
Responsible Institution: China Association for Science and Technology
Sponsor: China Ordnance Society
ISSN 1000-1093 CN 11-2176/TJ
Sponsor: China Ordnance Society
ISSN 1000-1093 CN 11-2176/TJ
Acta Armamentarii ›› 2024, Vol. 45 ›› Issue (10): 3385-3396.doi: 10.12382/bgxb.2023.0862
Previous Articles Next Articles
FU Yanfang1, LEI Kailin1,*( ), WEI Jianing2, CAO Zijian1, YANG Bo1, WANG Wei3, SUN Zelong4, LI Qinjie1
), WEI Jianing2, CAO Zijian1, YANG Bo1, WANG Wei3, SUN Zelong4, LI Qinjie1
Received:2023-09-05
Online:2024-10-28
Contact:
LEI Kailin
CLC Number:
FU Yanfang, LEI Kailin, WEI Jianing, CAO Zijian, YANG Bo, WANG Wei, SUN Zelong, LI Qinjie. A Hierarchical Multi-Agent Collaborative Decision-making Method Based on the Actor-critic Framework[J]. Acta Armamentarii, 2024, 45(10): 3385-3396.
Add to citation manager EndNote|Ris|BibTeX
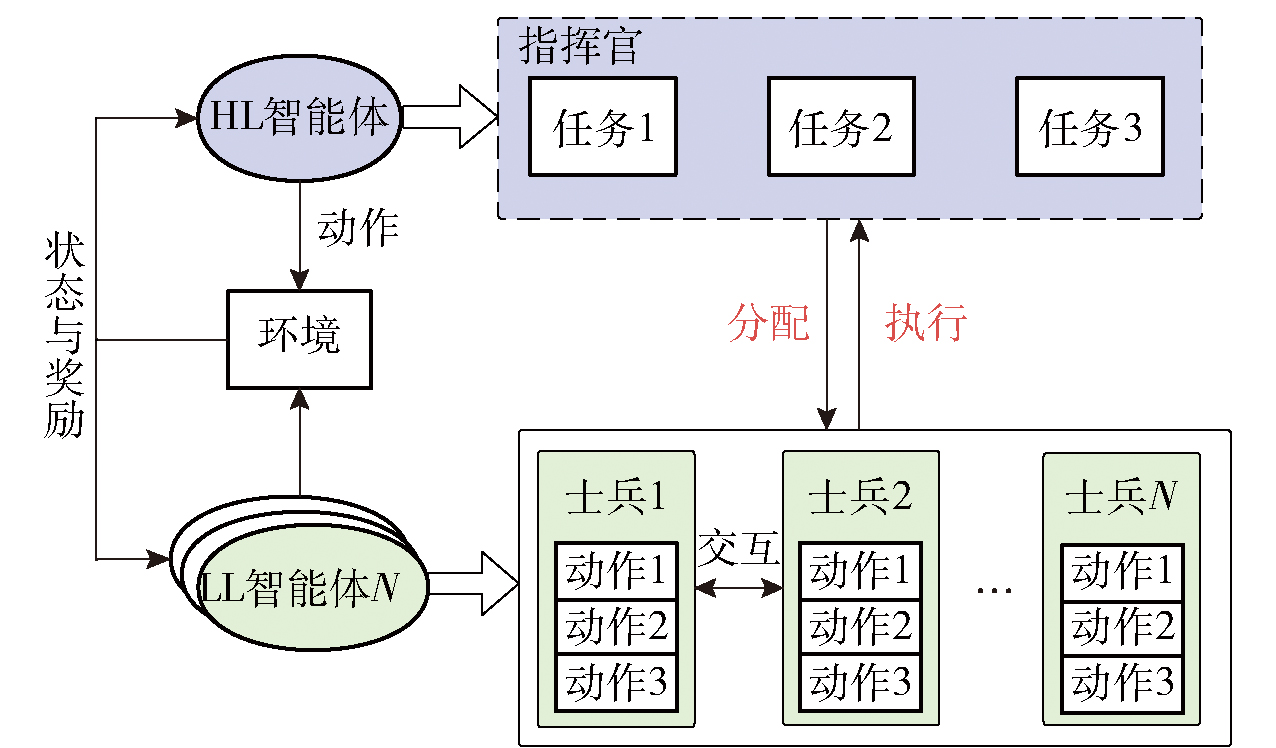
Fig.1 Overall framework
| 状态类型 | 状态信息 | One-hot编码 |
|---|---|---|
| 对空拦截 | [0,0,0,1] | |
| TTi | 对陆打击 | [0,0,1,0] |
| 空战巡逻 | [0,1,0,0] | |
| 反地面战巡逻 | [1,0,0,0] | |
| TTMi | 时刻T1 | [0,1] |
| 时刻T2 | [1,0] | |
| TSi | 未启动 | [0,1] |
| 启动 | [1,0] | |
| CTi | 导弹驱逐舰 | [0,1] |
| 轰炸机 | [1,0] |
Table 1 State information one-hot encoding table
| 状态类型 | 状态信息 | One-hot编码 |
|---|---|---|
| 对空拦截 | [0,0,0,1] | |
| TTi | 对陆打击 | [0,0,1,0] |
| 空战巡逻 | [0,1,0,0] | |
| 反地面战巡逻 | [1,0,0,0] | |
| TTMi | 时刻T1 | [0,1] |
| 时刻T2 | [1,0] | |
| TSi | 未启动 | [0,1] |
| 启动 | [1,0] | |
| CTi | 导弹驱逐舰 | [0,1] |
| 轰炸机 | [1,0] |
| 层级 | 意义 | 奖赏值 |
|---|---|---|
| HLr | 子任务决策正确 子任务决策错误 | 600 -600 |
| LLr | 毁伤次要目标 接近目标特定区域 | 100 50 |
| 自身毁伤 超出特定范围 | -100 -400 |
Table 2 Global reward function
| 层级 | 意义 | 奖赏值 |
|---|---|---|
| HLr | 子任务决策正确 子任务决策错误 | 600 -600 |
| LLr | 毁伤次要目标 接近目标特定区域 | 100 50 |
| 自身毁伤 超出特定范围 | -100 -400 |
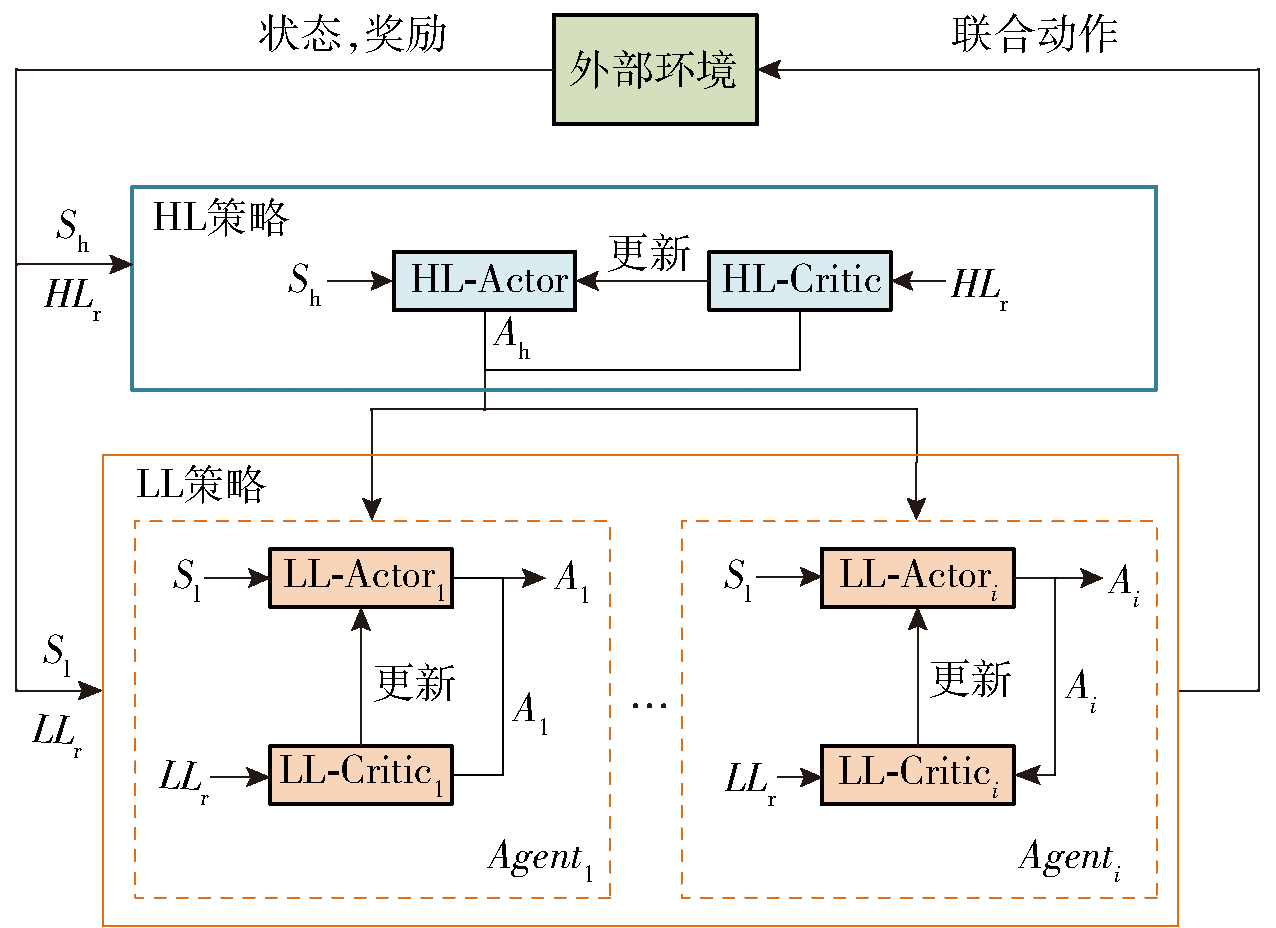
Fig.2 Hierarchical multi-agent algorithm framework based on AC framework

Fig.3 Pseudocode for HMaAC algorithm

Fig.4 Algorithm flowchart

Fig.5 2v2 assumed scenario
| 推演方 | 单元名称 | 单元数量 | 单元武器 |
|---|---|---|---|
| 红方 | MQ-1C型无人机 | 1 | 4×反坦克导弹 |
| MQ-1B型无人机 | 2 | 2×空对空针刺飞弹 | |
| 蓝方 | 坦克排(4×T-72主战坦克) | 1 | 80×12.7mm/50高射机炮 |
| MQ-1B型无人机 | 2 | 2×空对空针刺飞弹 |
Table 3 Assumed information
| 推演方 | 单元名称 | 单元数量 | 单元武器 |
|---|---|---|---|
| 红方 | MQ-1C型无人机 | 1 | 4×反坦克导弹 |
| MQ-1B型无人机 | 2 | 2×空对空针刺飞弹 | |
| 蓝方 | 坦克排(4×T-72主战坦克) | 1 | 80×12.7mm/50高射机炮 |
| MQ-1B型无人机 | 2 | 2×空对空针刺飞弹 |
| 智能体 | 单元名称 | 智能体数量 |
|---|---|---|
| HL | 对地攻击任务 | 1 |
| 对空打击任务 | ||
| LL | MQ-1B型无人机 | 2 |
Table 4 Agent decision hierarchy
| 智能体 | 单元名称 | 智能体数量 |
|---|---|---|
| HL | 对地攻击任务 | 1 |
| 对空打击任务 | ||
| LL | MQ-1B型无人机 | 2 |

Fig.6 Neural network architecture
| 参数 | 数值 |
|---|---|
| 最大回合数量 | 20000 |
| 每个回合中最大步数 | 100 |
| 批样本大小 | 256 |
| 熵正则项系数 | 0.2 |
| 仿真步长 | 120 |
| 随机探索轮数 | 100 |
| 评估回合数量 | 10 |
| 奖励系数α | 0.7 |
| 奖励系数β | 0.3 |
| 初始网络函数参数 | 0.0003 |
Table 5 Experimental hyperparameter settings
| 参数 | 数值 |
|---|---|
| 最大回合数量 | 20000 |
| 每个回合中最大步数 | 100 |
| 批样本大小 | 256 |
| 熵正则项系数 | 0.2 |
| 仿真步长 | 120 |
| 随机探索轮数 | 100 |
| 评估回合数量 | 10 |
| 奖励系数α | 0.7 |
| 奖励系数β | 0.3 |
| 初始网络函数参数 | 0.0003 |

Fig.7 Algorithm training results diagram

Fig.8 Comparison of the training processes of HMaAC and MADDPG algorithms

Fig.9 Battlefield situation diagraminearly training stage

Fig.10 Training convergence situation
| 推演方 | 单元名称 | 作战想定 | 单元数量 |
|---|---|---|---|
| 红方 | MQ-1C型“灰鹰”无人机 | 1 | |
| 2v2 | 2 | ||
| MQ-1B型“武装捕食者”无人机 | 4v4 | 4 | |
| 6v6 | 6 | ||
| 蓝方 | 坦克排(4×T-72主战坦克) | 1 | |
| 2v2 | 2 | ||
| MQ-1B型“武装捕食者”无人机 | 4v4 | 4 | |
| 6v6 | 6 |
Table 6 Assumed unit quantity
| 推演方 | 单元名称 | 作战想定 | 单元数量 |
|---|---|---|---|
| 红方 | MQ-1C型“灰鹰”无人机 | 1 | |
| 2v2 | 2 | ||
| MQ-1B型“武装捕食者”无人机 | 4v4 | 4 | |
| 6v6 | 6 | ||
| 蓝方 | 坦克排(4×T-72主战坦克) | 1 | |
| 2v2 | 2 | ||
| MQ-1B型“武装捕食者”无人机 | 4v4 | 4 | |
| 6v6 | 6 |
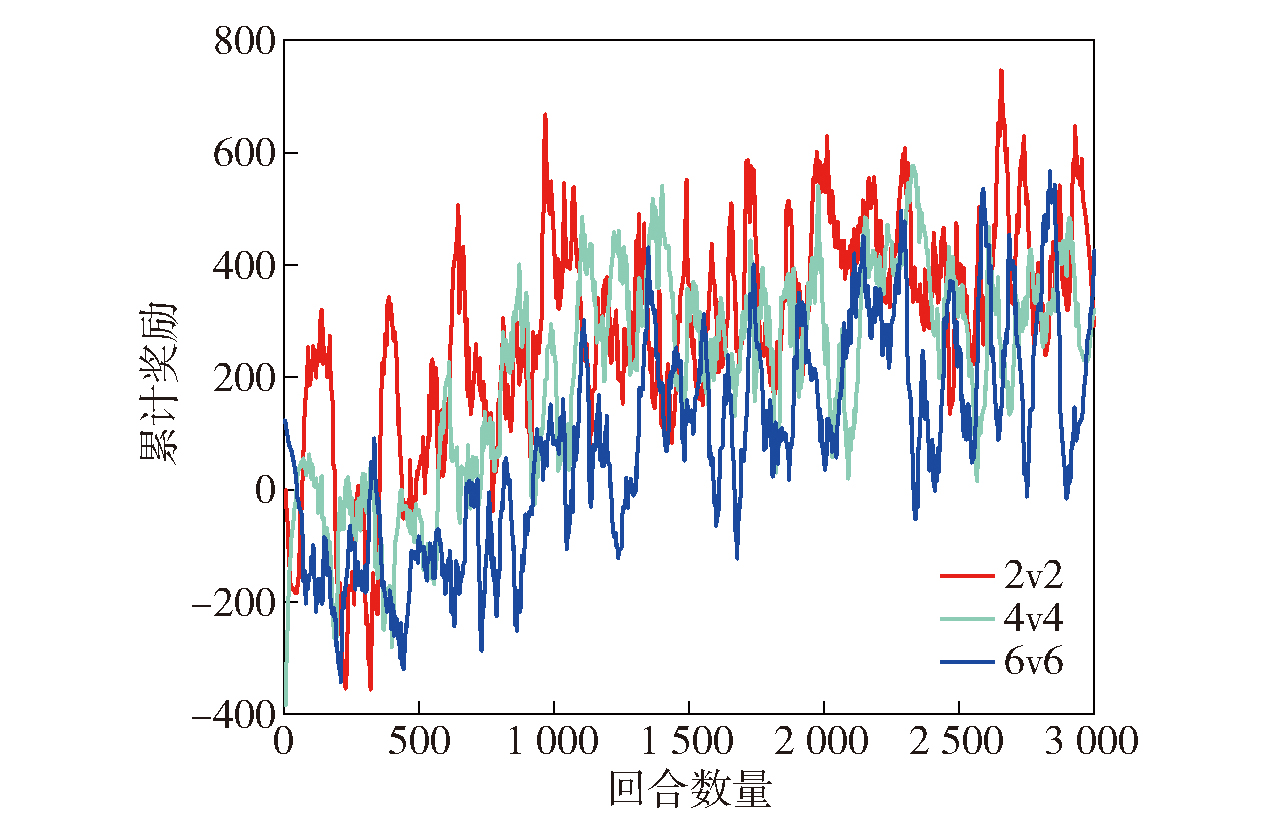
Fig.11 Comparison diagram of the HMaAC algorithm with different numbers of agents
| [1] |
常晓飞, 蒋邓怀, 姬晓闯, 等. 无人作战系统仿真发展综述[J]. 无人系统技术, 2021, 4(6): 28-36.
|
|
|
|
| [2] |
牛轶峰, 肖湘江, 柯冠岩. 无人机集群作战概念及关键技术分析[J]. 国防科技, 2013, 34(5): 37-43.
|
|
|
|
| [3] |
刘彬. 多无人艇协同编队控制理论及实验研究[D]. 武汉: 华中科技大学, 2021.
|
|
|
|
| [4] |
裴国旭, 杜晓明, 薛昭, 等. 多智能体系统在军事仿真领域的应用现状[J]. 飞航导弹, 2017(2): 46-49, 73.
|
|
|
|
| [5] |
张峰, 李明强, 唐思琦, 等. 多智能体协同决策方法研究[J]. 中国电子科学研究院学报, 2022, 17(9): 905-910.
|
|
|
|
| [6] |
周文卿, 朱纪洪, 匡敏驰, 等. 基于预知博弈树的多无人机群智协同空战算法[J]. 中国科学:技术科学, 2023, 53(2): 187-199.
|
|
|
|
| [7] |
文超, 董文瀚, 解武杰, 等. 基于回访机制的无人机集群分布式协同区域搜索方法[J]. 航空学报, 2023, 44(11): 253-270.
|
|
|
|
| [8] |
李子涵. 基于强化学习的无人机集群对抗仿真研究[D]. 西安: 西安工业大学, 2023.
|
|
|
|
| [9] |
李静晨, 史豪斌, 黄国胜. 基于自注意力机制和策略映射重组的多智能体强化学习算法[J]. 计算机学报, 2022, 45(9): 1842-1858.
|
|
|
|
| [10] |
赵立阳, 常天庆, 褚凯轩, 等. 完全合作类多智能体深度强化学习综述[J]. 计算机工程与应用, 2023, 59(12): 14-27.
doi: 10.3778/j.issn.1002-8331.2209-0186 |
|
|
|
| [11] |
夏家伟, 刘志坤, 朱旭芳, 等. 基于多智能体强化学习的无人艇集群集结方法[J]. 北京航空航天大学学报, 2023, 49(12): 3365-3376.
|
|
|
|
| [12] |
|
| [13] |
陈佳黎. 面向动作类游戏仿真的多层深度强化学习研究[D]. 成都: 电子科技大学, 2020.
|
|
|
|
| [14] |
赖俊, 魏竞毅, 陈希亮. 分层强化学习综述[J]. 计算机工程与应用, 2021, 57(3): 72-79.
doi: 10.3778/j.issn.1002-8331.2010-0038 |
|
doi: 10.3778/j.issn.1002-8331.2010-0038 |
|
| [15] |
王善锐. 基于目标分层的多智能体强化学习协作算法研究[D]. 北京: 北京交通大学, 2023.
|
|
|
|
| [16] |
|
| [17] |
刘冰雁, 叶雄兵, 岳智宏, 等. 基于多组并行深度Q网络的连续空间追逃博弈算法[J]. 兵工学报, 2021, 42(3): 663-672.
doi: 10.3969/j.issn.1000-1093.2021.03.024 |
|
|
|
| [18] |
于博文, 吕明, 张捷. 基于分层强化学习的联合作战仿真作战决策算法[J]. 火力与指挥控制, 2021, 46(10): 140-146.
|
|
|
|
| [19] |
|
| [20] |
张建东, 王鼎涵, 杨啟明, 等. 基于分层强化学习的无人机空战多维决策[J]. 兵工学报, 2023, 44(6): 1547-1563.
doi: 10.12382/bgxb.2022.0711 |
|
doi: 10.12382/bgxb.2022.0711 |
|
| [21] |
邢云燕. 美军军事决策过程[J]. 国防科技, 2018, 39(1): 76-80.
|
|
|
|
| [22] |
尹奇跃, 赵美静, 倪晚成, 等. 兵棋推演的智能决策技术与挑战[J]. 自动化学报, 2023, 49(5): 913-928.
|
|
|
|
| [23] |
|
| [24] |
文东日. 深度强化学习在军事领域的应用研究[J]. 军事运筹与评估, 2022, 37(3): 75-80.
|
|
|
|
| [25] |
李航, 刘代金, 刘禹. 军事智能博弈对抗系统设计框架研究[J]. 火力与指挥控制, 2020, 45(9): 116-121.
|
|
|
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
陈彩辉, 姜汉龙. 任务空间概念模型(CMMS)研究[J]. 计算机仿真, 2005(9): 80-84.
|
|
|
|
| [30] |
张博, 康凤举, 苏冰. 一种面向论证仿真的舰艇作战系统任务空间概念模型[J]. 兵工学报, 2015, 36(增刊2): 112-117.
|
|
|
|
| [31] |
|
| [32] |
|
| [1] | SUN Hao, LI Haiqing, LIANG Yan, MA Chaoxiong, WU Han. Dynamic Penetration Decision of Loitering Munition Group Based on Knowledge-assisted Reinforcement Learning [J]. Acta Armamentarii, 2024, 45(9): 3161-3176. |
| [2] | CAO Zijian, SUN Zelong, YAN Guochuang, FU Yanfang, YANG Bo, LI Qinjie, LEI Kailin, GAO Linghang. Simulation of Reinforcement Learning-based UAV Swarm Adversarial Strategy Deduction [J]. Acta Armamentarii, 2023, 44(S2): 126-134. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||