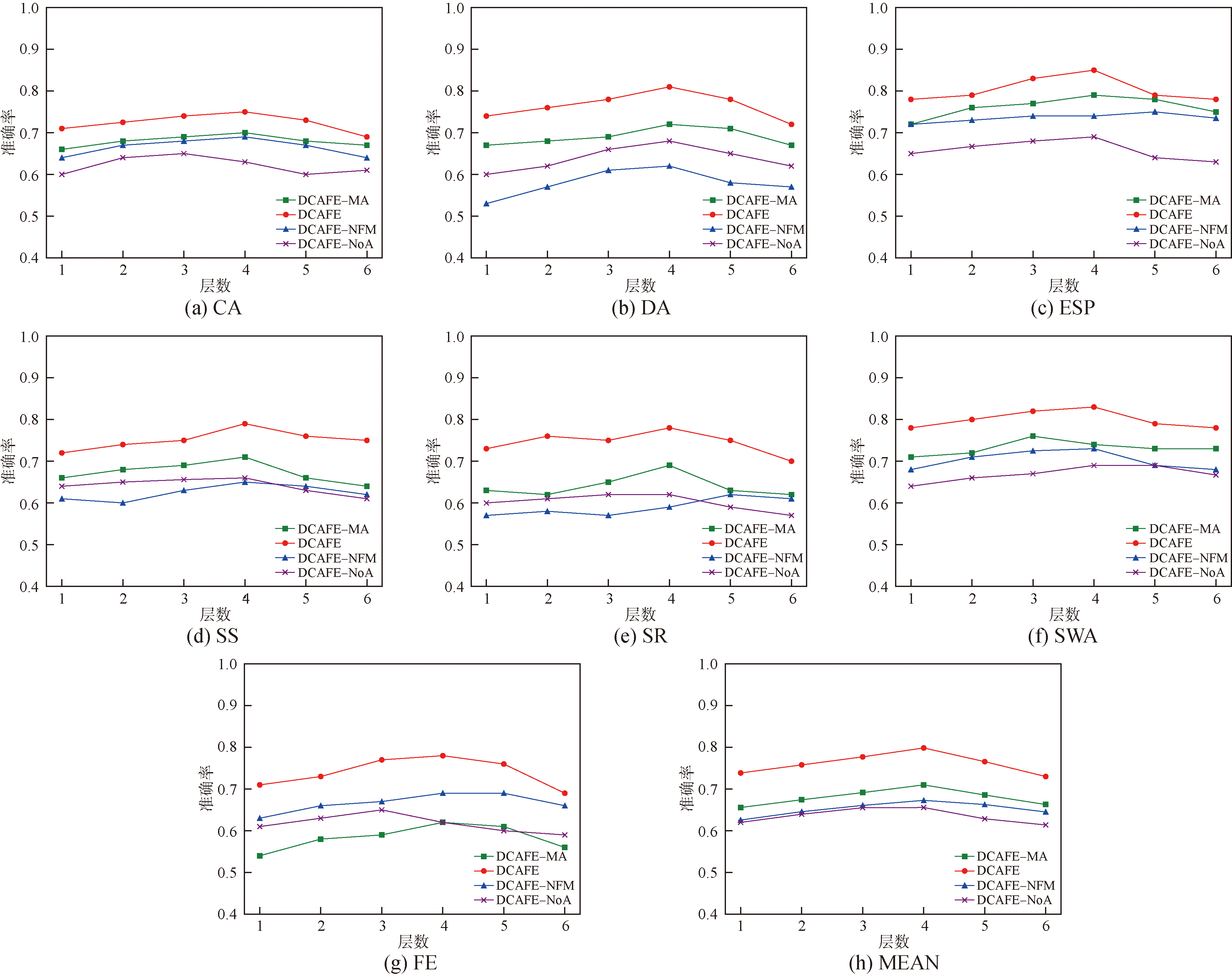
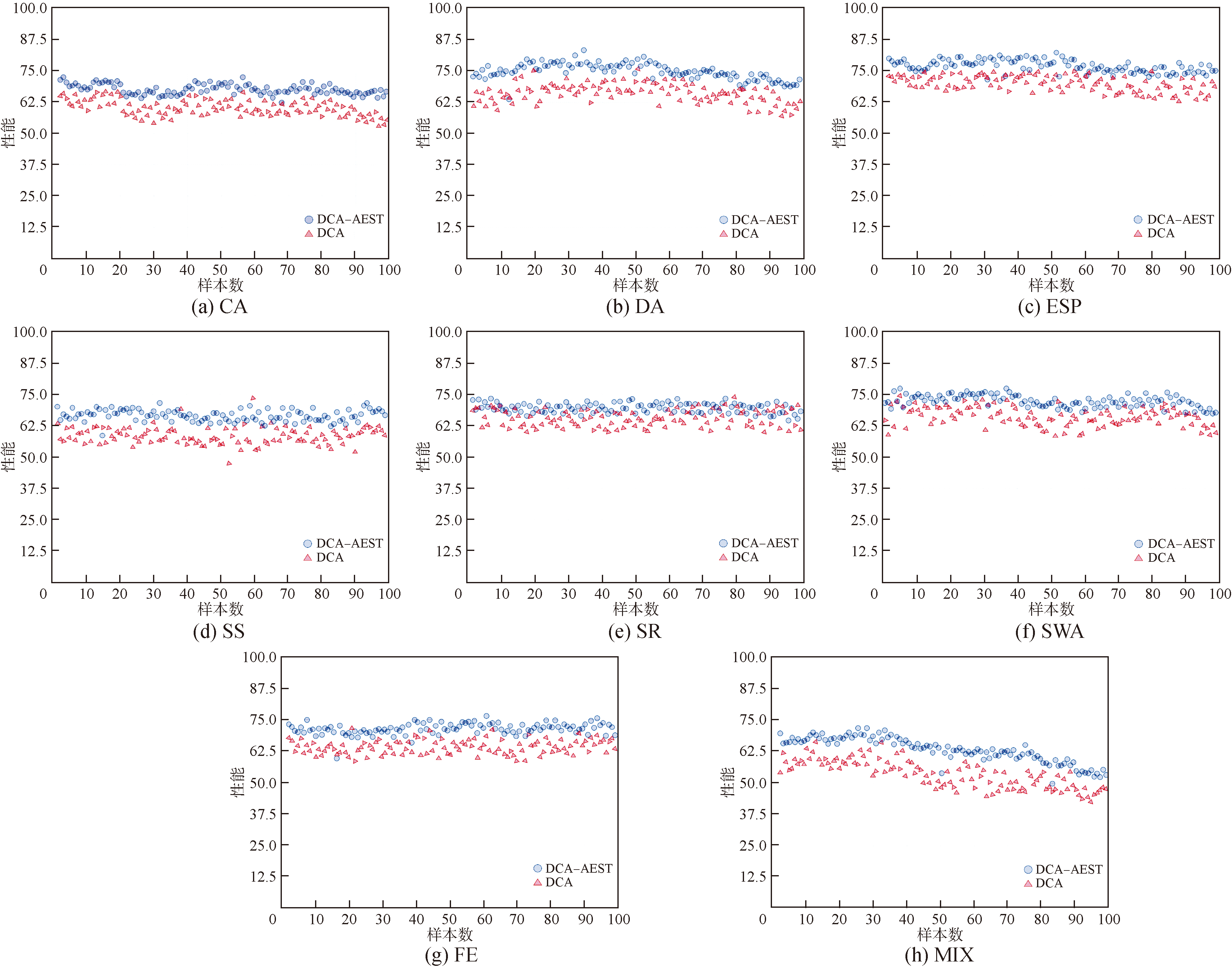
| [4] |
MA S D, ZHANG H Z, YANG G Q. Target threat level assessment based on cloud model under fuzzy and uncertain conditions in air combat simulation[J]. Aerospace Science and Technology, 2017, 67:49-53.
|
| [5] |
LIU C, SUN S S, TAO C G, et al. Sliding mode control of multi-agent system with application to UAV air combat[J]. Computers & Electrical Engineering, 2021, 96:107491.
|
| [6] |
VIRTANEN K, KARELAHTI J, RAIVIO T. Modeling air combat by a moving horizon influence diagram game[J]. Journal of Guidance,Control,and Dynamics, 2006, 29(5):1080-1091.
|
| [7] |
张军, 李卫红. 基于改进贝叶斯网络的无人机空对地作战威胁评估[J]. 西北工业大学学报, 2023, 41(6):1054-1063.
|
|
ZHANG J, LI W H. Threat assessment for air-to-ground combat of UAVs using improved Bayesian networks[J]. Journal of Northwestern Polytechnical University, 2023, 41(6):1054-1063. (in Chinese)
|
| [8] |
FAN Z H, XU Y, KANG Y H, Air combat maneuver decision method based on A3C deep reinforcement learning[J]. Machines, 2022, 10(11):1033.
|
| [9] |
MURASOV R K, KURTSEITOV T L, CHUMACHENKO S M, Threat assessment mathematical model for potentially dangerous objects of critical infrastructure in the combat zone[J]. Problems in Programming, 2022,3-4:446-454.
|
| [10] |
CAO Y, KOU Y X, XU A, Target threat assessment in air combat based on improved glowworm swarm optimization and ELM neural network[J]. International Journal of Aerospace Engineering, 2021 ( 2021-10-06).DOI: 10.1155/2021/4687167.
|
| [11] |
XU X M, YANG R N, YU Y. Threat assessment in air combat based on ELM neural network[C]// Proceedngs of 2019 IEEE International Conference on Artificial Intelligence and Computer Applications.Dalian, China:IEEE,2019:114-120.
|
| [12] |
KONG D P, CHANG T Q, Wang Q D, et al. A threat assessment method of group targets based on interval-valued intuitionistic fuzzy multi-attribute group decision-making[J]. Applied Soft Computing, 2018, 67:350-369.
|
| [1] |
BEN-BASSAT M, FREEDY A. Knowledge requirements and management in expert decision support systems for (military) situation assessment[J]. IEEE Transactions on Systems,Man,and Cybernetics, 1982, 12(4):479-490.
|
| [2] |
COHEN M S. A cognitive framework for battlefield commanders' situation assessment[M].Washington,US:U.S.Army Research Institute for the Behavioral and Social Sciences, 1994.
|
| [3] |
XU X M, YANG R N, FU Y. Situation assessment for air combat based on novel semi-supervised naive Bayes[J]. Journal of Systems Engineering and Electronics, 2018, 29(4):768-779.
doi: 10.21629/JSEE.2018.04.11
|
| [13] |
HAARNOJA T, ZHOU A, HARTIKAINEN K, et al. Soft actor-critic algorithms and applications[Z].arXiv:1812.05905,2018.
|
| [14] |
ZHANG Q, HU J H, FENG J F, et al. Air multi-target threat assessment method based on improved GGIFSS[J]. Journal of Intelligent & Fuzzy Systems, 2019, 36(5):4127-4139.
|
| [15] |
DENG Y. A threat assessment model under uncertain environment[J/OL]. Mathematical Problems in Engineering, 2015(2015-08-26). https://doi.org/10.1155/2015/878024.
|
| [16] |
LIEBHABER M J, FEHER B. Air threat assessment:Research,model,and display guidelines[C]// Proceedings of the 2002 Command and Control Research and Technology Symposium.2002:90-93.
|
| [17] |
XU Y J, WANG Y C, MIU X D. Multi-attribute decision-making method for air target threat evaluation based on intuitionistic fuzzy sets[J]. Journal of Systems Engineering and Electronics, 2012, 23(6):891-897.
|
| [18] |
AZIMIRAD E, HADDADNIA J. Target threat assessment using fuzzy sets theory[J]. International Journal of Advances in Intelligent Informatics, 2015, 1(2):57-74.
|
| [19] |
ZHANG K, KONG W R, LIU P P, et al. Assessment and sequencing of air target threat based on intuitionistic fuzzy entropy and dynamic VIKOR[J]. Journal of Systems Engineering and Electronics, 2018, 29(2):305-310.
doi: 10.21629/JSEE.2018.02.11
|
| [20] |
GAO Y, LI D S, ZHONG H. A novel target threat assessment method based on three-way decisions under intuitionistic fuzzy multi-attribute decision-making environment[J]. Engineering Applications of Artificial Intelligence, 2020, 87:103276.
|
| [21] |
JOHANSSON F, FALKMAN G. A Bayesian network approach to threat evaluation with application to an air defense scenario[C]// Proceedings of 2008 11th International Conference on Information Fusion.Cologne, Germany:IEEE,2008:1-7.
|
| [22] |
YUN J S, CHOI B, HAN M M, et al. Air threat evaluation system using fuzzy-Bayesian network based on information fusion[J]. Journal of Internet Computing and Services, 2012, 13(5):21-31.
|
| [23] |
TENG F, SONG Y F, GUO X P. Attention-TCN-BiGRU:An air target combat intention recognition model[J]. Mathematics, 2021, 9(19):2412.
|
| [24] |
CHEN C, QUAN W, SHAO Z. Aerial target threat assessment based on gated recurrent unit and self-attention mechanism[J]. Journal of Systems Engineering and Electronics, 2024, 35(2):361-373.
doi: 10.23919/JSEE.2023.000116
|
| [25] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[J]. Advances in Neural Information Processing Systems, 2017, 30:1-11.
|
| [26] |
YANG Z C, YANG D Y, DYER C, et al. Hierarchical attention networks for document classification[C]//Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies.San Diego,California, US: Association for Computational Linguistics,2016:1480-1489.
|
| [27] |
WANG R X, FU B, FU G, et al. Deep & cross network for ad click predictions[C]// Proceedings of the ADKDD’17.New York, US: Association for Computing Machinery,2017:1-7.
|
| [28] |
DEVLIN J, CHANG M-W, LEE K, et al. BERT:Pre-training of deep bidirectional transformers for language understanding[Z].arXiv:1810.04805,2018.
|
| [29] |
Kim Y, Rush A M.Sequence-level knowledge distillation[Z].arXiv:1606.07947,2016.
|
| [30] |
ZHAO B R, CUI Q, SONG R J, et al. Decoupled knowledge distillation[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans,LA, US:IEEE,2022:11953-11962.
|
| [31] |
GOU J P, YU B S, MAYBANK S J, et al. Knowledge distillation:A survey[J]. International Journal of Computer Vision, 2021, 129(6):1789-1819.
|
| [32] |
KONDA V R, TSITSIKLIS J N. Actor-critic algorithms[J]. Advances in Neural Information Processing Systems, 1999, 12:1008-1014.
|
| [33] |
NG A Y, RUSSELL S. Algorithms for inverse reinforcement learning[C]// Proceedings of the Seventeenth International Conference on Machine Learning,Stanford,CA, US:ICML,2000:663-670.
|
| [34] |
ARORA S, DOSHI P. A survey of inverse reinforcement learning:Challenges,methods and progress[J]. Artificial Intelligence, 2021, 297:103500.
|
| [35] |
YANG H Y, HAN C, TU C L. Air targets threat assessment based on BP-BN[J]. Journal of Communications, 2018, 13(1):21-26.
|
| [36] |
FENG J F, ZHANG Q, HU J H, et al. Dynamic assessment method of air target threat based on improved GIFSS[J]. Journal of Systems Engineering and Electronics, 2019, 30(3):525-534.
doi: 10.21629/JSEE.2019.03.10
|
| [37] |
DI R H, GAO X G, GUO Z G, et al. A threat assessment method for unmanned aerial vehicle based on Bayesian networks under the condition of small data sets[J]. Mathematical Problems in Engineering, 2018(1):8484358.
|
| [38] |
LIU X Y, WAN Y Y, JIA M, et al. Facilitating the high voltage stability of NFM via transition metal slabs high-entropy configuration strategy[J]. Energy Storage Materials, 2024, 67:103313.
|

 ), 李博1, 王柯新1, 刘建成1, 卫思雯3,**(
), 李博1, 王柯新1, 刘建成1, 卫思雯3,**( 京公网安备11010802024360号 京ICP备05059581号-4
京公网安备11010802024360号 京ICP备05059581号-4