
doi: 10.3969/j.issn.1000-1093.2019.01.009 |
|
doi: 10.3969/j.issn.1000-1093.2019.01.009 |
|
| [6] |
王晓海, 孟秀云, 周峰, 等. 基于偏置比例导引的落角约束滑模制导律[J]. 系统工程与电子技术, 2021, 43(5):1295-1302.
doi: 10.12305/j.issn.1001-506X.2021.05.17 |
|
doi: 10.12305/j.issn.1001-506X.2021.05.17 |
|
| [7] |
严鹏辉, 刘刚, 缪前树. 基于落角约束的偏置比例导引律的研究[J]. 现代防御技术, 2021, 49(6):43-48,55.
doi: 10.3969/j.issn.1009-086x.2021.06.008 |
|
|
|
| [8] |
|
| [9] |
黄嘉, 常思江, 陈琦, 等. 不依赖剩余飞行时间的数据驱动攻击时间控制导引律[J]. 兵工学报, 2023, 44(8):2299-2309.
doi: 10.12382/bgxb.2022.0324 |
|
doi: 10.12382/bgxb.2022.0324 |
|
| [10] |
黄嘉, 常思江. 基于数据驱动的攻击时间和攻击角度控制导引律[J]. 系统工程与电子技术, 2022, 44(10):3213-3220.
doi: 10.12305/j.issn.1001-506X.2022.10.26 |
|
doi: 10.12305/j.issn.1001-506X.2022.10.26 |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
王江, 刘经纬, 崔晓曦, 等. 有限视场下的攻击时间和角度多约束制导律[J]. 北京理工大学学报, 2024, 44(1):18-27.
|
|
|
|
| [16] |
|
| [17] |
李彤, 孟志鹏, 吕良, 等. 微型导弹纵向扰动抑制控制系统设计[J]. 国防科技大学学报, 2021, 43(1):7-15.
|
|
|
|
| [18] |
|
| [19] |
|
| [20] |
梁晨, 王卫红, 赖超. 带攻击角度约束的深度强化元学习制导律[J]. 宇航学报, 2021, 42(5):611-620.
|
|
|
|
| [21] |
|
| [22] |
|
| [23] |
刘子超, 王江, 何绍溟, 等. 基于预测校正的落角约束计算制导方法[J]. 航空学报, 2022, 43(8):515-530.
|
|
|
|
| [24] |
李博皓, 安旭曼, 杨晓飞, 等. 攻击角度约束下的分布式强化学习制导方法[J]. 宇航学报, 2022, 43(8):1061-1069.
|
|
|
|
| [25] |
|
| [26] |
郑成辰. 基于深度强化学习的约束末制导律研究[D]. 成都: 四川大学,2023:9.
|
|
|
|
| [27] |
田嘉懿. 低成本全捷联微型导弹制导控制技术研究[D]. 长沙: 国防科学技术大学,2019:124.
|
|
|
| [1] | 孙浩, 黎海青, 梁彦, 马超雄, 吴翰. 基于知识辅助深度强化学习的巡飞弹组动态突防决策[J]. 兵工学报, 2024, 45(9): 3161-3176. |
| [2] | 吴浩, 李东光, 王泳安. 反舰导弹大前置角下三维剩余飞行时间估计方法[J]. 兵工学报, 2024, 45(5): 1449-1459. |
| [3] | 董明泽, 温庄磊, 陈锡爱, 杨炅坤, 曾涛. 安全凸空间与深度强化学习结合的机器人导航方法[J]. 兵工学报, 2024, 45(12): 4372-4382. |
| [4] | 傅妍芳, 雷凯麟, 魏佳宁, 曹子建, 杨博, 王炜, 孙泽龙, 李秦洁. 基于演员-评论家框架的层次化多智能体协同决策方法[J]. 兵工学报, 2024, 45(10): 3385-3396. |
| [5] | 杜宏宝, 王正杰, 唐礼喜, 张小宁. 基于控制障碍函数的飞行器避障与制导控制[J]. 兵工学报, 2023, 44(9): 2814-2823. |
| [6] | 周蒙, 钱惟贤, 任侃. 多约束超螺旋滑模变结构制导律[J]. 兵工学报, 2023, 44(3): 799-805. |
| [7] | 马也, 范文慧, 常天庆. 基于智能算法的无人集群防御作战方案优化方法[J]. 兵工学报, 2022, 43(6): 1415-1425. |
| [8] | 陈中原, 韦文书, 陈万春. 基于强化学习的多发导弹协同攻击智能制导律[J]. 兵工学报, 2021, 42(8): 1638-1647. |
| [9] | 张晚晴, 余文斌, 李静琳, 陈万春. 基于纵程解析解的飞行器智能横程机动再入协同制导[J]. 兵工学报, 2021, 42(7): 1400-1411. |
| [10] | 高昂, 董志明, 叶红兵, 宋敬华, 郭齐胜. 基于深度强化学习的巡飞弹突防控制决策[J]. 兵工学报, 2021, 42(5): 1101-1110. |
| [11] | 冯运铎, 吴炎烜, 曹昊哲. 一种分布式多无人机协同定距盘旋跟踪制导律[J]. 兵工学报, 2019, 40(10): 2060-2069. |
| [12] | 陈峰, 何广军. 抗多径干扰的有限时间收敛制导律[J]. 兵工学报, 2018, 39(9): 1741-1748. |
| [13] | 黄伟, 徐建城, 吴华兴, 李俊兵. 基于非数据通信的导弹编队制导律算法[J]. 兵工学报, 2018, 39(5): 910-918. |
| [14] | 郭琨, 杨树兴. 考虑导弹1阶驾驶仪的近似最小加速度峰值导引律[J]. 兵工学报, 2018, 39(1): 83-93. |
| [15] | 杨靖, 王旭刚, 王中原, 常思江. 考虑自动驾驶仪动态特性和攻击角约束的鲁棒末制导律[J]. 兵工学报, 2017, 38(5): 900-909. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
 京公网安备11010802024360号 京ICP备05059581号-4
京公网安备11010802024360号 京ICP备05059581号-4