
主管单位:中国科学技术协会
主办单位:中国兵工学会
ISSN 1000-1093 CN 11-2176/TJ
主办单位:中国兵工学会
ISSN 1000-1093 CN 11-2176/TJ
兵工学报 ›› 2025, Vol. 46 ›› Issue (3): 240251-.doi: 10.12382/bgxb.2024.0251
李传浩1, 明振军1,2,*( ), 王国新1,2, 阎艳1,2, 丁伟1, 万斯来1, 丁涛1,3
), 王国新1,2, 阎艳1,2, 丁伟1, 万斯来1, 丁涛1,3
收稿日期:2024-04-07
上线日期:2025-03-26
通讯作者:
基金资助:
LI Chuanhao1, MING Zhenjun1,2,*(), WANG Guoxin1,2, YAN Yan1,2, DING Wei1, WAN Silai1, DING Tao1,3
Received:2024-04-07
Online:2025-03-26
摘要:
无人平台箔条质心干扰是导弹末端防御的重要手段,其在平台机动和箔条发射等方面的智能决策能力是决定战略资产能否保护成功的重要因素。针对目前基于机理模型的计算分析和基于启发式算法的空间探索等决策方法存在的智能化程度低、适应能力差和决策速度慢等问题,提出基于多智能体深度强化学习的箔条干扰末端防御动态决策方法:对多平台协同进行箔条干扰末端防御的问题进行定义并构建仿真环境,建立导弹制导与引信模型、无人干扰平台机动模型、箔条扩散模型和质心干扰模型;将质心干扰决策问题转化为马尔科夫决策问题,构建决策智能体,定义状态、动作空间并设置奖励函数;通过多智能体近端策略优化算法对决策智能体进行训练。仿真结果显示,使用训练后的智能体进行决策,相比多智能体深度确定性策略梯度算法,训练时间减少了85.5%,资产保护成功率提升了3.84倍,相比遗传算法,决策时长减少了99.96%,资产保护成功率增加了1.12倍。
李传浩, 明振军, 王国新, 阎艳, 丁伟, 万斯来, 丁涛. 基于多智能体深度强化学习的无人平台箔条干扰末端防御动态决策方法[J]. 兵工学报, 2025, 46(3): 240251-.
LI Chuanhao, MING Zhenjun, WANG Guoxin, YAN Yan, DING Wei, WAN Silai, DING Tao. Dynamic Decision-making Method of Unmanned Platform Chaff Jamming for Terminal Defense Based on Multi-agent Deep Reinforcement Learning[J]. Acta Armamentarii, 2025, 46(3): 240251-.

图1 多无人平台箔条末端防御示意图
Fig.1 Schematic diagram of multi-platform chaff terminal defense

图2 多平台箔条末端防御模型组成
Fig.2 Composition of multi-platform chaff terminal defense model

图3 导弹目标相对运动关系
Fig.3 Relative motion relationship of missile and target
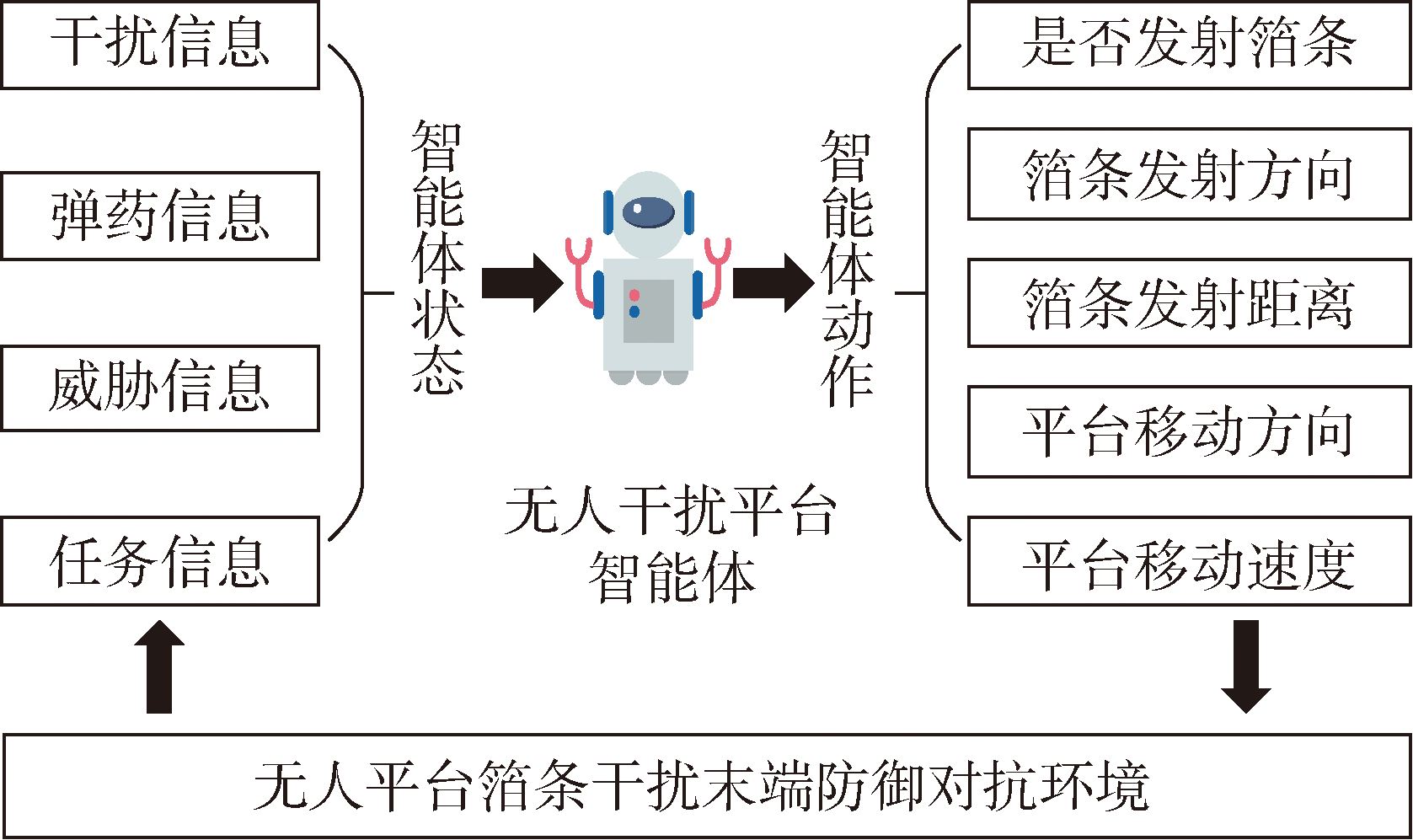
图4 箔条干扰末端防御智能体运行流程
Fig.4 Operation flow of chaff jamming terminal defense agent
| 状态类型 | 状态名称 | 状态标识 | 维度 | 取值范围 | |
|---|---|---|---|---|---|
| 威胁信息 | 导弹位置坐标/m | Nmis×2 | [Xmin,Xmax]×[Ymin,Ymax] | ||
| 导弹方向坐标/rad | Nmis | [-πrad,πrad) | |||
| 导弹机动速率/(m·s-1) | Nmis | [0, ] | |||
| 导弹跟踪时长/s | Nmis | [0,Tmax) | |||
| 弹药信息 | 箔条状态矩阵/m | ×3 | [Xmin,Xmax]×[Ymin,Ymax]×[0,k] | ||
| 箔条弹剩余数量 | Nplat | {0,1…, } | |||
| 无人干扰 平台信息 | 位置坐标/m | 2 | [Xmin,Xmax]×[Ymin,Ymax] | ||
| 方向坐标/rad | 1 | [-πrad,πrad) | |||
| 速率值/(m·s-1) | 1 | [0, ] | |||
| 任务信息 | 资产位置/m | Nmis×2 | [Xmin,Xmax]×[Ymin,Ymax] | ||
| 资产威胁距离/m | Nmis | [0, ] | |||
表1 干扰决策状态空间表示
Table 1 Representation of jamming decision state space
| 状态类型 | 状态名称 | 状态标识 | 维度 | 取值范围 | |
|---|---|---|---|---|---|
| 威胁信息 | 导弹位置坐标/m | Nmis×2 | [Xmin,Xmax]×[Ymin,Ymax] | ||
| 导弹方向坐标/rad | Nmis | [-πrad,πrad) | |||
| 导弹机动速率/(m·s-1) | Nmis | [0, ] | |||
| 导弹跟踪时长/s | Nmis | [0,Tmax) | |||
| 弹药信息 | 箔条状态矩阵/m | ×3 | [Xmin,Xmax]×[Ymin,Ymax]×[0,k] | ||
| 箔条弹剩余数量 | Nplat | {0,1…, } | |||
| 无人干扰 平台信息 | 位置坐标/m | 2 | [Xmin,Xmax]×[Ymin,Ymax] | ||
| 方向坐标/rad | 1 | [-πrad,πrad) | |||
| 速率值/(m·s-1) | 1 | [0, ] | |||
| 任务信息 | 资产位置/m | Nmis×2 | [Xmin,Xmax]×[Ymin,Ymax] | ||
| 资产威胁距离/m | Nmis | [0, ] | |||
| 动作类型 | 动作名称 | 动作标识 | 取值范围 |
|---|---|---|---|
| 弹药动作 | 是否发射箔条 | {0,1} | |
| 箔条发射方向/rad | [-πrad,πrad) | ||
| 箔条发射距离/m | [0, ] | ||
| 无人干扰 平台信息 | 平台移动方向/rad | [-πrad,πrad) | |
| 平台移动速度/(m·s-1) | [0, ] |
表2 干扰决策动作空间表示
Table 2 Representation of jamming decision action space
| 动作类型 | 动作名称 | 动作标识 | 取值范围 |
|---|---|---|---|
| 弹药动作 | 是否发射箔条 | {0,1} | |
| 箔条发射方向/rad | [-πrad,πrad) | ||
| 箔条发射距离/m | [0, ] | ||
| 无人干扰 平台信息 | 平台移动方向/rad | [-πrad,πrad) | |
| 平台移动速度/(m·s-1) | [0, ] |

图5 MAPPO算法训练框架图
Fig.5 MAPPO algorithm training framework
| 阵营 | 性能参数 | 标识 | 取值 |
|---|---|---|---|
| 蓝方 | 导弹近炸距离/m | Lfuse | 60 |
| 导弹比例导引系数 | K | 5 | |
| 导弹机动速率/(m·s-1) | vmis | 150 | |
| 导弹最大角速度/(rad·s-1) | π/6 | ||
| 资产雷达反射截面积/m2 | σa | 5000 | |
| 红方 | 资产引爆点安全距离/m | 60 | |
| 无人干扰平台最大速率/(m·s-1) | 20 | ||
| 无人干扰平台最大角速度/(rad·s-1) | π/3 | ||
| 无人干扰平台最大加速度/(m·s-2) | 5 | ||
| 箔条云持续时间/s | 2 | ||
| 箔条最大发射距离/m | 10 | ||
| 箔条武器装填量 | 5 | ||
| 箔条最大反射截面积/m2 | k | 1000 |
表3 仿真双方性能参数
Table 3 Performance parameters of red and blue forces equipment
| 阵营 | 性能参数 | 标识 | 取值 |
|---|---|---|---|
| 蓝方 | 导弹近炸距离/m | Lfuse | 60 |
| 导弹比例导引系数 | K | 5 | |
| 导弹机动速率/(m·s-1) | vmis | 150 | |
| 导弹最大角速度/(rad·s-1) | π/6 | ||
| 资产雷达反射截面积/m2 | σa | 5000 | |
| 红方 | 资产引爆点安全距离/m | 60 | |
| 无人干扰平台最大速率/(m·s-1) | 20 | ||
| 无人干扰平台最大角速度/(rad·s-1) | π/3 | ||
| 无人干扰平台最大加速度/(m·s-2) | 5 | ||
| 箔条云持续时间/s | 2 | ||
| 箔条最大发射距离/m | 10 | ||
| 箔条武器装填量 | 5 | ||
| 箔条最大反射截面积/m2 | k | 1000 |
| 参数 | 标识 | 数值 |
|---|---|---|
| 策略网络学习率 | α | 5×10-4 |
| 价值网络学习率 | β | 5×10-4 |
| 最大迭代步数 | stepmax | 3×105 |
| 数据缓冲区容量 | B | 5 |
| 评估测试间隔 | Tite | 50 |
| 每轮最大步数 | Tmax | 30 |
| 连续更新次数 | K | 5 |
| 截断参数 | ε | 0.2 |
| 策略熵系数 | φ | 0.01 |
| 折扣因子 | γ | 0.999 |
| GAE参数 | λ | 0.95 |
| 策略/价值网络层数 | Nlayer | 4 |
| 隐藏层神经元个数 | Nhidden | 64 |
| 测试环境个数 | Nenv | 100 |
表4 MAPPO算法中的参数取值
Table 4 Value of parameters in MAPPO algorithm
| 参数 | 标识 | 数值 |
|---|---|---|
| 策略网络学习率 | α | 5×10-4 |
| 价值网络学习率 | β | 5×10-4 |
| 最大迭代步数 | stepmax | 3×105 |
| 数据缓冲区容量 | B | 5 |
| 评估测试间隔 | Tite | 50 |
| 每轮最大步数 | Tmax | 30 |
| 连续更新次数 | K | 5 |
| 截断参数 | ε | 0.2 |
| 策略熵系数 | φ | 0.01 |
| 折扣因子 | γ | 0.999 |
| GAE参数 | λ | 0.95 |
| 策略/价值网络层数 | Nlayer | 4 |
| 隐藏层神经元个数 | Nhidden | 64 |
| 测试环境个数 | Nenv | 100 |
| 环境 序号 | 资产位置/m | 车辆方向/ rad | 导弹位置/m |
|---|---|---|---|
| 1 | |||
| 2 | |||
| ︙ | ︙ | ︙ | ︙ |
| 100 |
表5 测试环境参数
Table 5 Test environment parameters
| 环境 序号 | 资产位置/m | 车辆方向/ rad | 导弹位置/m |
|---|---|---|---|
| 1 | |||
| 2 | |||
| ︙ | ︙ | ︙ | ︙ |
| 100 |

图6 每个仿真步数平均累积奖励值曲线
Fig.6 Average cumulative reward value curve for each training cycle

图7 每个仿真步数平均保护成功率曲线
Fig.7 Average protection success rate curve of each training cycle

图8 训练后的多智能体末端防御仿真流程
Fig.8 The multi-agent terminal defense simulation process after training

图9 单次仿真中资产威胁距离的变化
Fig.9 The change in dfistance of asset from threat in a single simulation
| 算法 | 训练时长/s | 平均每轮决 策时长/s | 平均成功率 | 平均最小资产威胁距离/m | ||||
|---|---|---|---|---|---|---|---|---|
| 资产1 | 资产2 | 资产3 | 资产1 | 资产2 | 资产3 | |||
| MAPPO算法 | 2763.07 | 0.063277 | 0.75 | 0.85 | 0.77 | 85.27 | 108.75 | 91.63 |
| MADDPG算法(1000) | 19102.6 | 0.022671 | 0.18 | 0.22 | 0.01 | 34.14 | 33.18 | 13.20 |
| MADDPG算法(10000) | 35916.8 | 0.020543 | 0.09 | 0.20 | 0.15 | 26.36 | 32.23 | 26.33 |
| MADDPG算法(100000) | 28220.1 | 0.017842 | 0.07 | 0.16 | 0.26 | 29.35 | 37.57 | 39.71 |
| GA | 148.68 | 0.49 | 0.49 | 0.14 | 71.98 | 67.45 | 27.08 | |
表6 末端防御性能对比结果
Table 6 Comparison results of terminal defense performances
| 算法 | 训练时长/s | 平均每轮决 策时长/s | 平均成功率 | 平均最小资产威胁距离/m | ||||
|---|---|---|---|---|---|---|---|---|
| 资产1 | 资产2 | 资产3 | 资产1 | 资产2 | 资产3 | |||
| MAPPO算法 | 2763.07 | 0.063277 | 0.75 | 0.85 | 0.77 | 85.27 | 108.75 | 91.63 |
| MADDPG算法(1000) | 19102.6 | 0.022671 | 0.18 | 0.22 | 0.01 | 34.14 | 33.18 | 13.20 |
| MADDPG算法(10000) | 35916.8 | 0.020543 | 0.09 | 0.20 | 0.15 | 26.36 | 32.23 | 26.33 |
| MADDPG算法(100000) | 28220.1 | 0.017842 | 0.07 | 0.16 | 0.26 | 29.35 | 37.57 | 39.71 |
| GA | 148.68 | 0.49 | 0.49 | 0.14 | 71.98 | 67.45 | 27.08 | |

图10 MAPPO和MADDPG算法资产保护成功率的变化
Fig.10 Changes in the success rates of asset protection of agent trained by MAPPO and MADDPG algorithm

图11 GA效果和决策用时随优化代数的变化曲线
Fig.11 Variation of effect and decision time of GA with optimization generation

图12 智能体奖励设置对算法收敛过程的影响
Fig.12 The influence of agent reward setting on the convergence process of the algorithm
| [1] |
张继传, 王声才. 现代末端防御武器系统探析[J]. 火力与指挥控制, 2008, 33(增刊1):41-43.
|
|
|
|
| [2] |
|
| [3] |
赵玲, 刘正敏, 姜长生. 末端防御系统中的对抗决策方法研究[J]. 宇航学报, 2011, 32(3):574-581.
|
|
|
|
| [4] |
张成, 吴新良, 张博, 等. 面向机载末端防御的导弹威胁信息融合与识别方法[J]. 现代雷达, 2022, 45(8):1-8.
|
|
|
|
| [5] |
|
| [6] |
全斯农, 范晖, 代大海, 等. 一种基于精细极化目标分解的舰船箔条云识别方法[J]. 雷达学报, 2021, 10(1):61-73.
|
|
|
|
| [7] |
陈静. 雷达箔条干扰原理[M]. 北京: 国防工业出版社, 2007.
|
|
|
|
| [8] |
李永祯, 刘业民, 庞晨, 等. 基于分层极化特性的箔条云识别方法[J]. 系统工程与电子技术, 2021, 43(8):2099-2107.
doi: 10.12305/j.issn.1001-506X.2021.08.10 |
|
doi: 10.12305/j.issn.1001-506X.2021.08.10 |
|
| [9] |
唐波, 鲁嘉淇, 郭琨毅, 等. 针对时空统计特性的箔条云半实物射频仿真[J]. 电子学报, 2023, 51(4):843-849.
doi: 10.12263/DZXB.20211282 |
|
doi: 10.12263/DZXB.20211282 |
|
| [10] |
王湖升, 陈伯孝, 叶倾知. 基于箔条干扰实测数据的对抗方法研究[J]. 系统工程与电子技术, 2023, 45(7):2010-2021.
doi: 10.12305/j.issn.1001-506X.2023.07.11 |
|
|
|
| [11] |
刘业民, 李永祯, 黄大通, 等. 基于极化单脉冲雷达扩展目标角度估计方法[J]. 系统工程与电子技术, 2021, 43(6):1497-1505.
doi: 10.12305/j.issn.1001-506X.2021.06.06 |
|
doi: 10.12305/j.issn.1001-506X.2021.06.06 |
|
| [12] |
张凯娜, 吴上, 张军周. 对抗新型反舰导弹箔条质心干扰策略研究[J]. 舰船电子工程, 2021, 41(11):64-68.
|
|
|
|
| [13] |
白杨, 张成, 王博宇, 等. 机载末端红外对抗作战效能仿真研究[J]. 红外与激光工程, 2022, 51(11):149-158.
|
|
|
|
| [14] |
刘赟, 张翠侠, 颜如祥, 等. 空间箔条有效抛撒时间区间确定和策略研究[J]. 兵工学报, 2015, 36(7):1302-1308.
doi: 10.3969/j.issn.1000-1093.2015.07.020 |
|
doi: 10.3969/j.issn.1000-1093.2015.07.020 |
|
| [15] |
周中良, 程越, 阮铖巍, 等. 空战机动规避与箔条干扰协同应用策略[J]. 西安电子科技大学学报, 2017, 44(5):153-157,164.
|
|
|
|
| [16] |
杨勇, 李亚南. 箔条弹的投放决策研究[J]. 雷达科学与技术, 2016, 14(5):466-470.
|
|
|
|
| [17] |
彭绍荣, 胡生亮, 许江湖, 等. “箔条链”式舰艇反导质心干扰作战方法研究[J]. 现代防御技术, 2022, 50(3):78-83.
doi: 10.3969/j.issn.1009-086x.2022.03.010 |
|
|
|
| [18] |
雷震烁, 刘松涛, 姜宁, 等. 舰艇箔条冲淡干扰发射时机模型研究[J]. 火力与指挥控制, 2021, 46(3):16-19.
|
|
|
|
| [19] |
裴立冠, 刘经东, 马春波. 基于灰狼算法的箔条幕干扰构设方法研究[J]. 系统工程与电子技术, 2023, 46(2):1-13.
|
|
|
|
| [20] |
裴立冠, 周唯, 刘经东. 基于布谷鸟搜索算法的机动化箔条幕布放方法研究[J]. 系统工程与电子技术, 2023, 46(3):1-13.
|
|
|
|
| [21] |
蔡蒨, 张为华. 箔条配比优化仿真分析[J]. 舰船电子工程, 2015, 35(5):77-79,88.
|
|
|
|
| [22] |
王晴昊, 姚登凯, 赵顾颢, 等. 远距离支援复合干扰空域规划研究[J]. 西北工业大学学报, 2018, 36(6):1176-1184.
|
|
|
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
丁世飞, 杜威, 张健, 等. 多智能体深度强化学习研究进展[J]. 计算机学报, 2024, 47(7):1347-1567.
|
|
|
|
| [27] |
葛致磊, 王红梅, 王佩, 等. 导弹导引系统原理[M]. 北京: 国防工业出版社, 2016.
|
|
|
|
| [28] |
张合, 李豪杰. 引信机构学[M]. 北京: 北京理工大学出版社, 2007.
|
|
|
|
| [29] |
尹建平, 王志军. 弹药学[M] .第3版. 北京: 北京理工大学出版社, 2018.
|
|
|
|
| [30] |
方良, 郝建滨, 朱璐, 等. 基于对抗反舰导弹的箔条质心干扰建模与仿真研究[J]. 兵器装备工程学报, 2019, 40(2):59-61.
|
|
|
|
| [31] |
白岚, 王科. 机载箔条干扰弹投放时机的仿真研究[J]. 舰船电子工程, 2012, 32(12):85-87.
|
|
|
|
| [32] |
|
| [1] | 肖扬, 苏波, 纪超, 杨德真, 周桐. 基于STPA和Bow-Tie模型的地面无人平台系统安全分析方法[J]. 兵工学报, 2024, 45(S2): 153-161. |
| [2] | 娄抒瀚, 王冲冲, 龚炜, 邓立原, 李莉. 基于MLAT-DRL算法的协同区域信息采集策略[J]. 兵工学报, 2024, 45(12): 4423-4434. |
| [3] | 赵熙俊, 崔星, 李兆冬, 王一全, 杨雨. 编队机动自适应车间距保持控制[J]. 兵工学报, 2023, 44(S2): 44-51. |
| [4] | 陈亚萍, 王楠, 洪华杰, 刘召阳, 闫响达. 面向多无人平台区域监视任务的信息素正向激励栅格方法[J]. 兵工学报, 2023, 44(9): 2859-2870. |
| [5] | 贾金伟, 韩壮志, 刘利民, 解辉. 基于余弦-指数非线性混沌映射的射频隐身抗分选信号设计技术[J]. 兵工学报, 2023, 44(6): 1846-1857. |
| [6] | 熊光明, 于全富, 胡秀中, 周子杰, 许佳慧. 考虑平台特性的多层建筑物内履带式无人平台运动规划[J]. 兵工学报, 2023, 44(3): 841-850. |
| [7] | 李佳键, 史彦军, 杨雨, 李波, 赵熙俊. 无人集群作战任务的多智能体强化学习卸载决策[J]. 兵工学报, 2023, 44(11): 3295-3309. |
| [8] | 彭博, 陈齐乐, 李锐. 基于变分正则化参数估计的伪码调相引信重构式干扰方法[J]. 兵工学报, 2023, 44(10): 3127-3136. |
| [9] | 乔彩霞, 郝新红, 陈齐乐, 孔志杰, 王雄武. 基于相关旁瓣平均的混沌码与线性调频复合调制无线电引信抗数字射频存储干扰方法[J]. 兵工学报, 2020, 41(4): 641-648. |
| [10] | 邹渊, 焦飞翔, 崔星, 张旭东, 张彬. 地面无人平台动力源集成技术发展综述[J]. 兵工学报, 2020, 41(10): 2131-2144. |
| [11] | 刘忠泽, 陈慧岩, 崔星, 熊光明, 王羽纯, 陶溢. 无人平台越野环境下同步定位与地图创建[J]. 兵工学报, 2019, 40(12): 2399-2406. |
| [12] | 张仲敏, 李俊山, 宋凭2, 严其飞. 一种基于模糊层次分析的多Agent电子对抗装备状态智能评判方法[J]. 兵工学报, 2014, 35(4): 516-522. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
 京公网安备11010802024360号 京ICP备05059581号-4
京公网安备11010802024360号 京ICP备05059581号-4