
主管单位:中国科学技术协会
主办单位:中国兵工学会
ISSN 1000-1093 CN 11-2176/TJ
主办单位:中国兵工学会
ISSN 1000-1093 CN 11-2176/TJ
兵工学报 ›› 2023, Vol. 44 ›› Issue (2): 484-495.doi: 10.12382/bgxb.2021.0606
尹依伊1,2, 王晓芳1,*( ), 周健3
), 周健3
收稿日期:2021-09-05
上线日期:2022-06-10
通讯作者:
YIN Yiyi1,2, WANG Xiaofang1,*(), ZHOU Jian3
Received:2021-09-05
Online:2022-06-10
摘要:
针对多无人机同时到达目标的航迹规划问题,建立战场环境模型和单无人机航迹规划的马尔可夫决策模型,基于Q学习算法解算航程最短的最优航迹,应用基于Q学习算法得到的经验矩阵快速解算各无人机的最短航迹并计算协同航程,通过调整绕行无人机的动作选择策略,得到各无人机满足时间协同的航迹组。考虑多无人机的避碰问题,通过设计后退参数确定局部重规划区域,基于深度Q学习理论,采用神经网络替代Qtable对局部多无人机航迹进行重规划,避免维度爆炸问题。对于先前未探明的障碍物,参考人工势场法思想设计障碍物Q矩阵,将其叠加至原Q矩阵,实现无人机的避碰。仿真结果表明:所提基于Q学习的多无人机协同航迹规划算法能够得到时间协同与碰撞避免的协同航迹,并对环境建模时所未探明的障碍物进行躲避;与A*算法相比,针对在线应用问题,新算法具有更高的求解效率。
中图分类号:
尹依伊, 王晓芳, 周健. 基于Q学习的多无人机协同航迹规划方法[J]. 兵工学报, 2023, 44(2): 484-495.
YIN Yiyi, WANG Xiaofang, ZHOU Jian. Q-Learning-based Multi-UAV Cooperative Path Planning Method[J]. Acta Armamentarii, 2023, 44(2): 484-495.
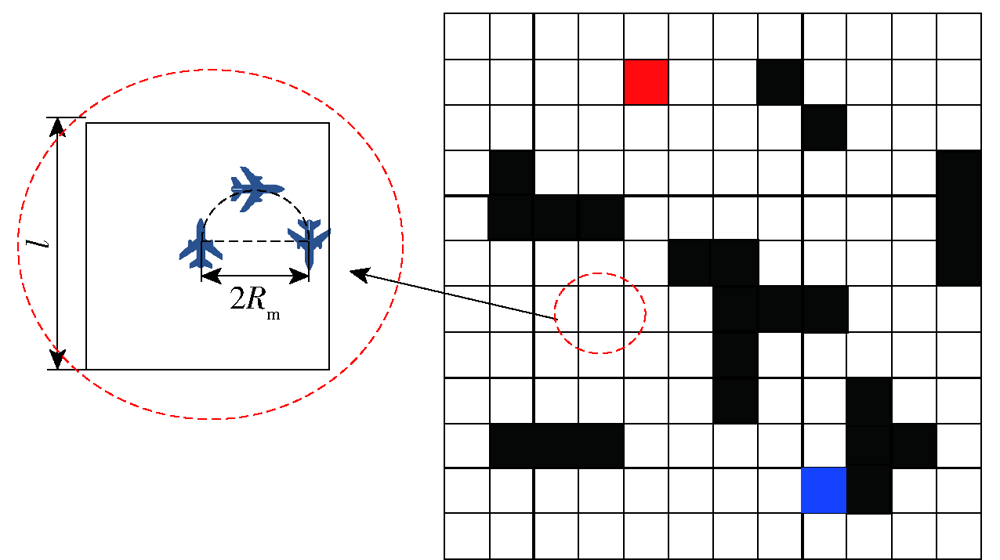
图1 战场模型示意图
Fig.1 Diagram of battlefield model
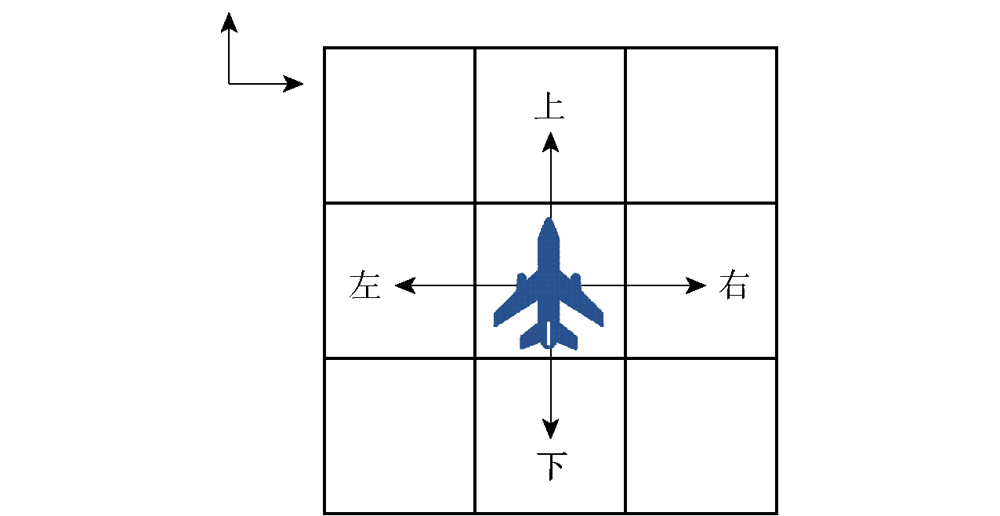
图2 动作空间示意图
Fig.2 Diagram of action space
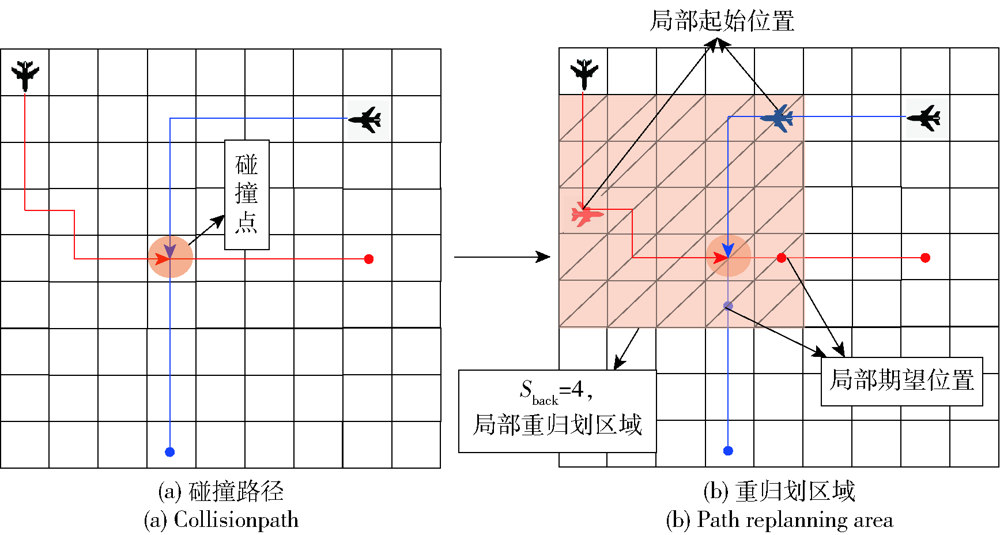
图3 多无人机局部航迹重规划
Fig.3 Partial path replanning for multiple UAVs
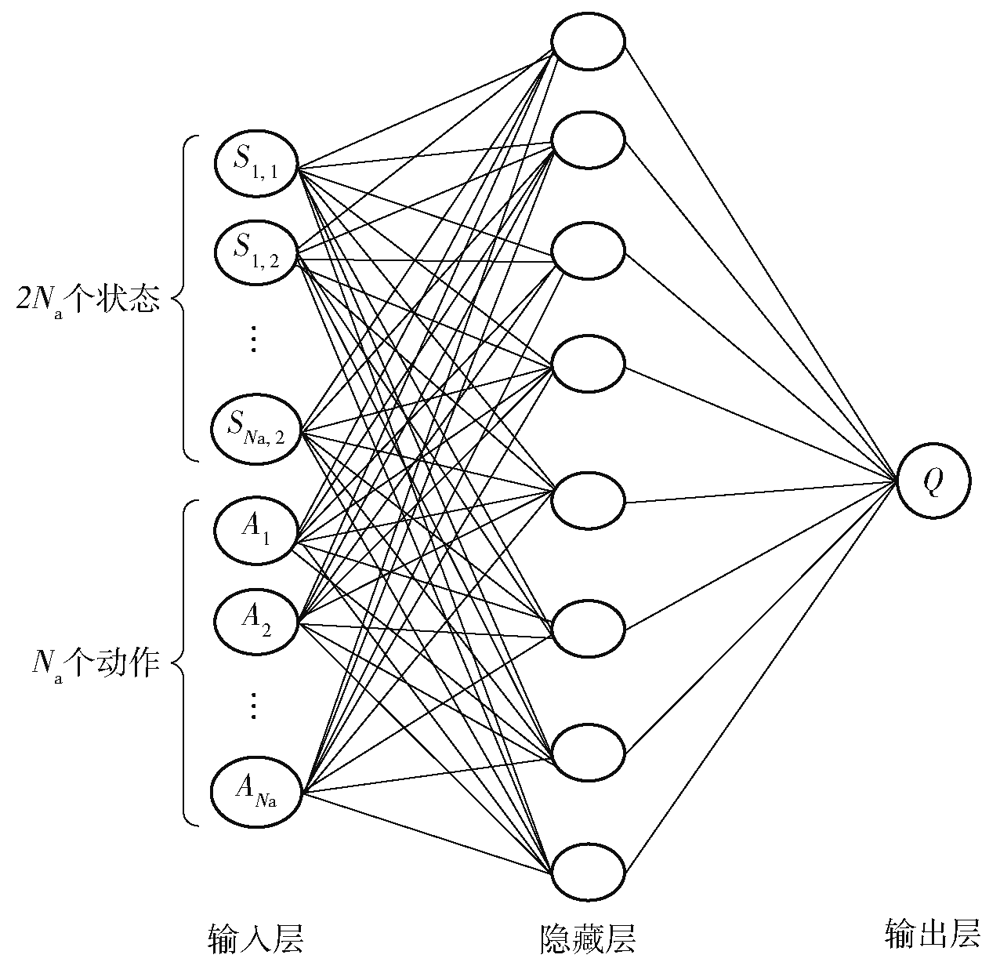
图4 局部重规划的神经网络模型
Fig.4 Neural network model of partial path replanning
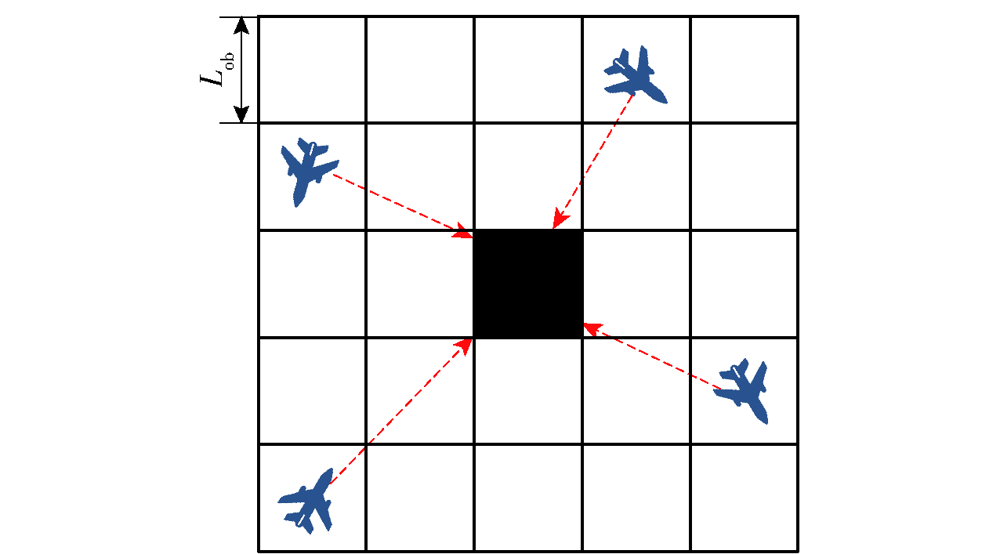
图5 未探明障碍物区域
Fig.5 Unexplored obstacle area
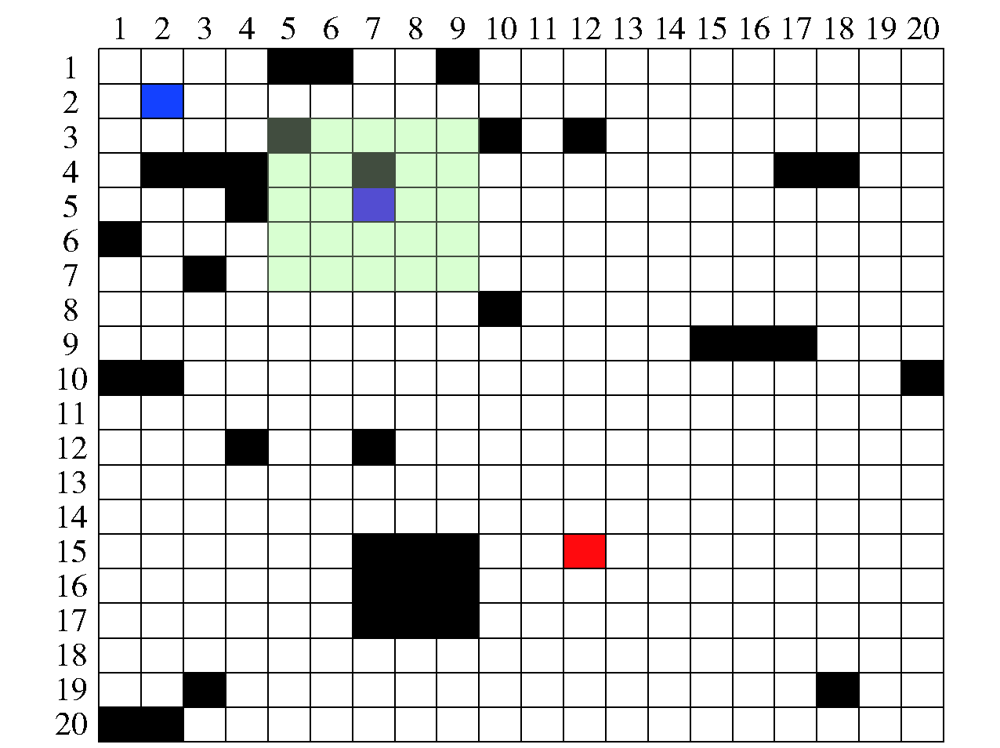
图6 叠加未探明障碍物后的战场模型
Fig.6 Battlefield model with unexplored obstacle
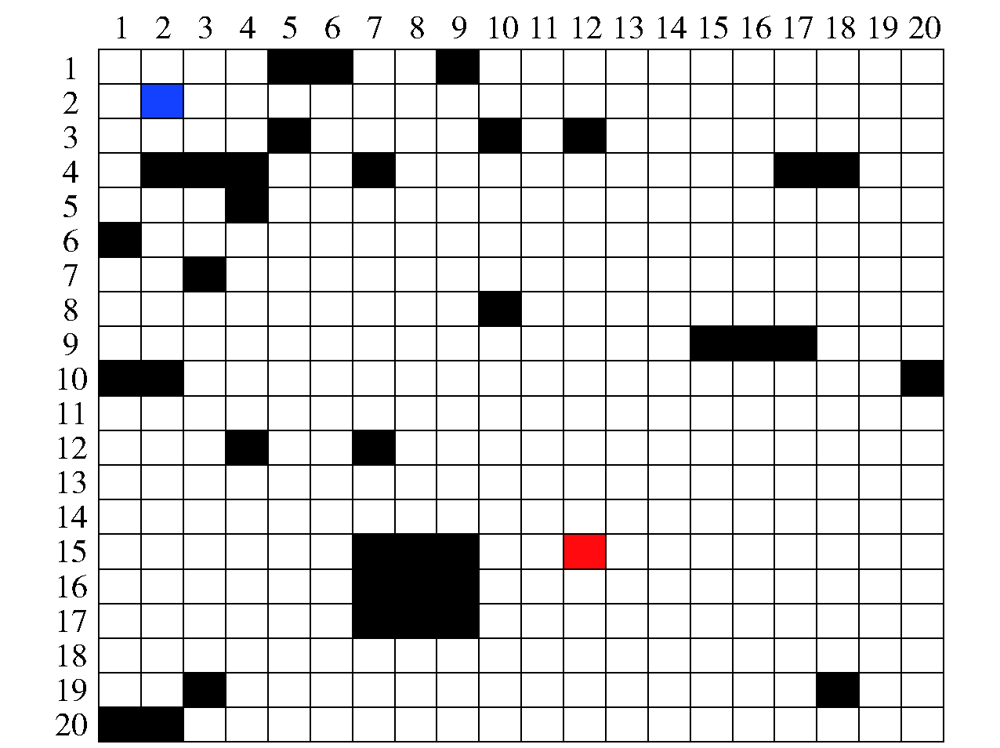
图7 仿真算例战场模型
Fig.7 A simulation example of battlefield model
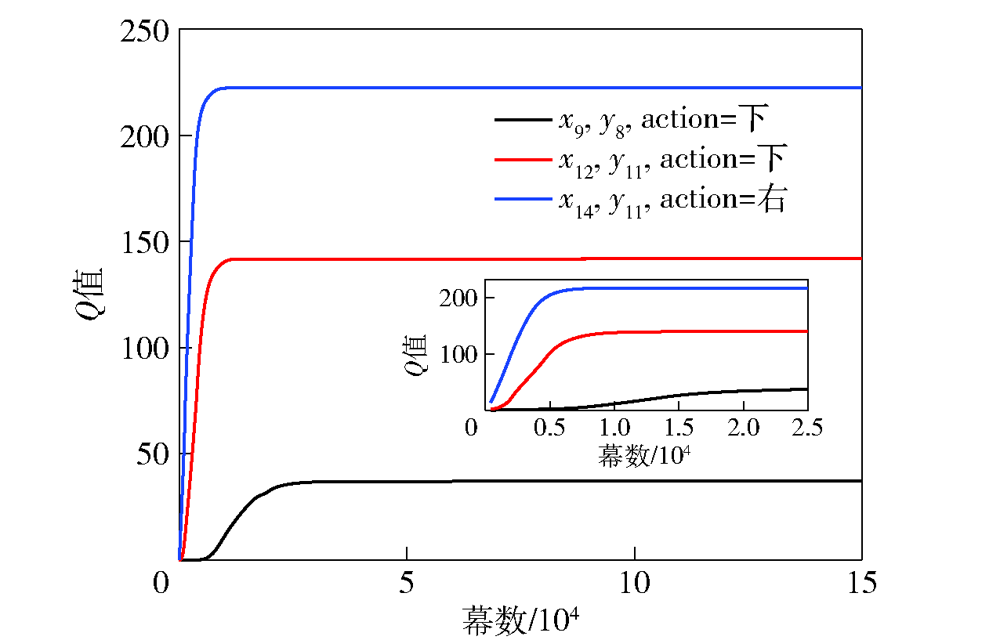
图8 部分Q值变化曲线
Fig.8 Part of Q value variation curves
| 无人机编号 | 初始位置 | 期望位置 | ||
|---|---|---|---|---|
| x | y | X | Y | |
| 1 | 2 | 1 | 15 | 12 |
| 2 | 1 | 18 | 15 | 12 |
| 3 | 16 | 1 | 15 | 12 |
| 4 | 19 | 20 | 15 | 12 |
表1 无人机相关参数
Table 1 Parameters of UAVs
| 无人机编号 | 初始位置 | 期望位置 | ||
|---|---|---|---|---|
| x | y | X | Y | |
| 1 | 2 | 1 | 15 | 12 |
| 2 | 1 | 18 | 15 | 12 |
| 3 | 16 | 1 | 15 | 12 |
| 4 | 19 | 20 | 15 | 12 |
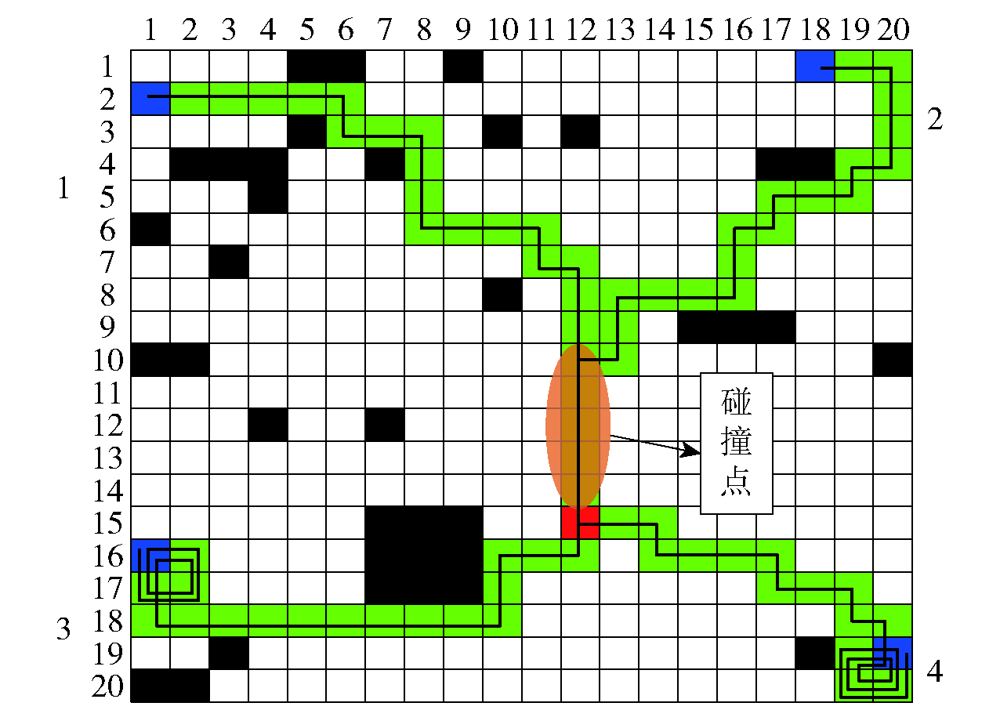
图9 满足时间协同的协同航迹1
Fig.9 Time-coordinated path 1
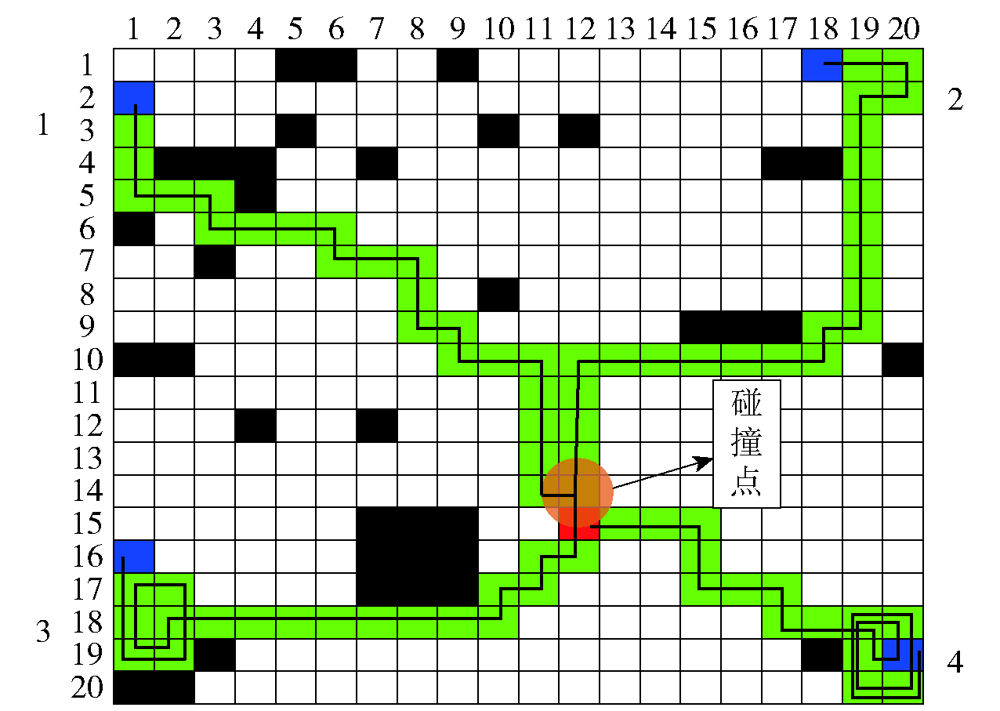
图10 满足时间协同的协同航迹2
Fig.10 Time-coordinated path 2
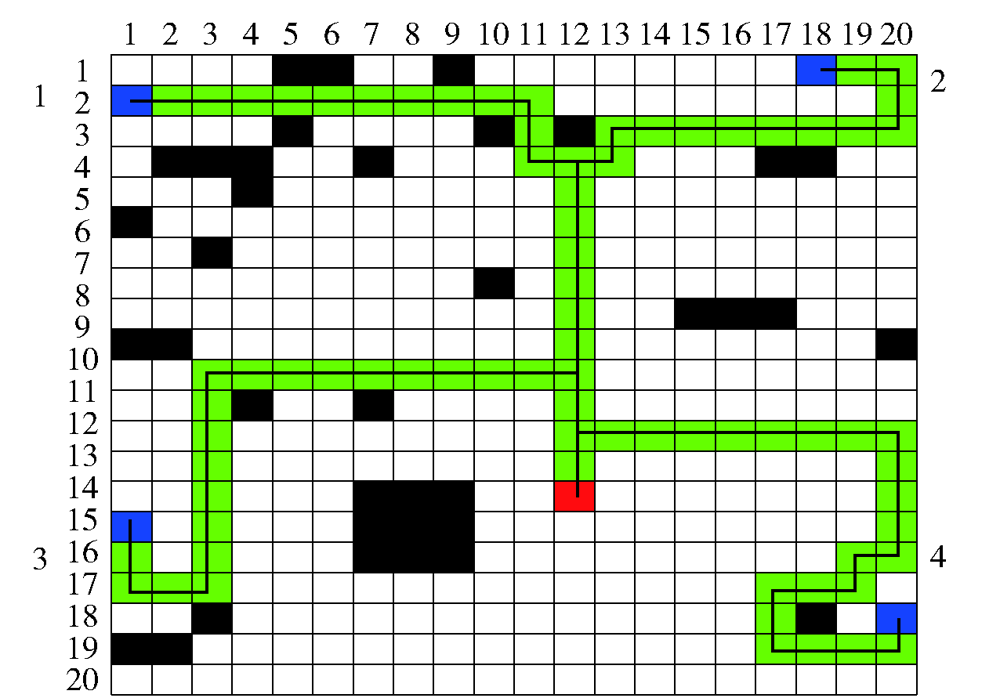
图11 基于A*算法的协同航迹
Fig.11 Time-coordinated paths based on A* algorithm
| 次数 | Q学习算法时间/s | A*算法时间/s |
|---|---|---|
| 1 | 0.131 | 0.278 |
| 2 | 0.135 | 0.196 |
| 3 | 0.122 | 0.209 |
| 4 | 0.158 | 0.194 |
| 4 | 0.128 | 0.202 |
表2 Q学习算法与A*算法性能对比
Table 2 Performance comparison between the Q-learning and A* algorithms
| 次数 | Q学习算法时间/s | A*算法时间/s |
|---|---|---|
| 1 | 0.131 | 0.278 |
| 2 | 0.135 | 0.196 |
| 3 | 0.122 | 0.209 |
| 4 | 0.158 | 0.194 |
| 4 | 0.128 | 0.202 |
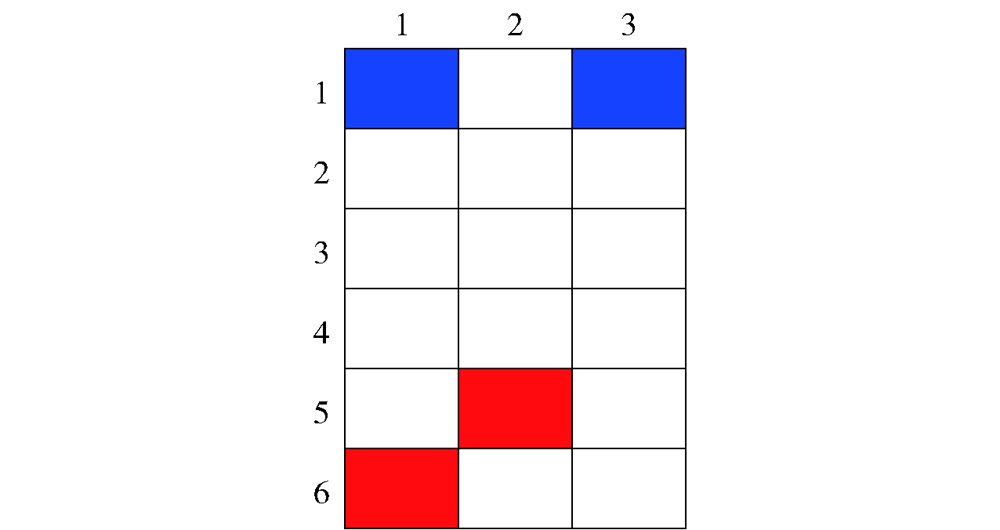
图12 局部重规划区域
Fig.12 Partial path replanning area
| 无人机编号 | 初始位置 | 期望位置 | ||
|---|---|---|---|---|
| x | y | X | Y | |
| 1 | 1 | 1 | 6 | 1 |
| 2 | 1 | 3 | 5 | 2 |
表3 局部区域无人机3、4的初始位置、期望位置
Table 3 Starting position and expected position of UAV 3 and 4 in the partial area
| 无人机编号 | 初始位置 | 期望位置 | ||
|---|---|---|---|---|
| x | y | X | Y | |
| 1 | 1 | 1 | 6 | 1 |
| 2 | 1 | 3 | 5 | 2 |
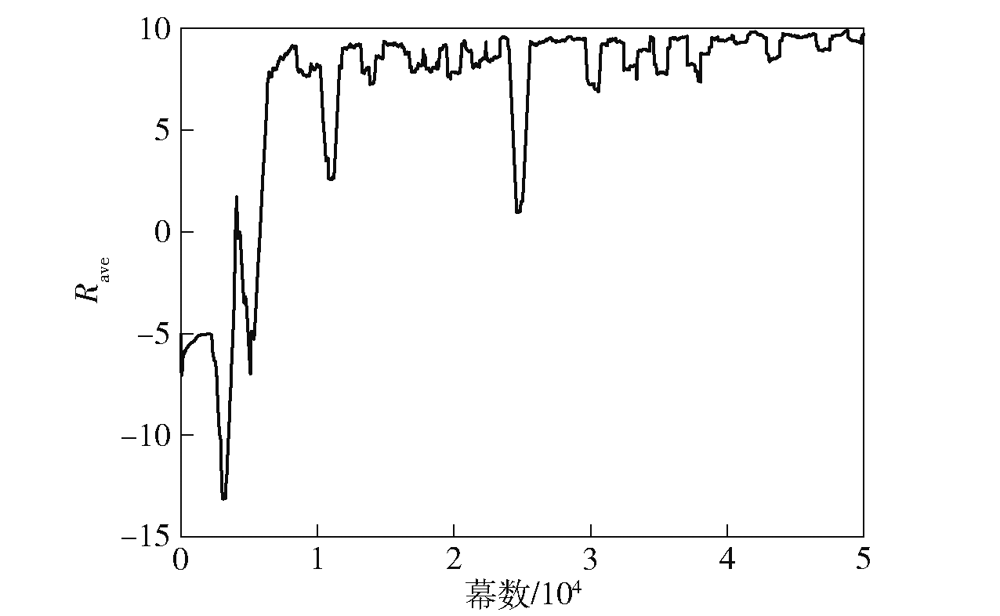
图13 平均回报函数曲线
Fig.13 Average reward curve
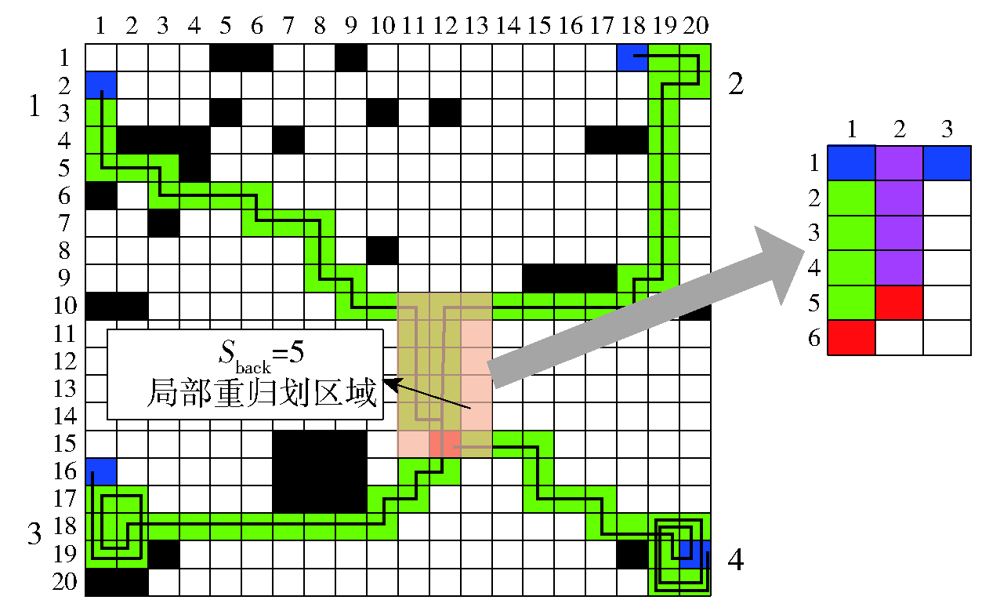
图14 局部重规划示意图
Fig.14 Diagram of partial path replanning
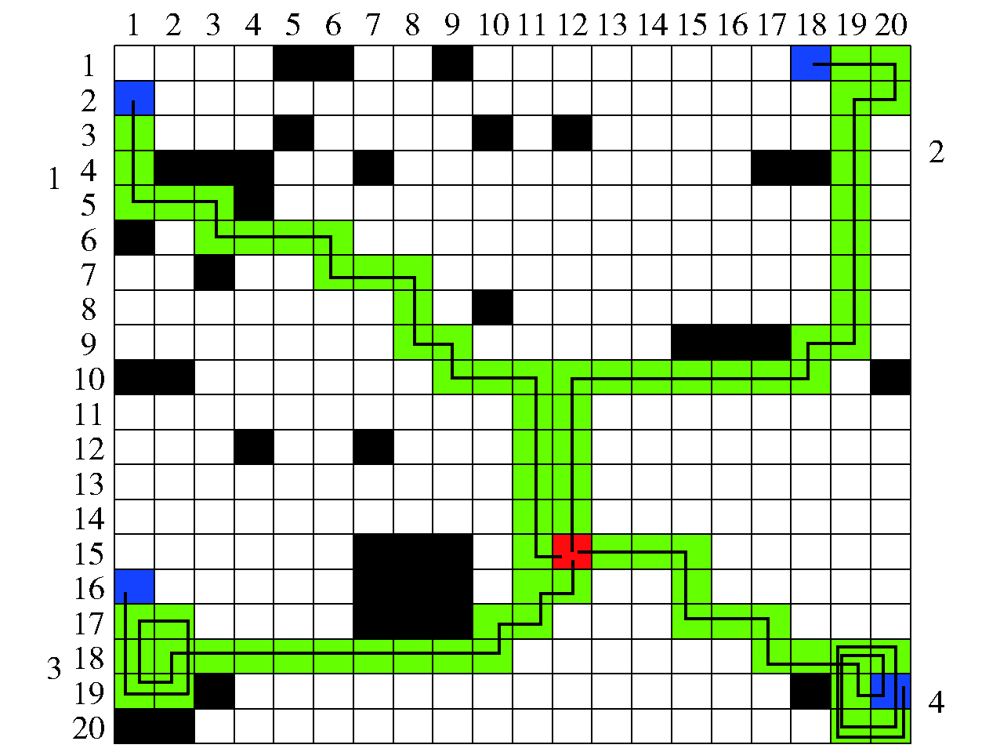
图15 协同航迹图
Fig.15 Diagram of cooperative path
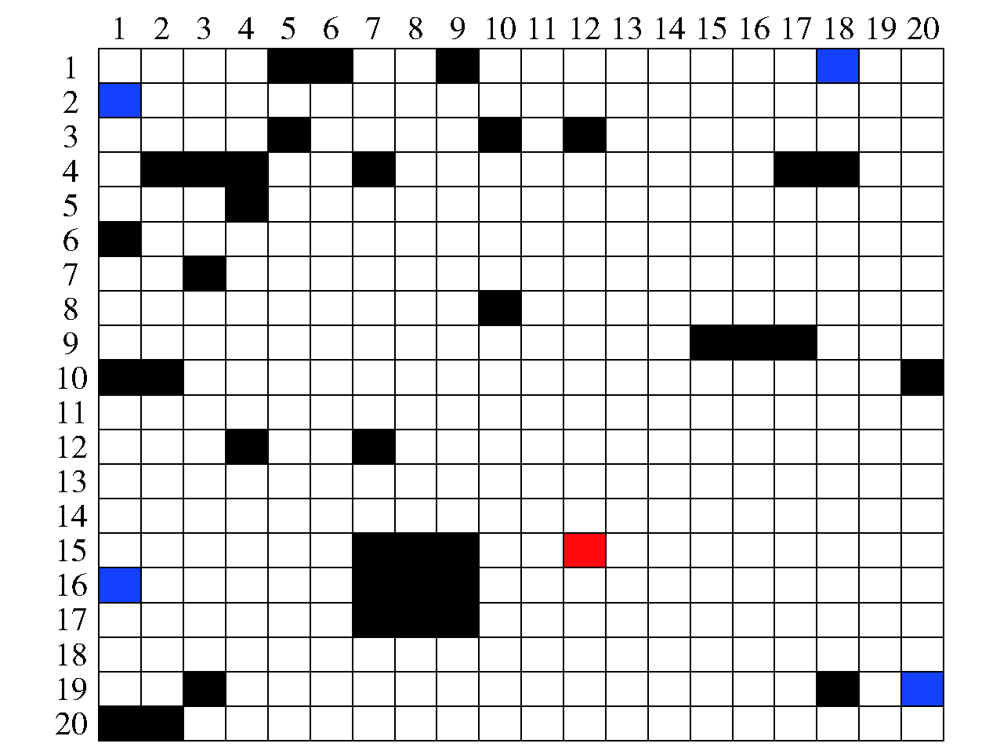
图16 存在未探明障碍物战场的仿真算例
Fig.16 Battlefield model with unexplored obstacle for simulation
| Q-table | 上 | 下 | 左 | 右 |
|---|---|---|---|---|
| state1 | 0 | 1.3118 | 0 | 1.3118 |
| … | … | … | … | … |
| State48 | 6.2560 | 9.7735 | 6.2550 | 9.7734 |
| … | … | … | … | … |
| state69 | 9.7734 | 15.270 | 9.7734 | 15.270 |
| state70 | 0 | 19.088 | 12.216 | 19.088 |
表4 叠加前局部经验矩阵取值
Table 4 Partial Q-table before superposition
| Q-table | 上 | 下 | 左 | 右 |
|---|---|---|---|---|
| state1 | 0 | 1.3118 | 0 | 1.3118 |
| … | … | … | … | … |
| State48 | 6.2560 | 9.7735 | 6.2550 | 9.7734 |
| … | … | … | … | … |
| state69 | 9.7734 | 15.270 | 9.7734 | 15.270 |
| state70 | 0 | 19.088 | 12.216 | 19.088 |
| Q-table | 上 | 下 | 左 | 右 |
|---|---|---|---|---|
| state1 | 0 | 1.3118 | 0 | 1.3118 |
| … | … | … | … | … |
| State48 | 6.2550 | 9.1334 | 5.6150 | 9.3638 |
| … | … | … | … | … |
| state69 | 9.3638 | 14.631 | 9.1334 | 15.271 |
| state70 | 0 | 19.088 | 12.216 | 19.088 |
表5 叠加后局部经验矩阵取值
Table 5 Partial Q-table after superposition
| Q-table | 上 | 下 | 左 | 右 |
|---|---|---|---|---|
| state1 | 0 | 1.3118 | 0 | 1.3118 |
| … | … | … | … | … |
| State48 | 6.2550 | 9.1334 | 5.6150 | 9.3638 |
| … | … | … | … | … |
| state69 | 9.3638 | 14.631 | 9.1334 | 15.271 |
| state70 | 0 | 19.088 | 12.216 | 19.088 |
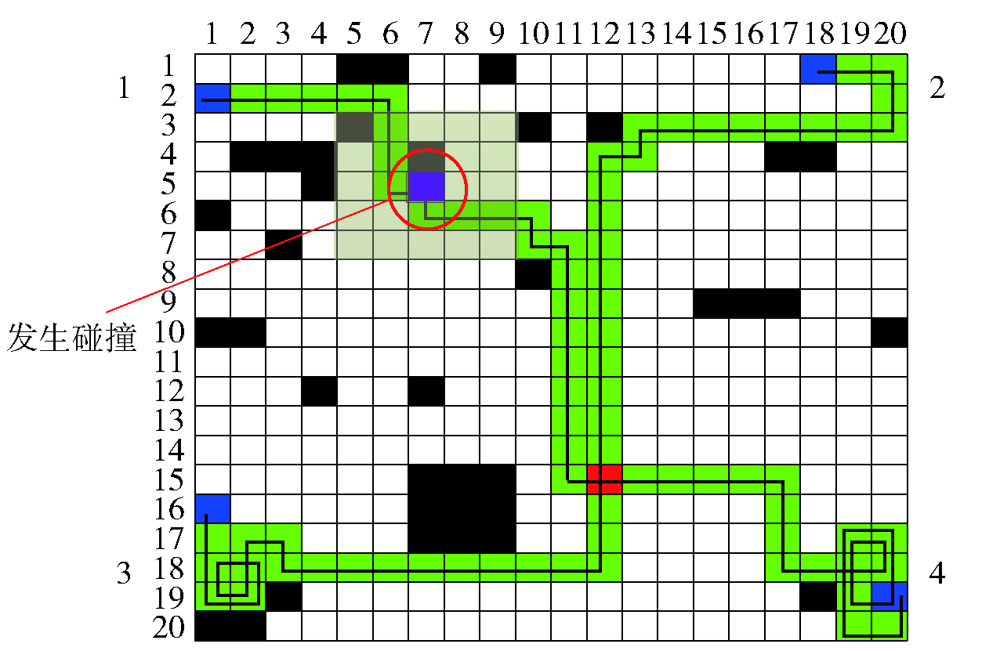
图17 存在未探明障碍物的协同航迹1
Fig.17 Cooperative path 1 with unexplored obstacle
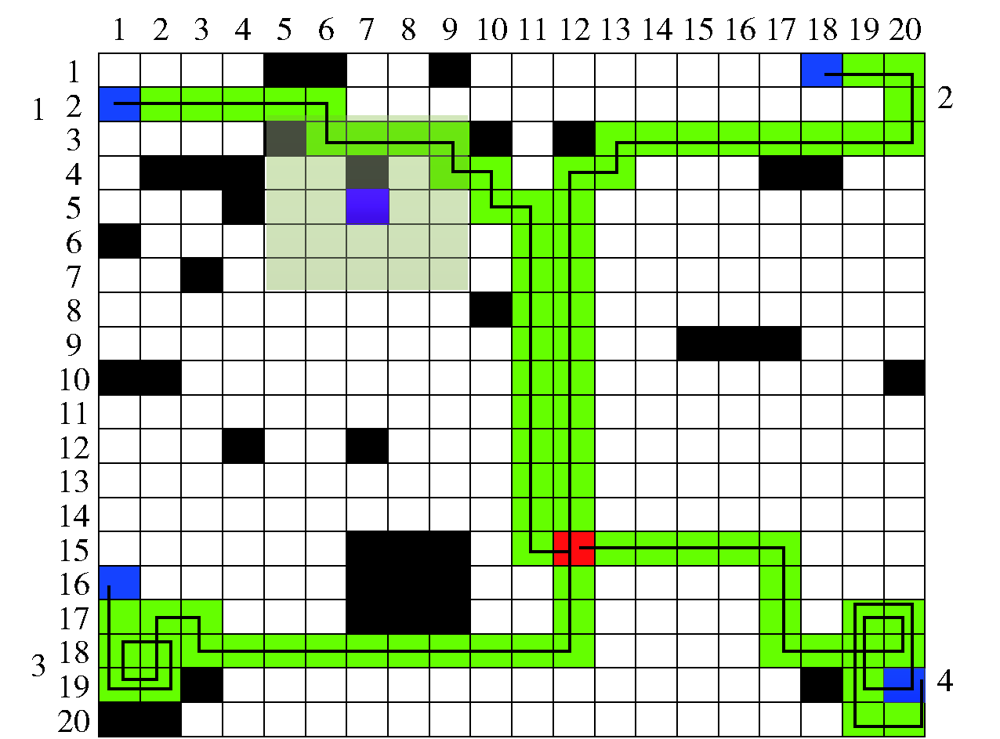
图18 存在未探明障碍物的协同航迹2
Fig.18 Cooperative path 2 with unexplored obstacle
| [1] |
陈中原, 韦文书, 陈万春. 基于强化学习的多弹协同攻击智能制导律[J]. 兵工学报, 2021, 42(8):1638-1647.
|
|
doi: 10.3969/j.issn.1000-1093.2021.08.008 |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
杜云, 彭瑜, 邵士凯, 等. 基于改进粒子群优化的多无人机协同航迹规划[J]. 科学技术与工程, 2020, 20(32):13258-13264.
|
|
|
|
| [6] |
王洪斌, 郝策, 张平, 等. 基于A*算法和人工势场法的移动机器人路径规划[J]. 中国机械工程, 2019 30(20):2489-2496.
|
|
|
|
| [7] |
doi: 10.3390/s18124188 URL |
| [8] |
|
| [9] |
杜楠楠, 陈建, 马奔, 等. 多太阳能无人机覆盖路径优化方法[J]. 航空学报, 2021, 42(6):324476.
doi: 10.7527/S1000-6893.2020.24476 |
|
doi: 10.7527/S1000-6893.2020.24476 |
|
| [10] |
|
| [11] |
胡腾, 刘占军, 刘洋, 等. 多无人机3D侦察路径规划[J]. 系统工程与电子技术, 2019, 41(7):1551-1559.
|
|
|
|
| [12] |
|
| [13] |
doi: 10.1109/TAES.7 URL |
| [14] |
乔林, 罗杰. 学习过程中共享经验的Q学习算法的研究[J]. 计算机科学, 2012, 39(5):213-216.
|
|
|
|
| [15] |
doi: 10.1109/OJCOMS.2021.3081996 URL |
| [16] |
王毅然, 经小川, 田涛, 等. 基于强化学习的多Agent路径规划方法研究[J]. 计算机应用与软件, 2019, 36(8): 165-171.
|
|
|
|
| [17] |
doi: 10.1109/Access.6287639 URL |
| [18] |
doi: 10.1049/cit2.v5.3 URL |
| [19] |
相晓嘉, 闫超, 王菖, 等. 基于深度强化学习的固定翼无人机编队协调控制方法[J]. 航空学报, 2021, 42(4): 524009.
doi: 10.7527/S1000-6893.2020.24009 |
|
doi: 10.7527/S1000-6893.2020.24009 |
|
| [20] |
姚冬冬, 王晓芳, 田震. 一种同时满足攻击角度和时间的航迹规划方法[J]. 弹箭与制导学报, 2019, 39(3):111-114.
|
|
|
| [1] | 郭志明, 娄文忠, 李涛, 张梦宇, 白子龙, 乔虎. 基于改进蝗虫优化算法考虑任务威胁的多无人机协同航迹规划[J]. 兵工学报, 2023, 44(S2): 52-60. |
| [2] | 赵军民, 何浩哲, 王少奇, 聂聪, 焦迎杰. 复杂环境下多无人机目标跟踪与避障联合航迹规划[J]. 兵工学报, 2023, 44(9): 2685-2696. |
| [3] | 张堃, 刘泽坤, 华帅, 张振冲, 李珂, 于竞婷. 基于T/S-SAS的多无人机四维协同攻击航线生成[J]. 兵工学报, 2023, 44(6): 1576-1587. |
| [4] | 傅晋博, 张栋, 王孟阳, 赵军民. 面向目标定位精度提升的无人机航迹规划[J]. 兵工学报, 2023, 44(11): 3394-3406. |
| [5] | 王康, 司鹏, 陈莉, 李忠新, 吴志林. 基于改进沙猫群算法的无人机三维航迹规划[J]. 兵工学报, 2023, 44(11): 3382-3393. |
| [6] | 尤浩, 常新龙, 赵久奋, 张有宏, 王顺宏. 带攻击角度约束的三维领弹-从弹时间协同制导律[J]. 兵工学报, 2023, 44(11): 3369-3381. |
| [7] | 李文, 尚腾, 姚寅伟, 赵启伦. 速度时变情况下多飞行器时间协同制导方法研究[J]. 兵工学报, 2020, 41(6): 1096-1110. |
| [8] | 刘重, 高晓光, 符小卫, 牟之英. 未知环境下异构多无人机协同搜索打击中的联盟组建[J]. 兵工学报, 2015, 36(12): 2284-2297. |
| [9] | 国海峰, 丁达理, 吴文超, 刘尧林. 多无人机远距突防协同目标搜索决策[J]. 兵工学报, 2014, 35(2): 248-255. |
| [10] | 傅阳光, 周成平2, 胡汉平2. 无人飞行器海上航迹规划差分进化算法研究[J]. 兵工学报, 2012, 33(3): 295-300. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
 京公网安备11010802024360号 京ICP备05059581号-4
京公网安备11010802024360号 京ICP备05059581号-4