
主管单位:中国科学技术协会
主办单位:中国兵工学会
ISSN 1000-1093 CN 11-2176/TJ
主办单位:中国兵工学会
ISSN 1000-1093 CN 11-2176/TJ
兵工学报 ›› 2024, Vol. 45 ›› Issue (10): 3631-3641.doi: 10.12382/bgxb.2023.0740
孙凯1, 张成1,*( ), 詹天1, 苏迪2
), 詹天1, 苏迪2
收稿日期:2023-08-10
上线日期:2023-10-19
通讯作者:
SUN Kai1, ZHANG Cheng1,*(), ZHAN Tian1, SU Di2
Received:2023-08-10
Online:2023-10-19
摘要:
针对现有多视图立体视觉(Multi-View Stereo, MVS)技术提取弱纹理区域和非郎伯体曲面特征信息不充分及重建效果不理想问题,提出一种融合注意力机制和多层动态形变卷积的AMDC-PatchmatchNet方法。构建一种融合坐标注意力的特征提取网络,能更准确地捕捉重建对象的边缘形状和纹理特征,同时融合一种基于动态形变卷积的自适应感受野模块,根据不同尺度的特征自适应调整感受野的大小和形状,获得兼具全局和细节的特征表示。在DTU数据集上的测试结果表明,所提方法相较于主流MVS方法,点云重建整体性指标提高2.8%,并且在航空影像数据集上验证了模型的泛化能力。
中图分类号:
孙凯, 张成, 詹天, 苏迪. 融合注意力机制和多层动态形变卷积的多视图立体视觉重建方法[J]. 兵工学报, 2024, 45(10): 3631-3641.
SUN Kai, ZHANG Cheng, ZHAN Tian, SU Di. Multi-view Stereo Vision Reconstruction Network with Fusion Attention Mechanism and Multi-layer Dynamic Deformable Convolution[J]. Acta Armamentarii, 2024, 45(10): 3631-3641.

图1 AMDC-PatchmatchNet的总体框架
Fig.1 Overall framework of AMDC-PatchmatchNet

图2 CAB结构
Fig.2 Coordinate attention block structure

图3 两种3×3卷积核不同的采样形式
Fig.3 Two different 3×3 sampling forms of convolutional kernel
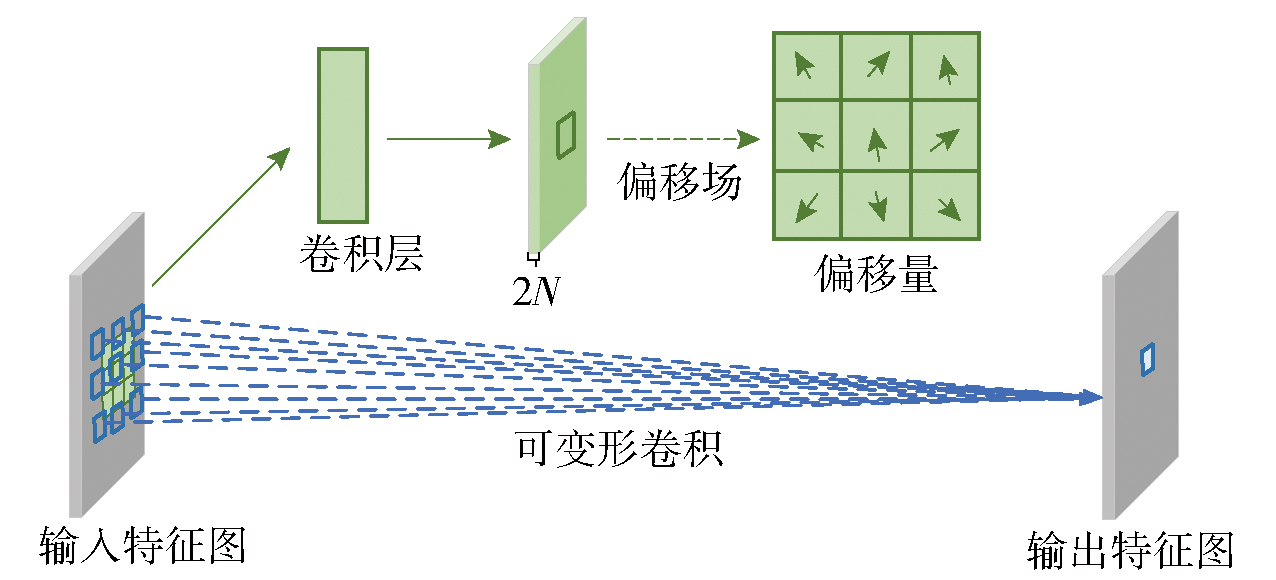
图4 可变形卷积特征的提取过程
Fig.4 Extraction process of deformable convolution feature

图5 基于DCN的ARFB结构
Fig.5 Structure diagram of DCN-based adaptive receptive field block
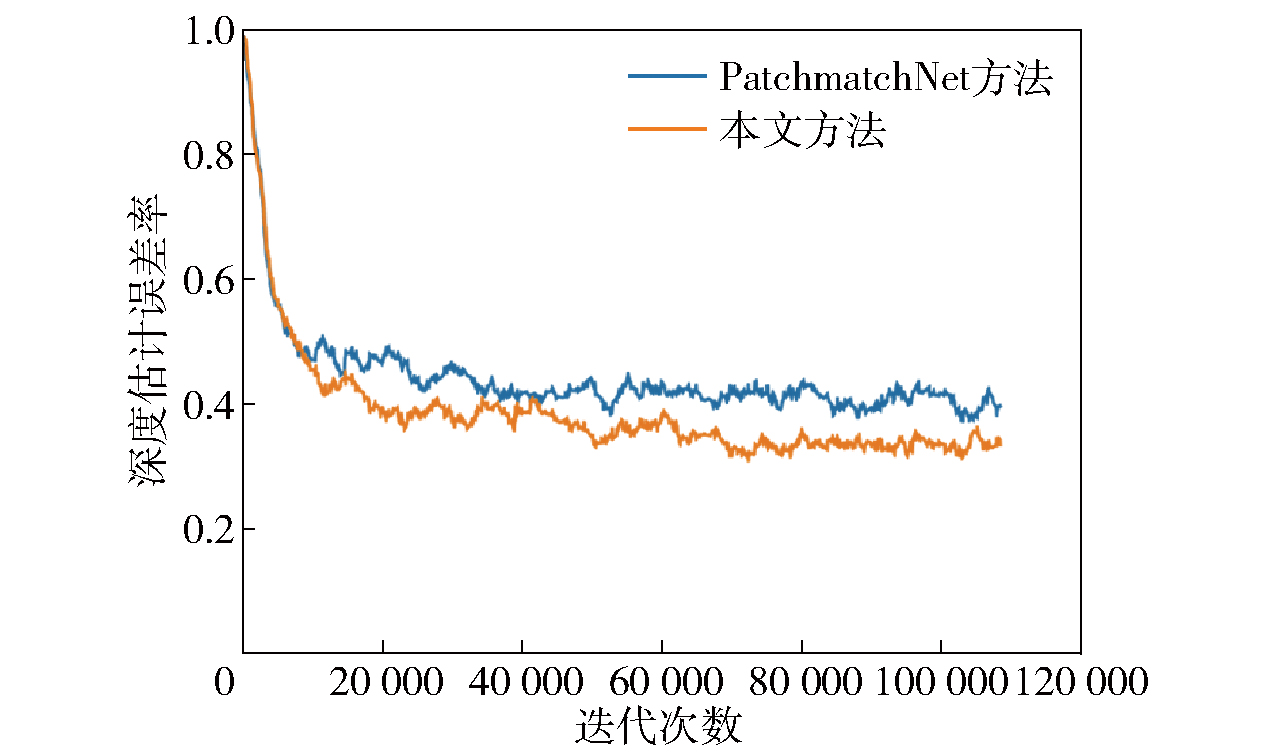
图6 绝对误差值大于1mm的深度估计误差率曲线图
Fig.6 Depth estimation error rate with absolute error value greater than 1mm
| 方法 | 准确性误 差/mm | 完整性误 差/mm | 整体性误 差/mm |
|---|---|---|---|
| Camp | 0.835 | 0.554 | 0.695 |
| Furu | 0.613 | 0.941 | 0.777 |
| Tola | 0.342 | 1.190 | 0.766 |
| Gipuma | 0.283 | 0.873 | 0.578 |
| Colmap | 0.532 | 0.400 | 0.664 |
| MVSNet | 0.396 | 0.527 | 0.462 |
| R-MVSNet | 0.383 | 0.452 | 0.417 |
| P-MVSNet | 0.406 | 0.434 | 0.420 |
| Fast-MVSNet | 0.336 | 0.403 | 0.370 |
| CVP-MVSNet | 0.296 | 0.406 | 0.351 |
| PatchmatchNet | 0.427 | 0.277 | 0.352 |
| 本文方法 | 0.406 | 0.279 | 0.342 |
表1 不同方法在DTU数据集上的定量测试结果
Table 1 Quantitative test results of different methods on DTU datasets
| 方法 | 准确性误 差/mm | 完整性误 差/mm | 整体性误 差/mm |
|---|---|---|---|
| Camp | 0.835 | 0.554 | 0.695 |
| Furu | 0.613 | 0.941 | 0.777 |
| Tola | 0.342 | 1.190 | 0.766 |
| Gipuma | 0.283 | 0.873 | 0.578 |
| Colmap | 0.532 | 0.400 | 0.664 |
| MVSNet | 0.396 | 0.527 | 0.462 |
| R-MVSNet | 0.383 | 0.452 | 0.417 |
| P-MVSNet | 0.406 | 0.434 | 0.420 |
| Fast-MVSNet | 0.336 | 0.403 | 0.370 |
| CVP-MVSNet | 0.296 | 0.406 | 0.351 |
| PatchmatchNet | 0.427 | 0.277 | 0.352 |
| 本文方法 | 0.406 | 0.279 | 0.342 |
| 方法 | 准确性误 差/mm | 完整性误 差/mm | 整体性 误差/mm | GPU内存 消耗/MB |
|---|---|---|---|---|
| 无CAB、无ARFB | 0.429 | 0.335 | 0.382 | 10 877 |
| 加入CAB、无ARFB | 0.420 | 0.304 | 0.362 | 10 885 |
| 无CAB、加入ARFB | 0.397 | 0.321 | 0.359 | 10 887 |
| 本文方法 | 0.406 | 0.279 | 0.342 | 10 885 |
表3 消融实验定量结果对比
Table 3 Comparison of quantitative results of ablation experiments
| 方法 | 准确性误 差/mm | 完整性误 差/mm | 整体性 误差/mm | GPU内存 消耗/MB |
|---|---|---|---|---|
| 无CAB、无ARFB | 0.429 | 0.335 | 0.382 | 10 877 |
| 加入CAB、无ARFB | 0.420 | 0.304 | 0.362 | 10 885 |
| 无CAB、加入ARFB | 0.397 | 0.321 | 0.359 | 10 887 |
| 本文方法 | 0.406 | 0.279 | 0.342 | 10 885 |

图7 输出深度图对比
Fig.7 Comparison of output depth maps

图8 航空影像数据集示例
Fig.8 Example of an aerial imagery dataset
| 方法 | 平均距离 | 标准差 |
|---|---|---|
| PatchmatchNet方法 | 0.127894 | 0.0891436 |
| 本文方法 | 0.103431 | 0.0813845 |
表5 泛化能力实验定量结果对比
Table 5 Comparison of quantitative results of generalization ability experiments
| 方法 | 平均距离 | 标准差 |
|---|---|---|
| PatchmatchNet方法 | 0.127894 | 0.0891436 |
| 本文方法 | 0.103431 | 0.0813845 |
| [1] |
蒋超, 崔玉伟, 王辉. 基于图像的无人机战场态势感知技术综述[J]. 测控技术, 2021, 40(12): 14-19.
|
|
|
|
| [2] |
纪广, 郝建国, 张振伟. 面向无人机作战的虚拟孪生系统设计方案[J]. 兵工学报, 2022, 43(8): 1902-1912.
|
|
doi: 10.12382/bgxb.2021.0408 |
|
| [3] |
龙霄潇, 程新景, 朱昊, 等. 三维视觉前沿进展[J]. 中国图象图形学报, 2021, 26(6): 1389-1428.
|
|
|
|
| [4] |
张宗华, 刘巍, 刘国栋, 等. 三维视觉测量技术及应用进展[J]. 中国图象图形学报, 2021, 26(6): 1483-1502.
|
|
|
|
| [5] |
赵双赫. 基于双目立体视觉的实时三维重建系统研究[D]. 西安: 西安电子科技大学, 2022.
|
|
|
|
| [6] |
|
| [7] |
|
| [8] |
朱红军, 高潮, 郭永彩. 基于计算机视觉的非朗伯表面三维重构[J]. 强激光与粒子束, 2014, 26(1): 295-305.
|
|
|
|
| [9] |
|
| [10] |
陈龙, 张建林, 彭昊, 等. 多尺度注意力与领域自适应的小样本图像识别[J]. 光电工程, 2023, 50(4): 67-80.
|
|
|
|
| [11] |
杜小强, 李卓林, 马锃宏, 等. 基于空间注意力和可变形卷积的无人机田间障碍物检测[J]. 农业机械学报, 2023, 54(2): 275-283.
|
|
|
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
Discover a wide range of drone datasets senseFlyDS.(2013-12-26)[2022-07-08]. https://www.sensefly.com/education/datasets/.
|
| [27] |
|
| [28] |
doi: 10.1109/TPAMI.2009.161 pmid: 20558871 |
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [1] | 赵志欣, 曹玉龙, 陈远帅, 周辉林, 王玉皞. 面向外辐射源雷达目标探测的非时变稀疏模型和深度展开网络实现方法[J]. 兵工学报, 2024, 45(8): 2806-2816. |
| [2] | 杨环宇, 王军, 吴祥, 薄煜明, 马立丰, 陆金磊. 一种坐标通道注意力深度学习网络的军用飞机识别方法[J]. 兵工学报, 2024, 45(7): 2128-2143. |
| [3] | 刘鹏, 熊泽宇, 景文博, 冯萱, 张俊豪, 刘桐伯, 吴雪妮, 夏璇, 万琳琳, 赵海丽. 降质靶标检测算法[J]. 兵工学报, 2024, 45(6): 2065-2075. |
| [4] | 罗皓文, 何绍溟, 亢有为. 一种基于迁移学习的多任务制导算法[J]. 兵工学报, 2024, 45(6): 1787-1798. |
| [5] | 武凌霄, 康家银, 姬云翔, 马寒雁. 基于多判别器双流生成对抗网络的红外与可见光图像融合[J]. 兵工学报, 2024, 45(6): 1799-1812. |
| [6] | 栗苹, 周宇, 曹荣刚, 李发栋, 曹宇曦, 李佳武, 张安琪. 基于深度学习和双域融合的红外成像制导系统复杂背景噪声去除方法[J]. 兵工学报, 2024, 45(6): 1747-1760. |
| [7] | 沈英, 刘贤财, 王舒, 黄峰. 基于偏振编码图像的低空伪装目标实时检测[J]. 兵工学报, 2024, 45(5): 1374-1383. |
| [8] | 林森, 王金刚, 高宏伟. 基于全局补偿注意力机制的战场图像去雾方法[J]. 兵工学报, 2024, 45(4): 1344-1353. |
| [9] | 宋晓茹, 刘康, 高嵩, 陈超波, 阎坤. 复杂战场环境下改进YOLOv5军事目标识别算法研究[J]. 兵工学报, 2024, 45(3): 934-947. |
| [10] | 熊佳梅, 王永振, 燕雪峰, 魏明强. 一种基于语义引导和对比学习的战场图像去烟算法[J]. 兵工学报, 2024, 45(2): 671-683. |
| [11] | 田大明, 苗圃. 融合模型求解与深度学习的可见光通信非线性均衡器[J]. 兵工学报, 2024, 45(2): 466-473. |
| [12] | 张堃, 杜睿怡, 时昊天, 华帅. 基于Mogrifier-BiGRU的飞行器轨迹预测[J]. 兵工学报, 2024, 45(2): 373-384. |
| [13] | 杨家铭, 潘悦, 王强, 曹怀刚, 高荪培. 水下弱目标跟踪的深度学习方法研究[J]. 兵工学报, 2024, 45(2): 385-394. |
| [14] | 吕卫民, 孙晨峰, 任立坤, 赵杰, 李永强. 一种基于TCN-LGBM的航空发动机气路故障诊断方法[J]. 兵工学报, 2024, 45(1): 253-263. |
| [15] | 李曾琳, 李波, 白双霞, 孟波波. 基于AM-SAC的无人机自主空战决策[J]. 兵工学报, 2023, 44(9): 2849-2858. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
 京公网安备11010802024360号 京ICP备05059581号-4
京公网安备11010802024360号 京ICP备05059581号-4